حقق فريق من خريجي جامعة تسينغهوا إنجازات رياضية مبهرة بمساعدة الذكاء الاصطناعي! لقد نجح برنامج LeanAgent الذي طوروه، وهو مساعد الذكاء الاصطناعي الذي يتمتع بقدرات التعلم مدى الحياة، في إثبات 162 نظرية رياضية لم يتم حلها سابقًا، كما نجح في حل المشكلة الرسمية لحدسية فريمان-روزسا متعددة الحدود التي اقترحها تيرينس تاو. ولا يوضح هذا الإمكانات الهائلة للذكاء الاصطناعي في البحث العلمي الأساسي فحسب، بل يمثل أيضًا ابتكارًا في أساليب البحث الرياضي. سيمنحك محررو Downcodes فهمًا متعمقًا لهذا التطور المثير والابتكار التكنولوجي وراء LeanAgent.
في آخر الأخبار المثيرة في عالم الرياضيات، استخدمت مجموعة من خريجي جامعة تسينغهوا قوة الذكاء الاصطناعي لإثبات 162 نظرية رياضية بنجاح لم يتمكن أحد من حلها من قبل. والأكثر إثارة للدهشة هو أن هذا العميل المسمى LeanAgent تغلب بالفعل على مشكلة إضفاء الطابع الرسمي على تخمين فريمان-روزا متعدد الحدود، مما يجعلنا نأسف لأن أساليب البحث في العلوم الأساسية قد تغيرت بالكامل بواسطة الذكاء الاصطناعي.
كما نعلم جميعًا، على الرغم من أن نماذج اللغة الحالية (LLM) رائعة، إلا أن معظمها لا يزال ثابتًا ولا يمكنه تعلم معرفة جديدة عبر الإنترنت، ومن الصعب إثبات النظريات الرياضية المتقدمة. ومع ذلك، فإن LeanAgent، الذي تم تطويره بشكل مشترك من قبل فرق بحث من معهد كاليفورنيا للتكنولوجيا وجامعة ستانفورد وجامعة واشنطن، هو مساعد للذكاء الاصطناعي يتمتع بقدرات التعلم مدى الحياة ويمكنه التعلم وإثبات النظريات بشكل مستمر.
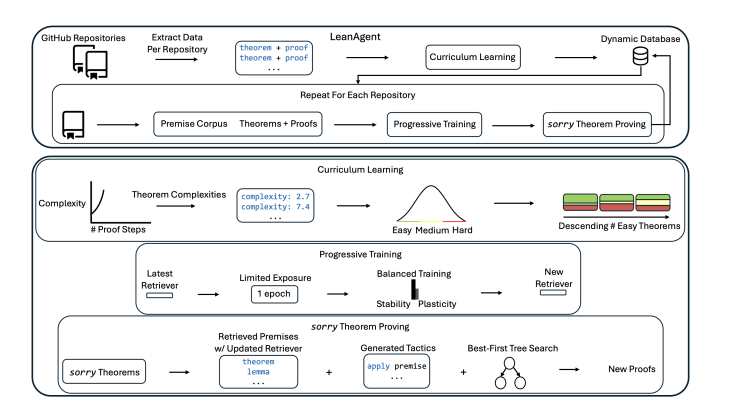
يستجيب LeanAgent للصعوبات الرياضية المختلفة من خلال مسارات تعليمية مصممة بعناية، ويستخدم قاعدة بيانات ديناميكية لإدارة تدفق مستمر من المعرفة الرياضية لضمان عدم نسيان المهارات التي أتقنها بالفعل عند تعلم معرفة جديدة. وتظهر التجارب أنه نجح في إثبات 162 نظرية رياضية لم يتمكن أحد من حلها من قبل من 23 مكتبة أكواد Lean مختلفة، وأدائه أعلى بـ 11 مرة من أداء النماذج الكبيرة التقليدية، إنه أمر مذهل حقًا!
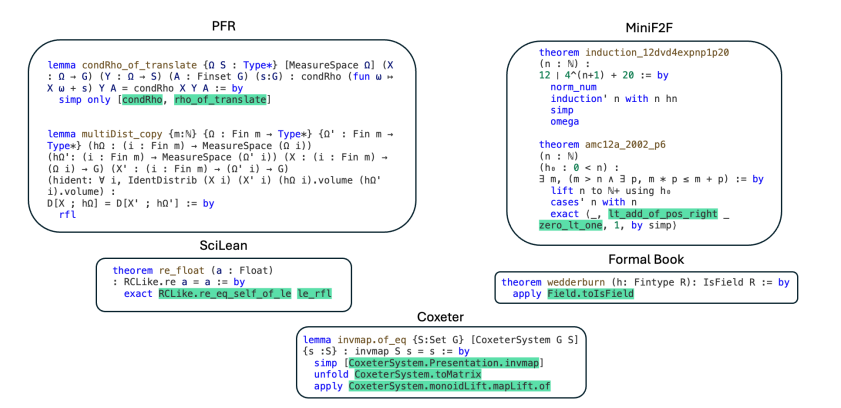
تغطي هذه النظريات العديد من مجالات الرياضيات العليا، بما في ذلك المسائل الصعبة مثل الجبر المجرد والطوبولوجيا الجبرية. لا يقتصر الأمر على قدرة LeanAgent على البدء بمفاهيم بسيطة ومعالجة الموضوعات المعقدة تدريجيًا فحسب، بل يُظهر أيضًا أداءً ممتازًا من حيث الاستقرار والهجرة العكسية.
ومع ذلك، لا يزال التحدي الذي يواجهه تيرينس تاو يجعل الذكاء الاصطناعي يشعر بالعجز. على الرغم من أن مثبتات النظرية التفاعلية (ITPs) مثل Lean تلعب دورًا مهمًا في إضفاء الطابع الرسمي على البراهين الرياضية والتحقق منها، إلا أن عملية بناء مثل هذه البراهين غالبًا ما تكون معقدة وتستغرق وقتًا طويلاً، وتتطلب خطوات دقيقة ومكتبات أكواد رياضية واسعة النطاق. النماذج الكبيرة المتقدمة مثل o1 وClaude معرضة أيضًا للأخطاء عند مواجهة البراهين غير الرسمية، مما يسلط الضوء على أوجه القصور في LLM في دقة وموثوقية البراهين الرياضية.
حاولت الأبحاث السابقة استخدام LLM لإنشاء خطوات إثبات كاملة، مثل LeanDojo، وهو مُبرهن نظري تم إنشاؤه عن طريق تدريب نموذج كبير على مجموعة بيانات محددة. ومع ذلك، فإن البيانات الخاصة ببراهين النظرية الرسمية نادرة للغاية، مما يحد من إمكانية تطبيق هذا النهج على نطاق واسع. مشروع آخر، ReProver، هو نموذج مُحسّن لمكتبة أكواد إثبات نظرية Lean mathlib4. على الرغم من أنه يغطي أكثر من 100.000 نظرية وتعريفات رياضية رسمية، إلا أنه يقتصر على نطاق الرياضيات الجامعية، لذلك لا يعمل بشكل جيد عند مواجهة المزيد من التعقيد. مشاكل جيدة.
ومن الجدير بالذكر أن الطبيعة الديناميكية للبحث الرياضي تجلب تحديات أكبر للذكاء الاصطناعي. عادة ما يعمل علماء الرياضيات على مشاريع متعددة في نفس الوقت أو بالتناوب. على سبيل المثال، يقوم تيرينس تاو بتطوير مجالات بحثية متعددة في نفس الوقت، بما في ذلك تخمين PFR والمتوسط المتماثل للأرقام الحقيقية. تُظهر هذه الأمثلة عيبًا رئيسيًا في طرق إثبات نظرية الذكاء الاصطناعي الحالية: عدم وجود نظام ذكاء اصطناعي يمكنه التعلم والتحسين بشكل تكيفي في مجالات رياضية مختلفة، خاصة عندما تكون البيانات اللينة محدودة.
ولهذا السبب قام فريق LeanDojo بإنشاء LeanAgent، وهو إطار عمل جديد للتعلم مدى الحياة مصمم لحل التحديات المذكورة أعلاه. يتضمن سير عمل LeanAgent استخلاص تعقيد النظرية لصياغة دورات تعليمية، وتحقيق التوازن بين الاستقرار والمرونة في عملية التعلم من خلال التدريب التدريجي، واستخدام أفضل بحث في الشجرة الأولى للعثور على نظريات غير مثبتة حتى الآن.
يعمل LeanAgent مع أي نموذج كبير لتحسين قدرات التعميم من خلال "الاسترجاع". يكمن ابتكارها في استخدام قاعدة بيانات ديناميكية مخصصة لإدارة المعرفة الرياضية الآخذة في التوسع، واستراتيجية تعلم الدورة التدريبية القائمة على بنية Lean Proof للمساعدة في تعلم محتوى رياضي أكثر تعقيدًا.
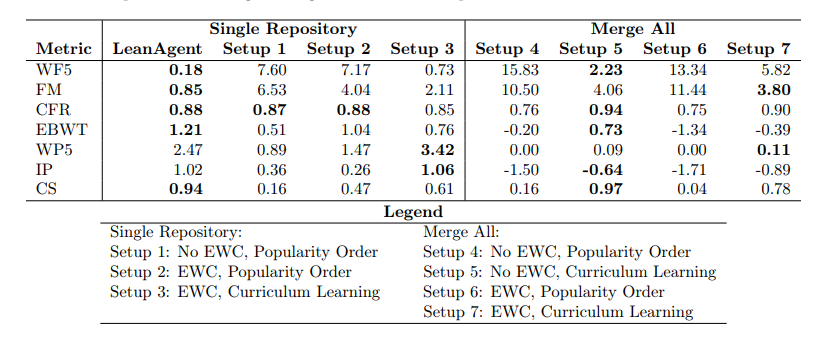
للتعامل مع مشكلة النسيان الكارثية للذكاء الاصطناعي، اعتمد الباحثون أسلوب تدريب تدريجي لتمكين LeanAgent من التكيف المستمر مع المعرفة الرياضية الجديدة دون نسيان التعلم السابق. تتضمن هذه العملية تدريبًا إضافيًا على كل مجموعة بيانات جديدة، مما يضمن التوازن الأمثل بين الاستقرار والمرونة.
من خلال هذا النوع من التدريب التدريجي، يتمتع LeanAgent بأداء ممتاز في إثبات النظريات، حيث أثبت بنجاح 162 مشكلة صعبة لم يتم حلها من قبل البشر، وخاصة في تحدي نظريات الجبر المجرد والطوبولوجيا الجبرية. قدرته على إثبات نظريات جديدة أعلى بـ 11 مرة من قدرة ReProver الساكنة، مع احتفاظه بقدرته على إثبات النظريات المعروفة.
يُظهر LeanAgent خصائص التعلم التدريجي أثناء عملية إثبات النظرية، حيث ينتقل تدريجيًا من النظريات البسيطة إلى النظريات الأكثر تعقيدًا، مما يثبت عمقه في إتقان المعرفة الرياضية. على سبيل المثال، يوضح فهمًا عميقًا للرياضيات من خلال إثبات نظريات البنية الجبرية الأساسية المتعلقة بنظرية المجموعة ونظرية الحلقة. بشكل عام، يقدم LeanAgent آفاقًا مثيرة لمجتمع الرياضيات من خلال قدراته القوية على التعلم والتحسين المستمر!
عنوان الورقة: https://arxiv.org/pdf/2410.06209
يشير ظهور LeanAgent إلى أن الذكاء الاصطناعي سيلعب دورًا متزايد الأهمية في مجال البحث الرياضي، وقد يكون هناك المزيد من الحالات في المستقبل التي تستخدم قوة الذكاء الاصطناعي لحل المشكلات الرياضية المعقدة. وهذا بلا شك يفتح اتجاهًا جديدًا للبحث الرياضي، كما يوفر أفكارًا وطرقًا جديدة للاستكشاف في المجالات العلمية الأخرى. نتطلع إلى المزيد من النتائج المذهلة في المستقبل!