أصدر فريق أبحاث الذكاء الاصطناعي التابع لشركة Apple جيلًا جديدًا من عائلة نماذج اللغات الكبيرة متعددة الوسائط MM1.5، والتي يمكنها دمج أنواع بيانات متعددة مثل النصوص والصور، وقد أظهرت أداءً قويًا في مهام مثل الإجابة على الأسئلة المرئية وتوليد الصور والإجابة على الأسئلة المتعددة. القدرة على تفسير البيانات مشروط. يتغلب MM1.5 على صعوبات النماذج متعددة الوسائط السابقة في معالجة الصور الغنية بالنصوص والمهام المرئية الدقيقة، من خلال نهج مبتكر يركز على البيانات، ويستخدم بيانات التعرف الضوئي على الحروف عالية الدقة وأوصاف الصور الاصطناعية لتحسين أداء النموذج بشكل ملحوظ. . فهم. سيمنحك محرر Downcodes فهمًا متعمقًا لابتكارات MM1.5 وأدائها الممتاز في اختبارات قياس الأداء المتعددة.
أطلق فريق أبحاث الذكاء الاصطناعي التابع لشركة Apple مؤخرًا جيلًا جديدًا من عائلة نماذج اللغات الكبيرة متعددة الوسائط (MLLMs) - MM1.5. يمكن لهذه السلسلة من النماذج أن تجمع بين أنواع بيانات متعددة مثل النصوص والصور، مما يوضح لنا قدرة الذكاء الاصطناعي الجديدة على فهم المهام المعقدة. يمكن حل المهام مثل الإجابة على الأسئلة المرئية وتوليد الصور وتفسير البيانات متعددة الوسائط بشكل أفضل بمساعدة هذه النماذج.
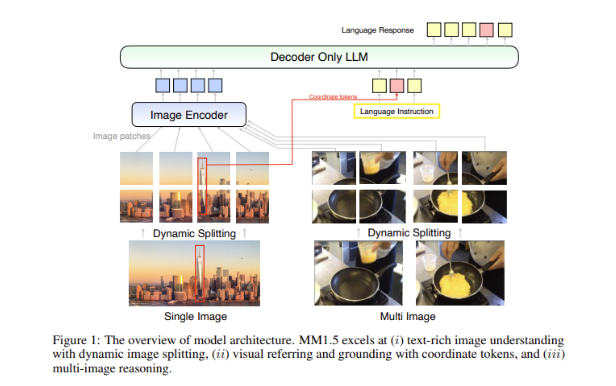
التحدي الكبير في النماذج متعددة الوسائط هو كيفية تحقيق التفاعل الفعال بين أنواع البيانات المختلفة. غالبًا ما واجهت النماذج السابقة صعوبة في التعامل مع الصور الغنية بالنصوص أو مهام الرؤية الدقيقة. ولذلك، قدم فريق بحث Apple طريقة مبتكرة تركز على البيانات في نموذج MM1.5، باستخدام بيانات التعرف الضوئي على الحروف عالية الدقة وأوصاف الصور الاصطناعية لتعزيز قدرات فهم النموذج.
لا تمكن هذه الطريقة MM1.5 من تجاوز النماذج السابقة في الفهم البصري ومهام تحديد الموقع فحسب، بل تطلق أيضًا نسختين متخصصتين من النموذج: MM1.5-Video وMM1.5-UI، اللتين تستخدمان لفهم الفيديو وتحديد موضعه على التوالي. تحليل واجهة المحمول .
ينقسم تدريب نموذج MM1.5 إلى ثلاث مراحل رئيسية.
المرحلة الأولى عبارة عن تدريب مسبق واسع النطاق، باستخدام 2 مليار زوج من بيانات الصور والنص، و600 مليون مستند نصي مصور مشذّب، و2 تريليون رمز نصي فقط.
وتتمثل المرحلة الثانية في مواصلة تحسين أداء مهام الصور الغنية بالنص من خلال التدريب المسبق المستمر لـ 45 مليون بيانات التعرف الضوئي على الحروف عالية الجودة و7 ملايين وصف تركيبي.
أخيرًا، في مرحلة الضبط الدقيق الخاضعة للإشراف، يتم تحسين النموذج باستخدام بيانات صورة واحدة ومتعددة الصور ونص فقط تم اختيارها بعناية لجعله أفضل في المرجع البصري التفصيلي والاستدلال متعدد الصور.
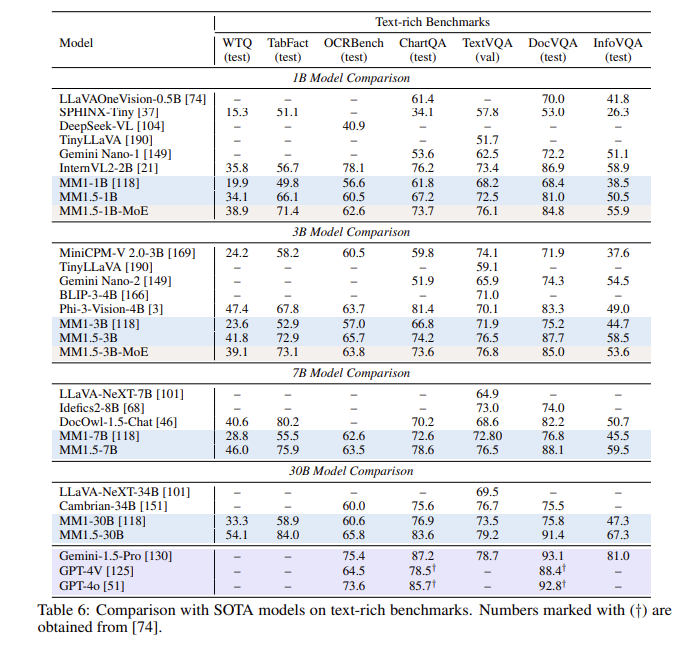
وبعد سلسلة من التقييمات، حقق نموذج MM1.5 أداءً جيدًا في اختبارات قياس الأداء المتعددة، خاصة عند التعامل مع فهم الصور الغنية بالنصوص، مع تحسن بمقدار 1.4 نقطة عن النموذج السابق. بالإضافة إلى ذلك، حتى MM1.5-Video، المصمم خصيصًا لفهم الفيديو، قد وصل إلى المستوى الرائد في المهام ذات الصلة بفضل إمكاناته القوية متعددة الوسائط.
لا تضع عائلة طرازات MM1.5 معيارًا جديدًا لنماذج اللغات الكبيرة متعددة الوسائط فحسب، بل تُظهر أيضًا إمكاناتها في مجموعة متنوعة من التطبيقات، بدءًا من الفهم العام لنصوص الصور وحتى تحليل واجهة الفيديو والفيديو، وكل ذلك بأداء متميز.
تسليط الضوء على:
**متغيرات النماذج**: تتضمن نماذج كثيفة ونماذج وزارة التربية والتعليم بمعلمات تتراوح من 1 مليار إلى 30 مليارًا، مما يضمن قابلية التوسع والنشر المرن.
** بيانات التدريب **: استخدام 2 مليار زوج من الصور والنص، و600 مليون مستند نصي مصور مشذّب، و2 تريليون رمز نصي فقط.
**تحسين الأداء**: في اختبار قياس الأداء الذي يركز على فهم الصور الغنية بالنصوص، تم تحقيق تحسن بمقدار 1.4 نقطة مقارنة بالنموذج السابق.
بشكل عام، حققت عائلة طرازات MM1.5 من Apple تقدمًا كبيرًا في مجال نماذج اللغات الكبيرة متعددة الوسائط، وتوفر أساليبها المبتكرة وأدائها الممتاز اتجاهًا جديدًا لتطوير الذكاء الاصطناعي في المستقبل. ونحن نتطلع إلى إظهار MM1.5 إمكاناته في المزيد من سيناريوهات التطبيق.