في السنوات الأخيرة، حقق نموذج المحول وآلية الانتباه الخاصة به تقدمًا كبيرًا في مجال نماذج اللغات الكبيرة (LLM)، لكن مشكلة التعرض للتداخل من المعلومات غير ذات الصلة كانت موجودة دائمًا. سيقوم محرر Downcodes بتفسير أحدث ورقة لك، والتي تقترح نموذجًا جديدًا يسمى المحول التفاضلي (DIFF Transformer)، والذي يهدف إلى حل مشكلة ضجيج الانتباه في نموذج Transformer وتحسين كفاءة النموذج ودقته. يقوم النموذج بتصفية المعلومات غير ذات الصلة بشكل فعال من خلال آلية الاهتمام التفاضلي المبتكرة، مما يسمح للنموذج بالتركيز بشكل أكبر على المعلومات الأساسية، وبالتالي تحقيق تحسينات كبيرة في جوانب متعددة، بما في ذلك نمذجة اللغة، ومعالجة النصوص الطويلة، واسترجاع المعلومات الأساسية، وتقليل وهم النموذج، وما إلى ذلك .
لقد تطورت نماذج اللغة الكبيرة (LLM) بسرعة مؤخرًا، حيث يلعب نموذج المحولات دورًا مهمًا. جوهر المحول هو آلية الانتباه، التي تعمل كمرشح للمعلومات وتسمح للنموذج بالتركيز على الأجزاء الأكثر أهمية في الجملة. ولكن حتى المحول القوي سوف يتداخل مع معلومات غير ذات صلة، تمامًا مثلما تحاول العثور على كتاب في المكتبة، لكنك غارق في كومة من الكتب غير ذات الصلة، وتكون الكفاءة منخفضة بشكل طبيعي.
تسمى المعلومات غير ذات الصلة التي تولدها آلية الانتباه هذه بضجيج الانتباه في الورقة. تخيل أنك تريد العثور على جزء أساسي من المعلومات في ملف، ولكن انتباه نموذج Transformer مشتت إلى أماكن مختلفة غير ذات صلة، تمامًا مثل شخص قصير النظر لا يمكنه رؤية النقاط الرئيسية.
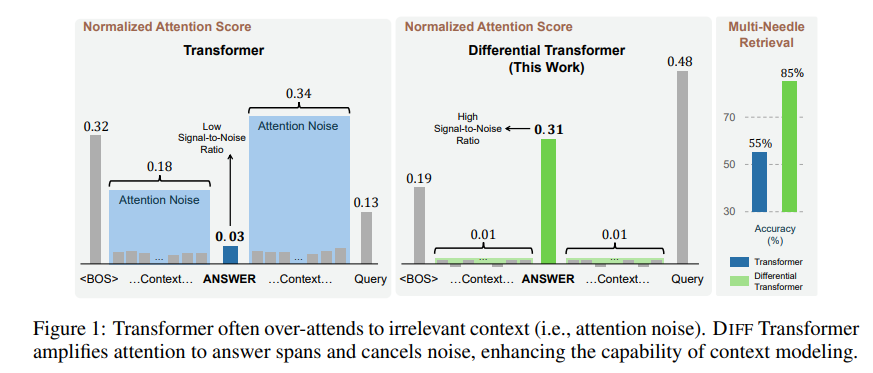
لحل هذه المشكلة، تقترح هذه الورقة المحول التفاضلي (DIFF Transformer). الاسم متقدم جدًا، لكن المبدأ في الواقع بسيط جدًا، تمامًا مثل سماعات إلغاء الضوضاء، يتم التخلص من الضوضاء من خلال الفرق بين إشارتين.
جوهر المحول التفاضلي هو آلية الاهتمام التفاضلي. فهو يقسم الاستعلام والمتجهات الرئيسية إلى مجموعتين، ويحسب خريطتين للانتباه على التوالي، ثم يطرح هاتين الخريطتين للحصول على درجة الاهتمام النهائية. تشبه هذه العملية تصوير نفس الكائن بكاميرتين، ثم تركيب الصورتين، وسيتم تسليط الضوء على الاختلافات.
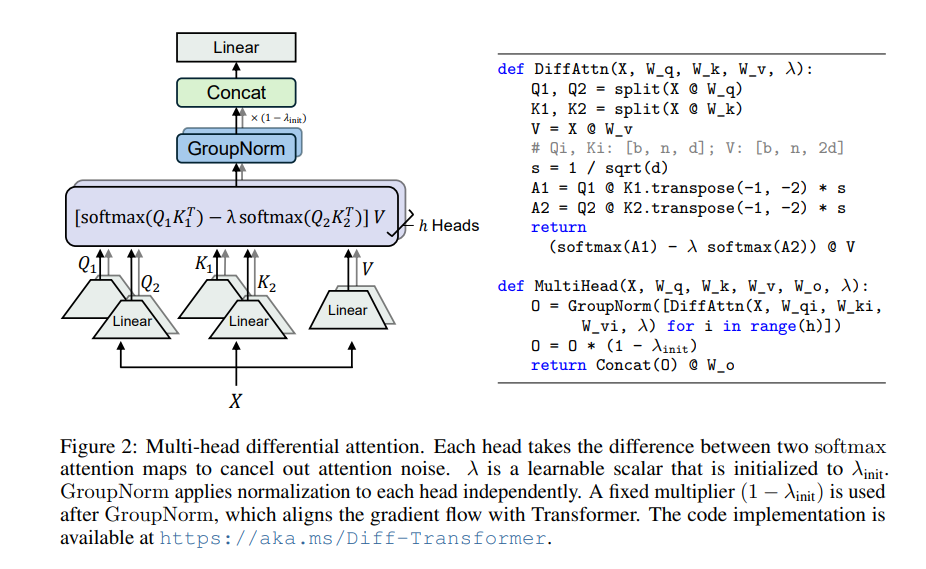
بهذه الطريقة، يمكن للمحول التفاضلي التخلص بشكل فعال من ضوضاء الانتباه والسماح للنموذج بالتركيز بشكل أكبر على المعلومات الأساسية. تمامًا كما هو الحال عندما تضع سماعات الرأس المانعة للضوضاء، تختفي الضوضاء المحيطة ويمكنك سماع الصوت الذي تريده بشكل أكثر وضوحًا.
تم إجراء سلسلة من التجارب في هذا البحث لإثبات تفوق المحول التفاضلي. أولاً، يؤدي أداءً جيدًا في نمذجة اللغة، حيث يتطلب 65% فقط من حجم النموذج أو بيانات التدريب الخاصة بالمحول لتحقيق نتائج مماثلة.
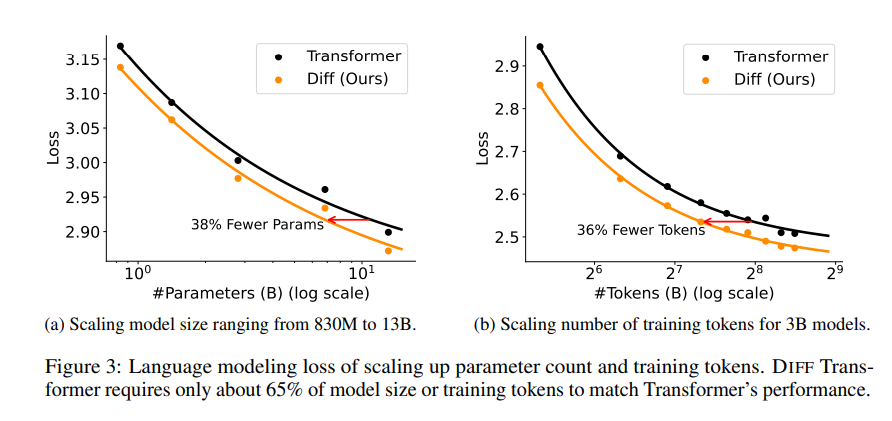
ثانيًا، يعد المحول التفاضلي أيضًا أفضل في نمذجة النص الطويل ويمكنه الاستفادة بشكل فعال من المعلومات السياقية الأطول.
والأهم من ذلك، أن المحول التفاضلي يُظهر مزايا كبيرة في استرجاع المعلومات الأساسية، وتقليل وهم النماذج، وتعلم السياق.
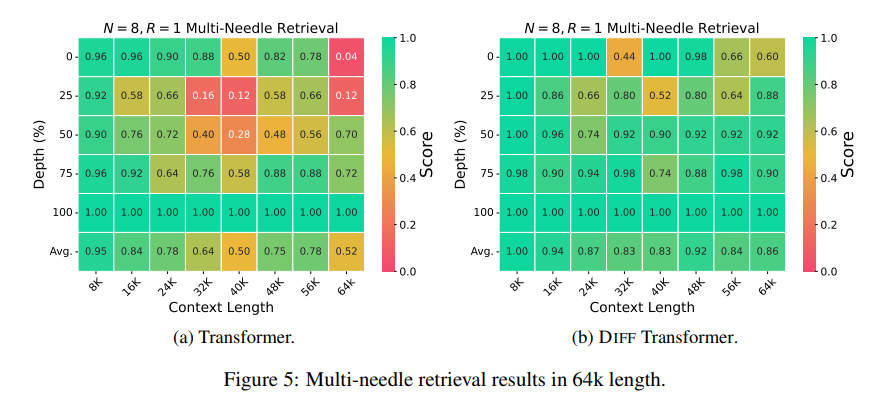
فيما يتعلق باسترجاع المعلومات الأساسية، يشبه المحول التفاضلي محرك بحث دقيق يمكنه العثور بدقة على ما تريده بكميات هائلة من المعلومات، ويمكنه الحفاظ على دقة عالية حتى في السيناريوهات التي تحتوي على معلومات معقدة للغاية.
فيما يتعلق بتقليل الهلوسة النموذجية، يمكن للمحول التفاضلي تجنب "الهراء" النموذجي بشكل فعال وإنشاء تلخيص نص أكثر دقة وموثوقية ونتائج أسئلة وأجوبة.
من حيث التعلم السياقي، يعتبر المحول التفاضلي أشبه بمعلم التعلم، فهو قادر على تعلم المعرفة الجديدة بسرعة من عدد صغير من العينات، ويكون تأثير التعلم أكثر استقرارًا، على عكس المحول الذي لا يتأثر بسهولة بترتيب العينات .
بالإضافة إلى ذلك، يمكن للمحول التفاضلي أيضًا تقليل القيم المتطرفة في قيم تنشيط النموذج بشكل فعال، مما يعني أنه أكثر ملاءمة لتكميم النموذج ويمكنه تحقيق تكميم بت أقل، وبالتالي تحسين كفاءة النموذج.
بشكل عام، يعمل المحول التفاضلي على حل مشكلة ضجيج الانتباه لنموذج المحول بشكل فعال من خلال آلية الانتباه التفاضلي ويحقق تحسينات كبيرة في جوانب متعددة. فهو يوفر أفكارًا جديدة لتطوير نماذج لغوية كبيرة وسيلعب دورًا مهمًا في المزيد من المجالات في المستقبل.
عنوان الورقة: https://arxiv.org/pdf/2410.05258
بشكل عام، يوفر المحول التفاضلي طريقة فعالة لحل مشكلة ضجيج الانتباه لنموذج المحول، ويشير أدائه الممتاز في مجالات متعددة إلى موقعه المهم في تطوير نماذج لغوية كبيرة في المستقبل. يوصي محرر Downcodes القراء بقراءة الورقة الكاملة للحصول على فهم متعمق لتفاصيلها الفنية وآفاق التطبيق. نحن نتطلع إلى أن يحقق المحول التفاضلي المزيد من الإنجازات في مجال الذكاء الاصطناعي!