سيأخذك محرر Downcodes للتعرف على أحدث الإنجازات التي حققها فريق الذكاء الاصطناعي في Alibaba! ويحقق نموذج mPLUG-DocOwl1.5 الذي أطلقوه إمكانات ممتازة لفهم المستندات دون الحاجة إلى تقنية التعرف الضوئي على الحروف. يكسر هذا النموذج عنق الزجاجة في فهم المستندات التقليدية ويتعلم فهم محتوى المستند مباشرة من الصور، حيث إن كفاءته ودقته مذهلة. لا يمكنه معالجة المستندات العادية فحسب، بل يدعم أيضًا مجموعة متنوعة من أنواع المستندات مثل الجداول والمخططات وصفحات الويب والصور الطبيعية، مما يُظهر قدرة قوية على التكيف وقدرات المعالجة. دعونا نلقي نظرة فاحصة على المزايا واتجاهات التطوير المستقبلية لنموذج الذكاء الاصطناعي المتطور هذا.
في الآونة الأخيرة، حقق فريق أبحاث الذكاء الاصطناعي التابع لشركة Alibaba تقدمًا مثيرًا للإعجاب في مجال فهم المستندات، حيث أطلقوا mPLUG-DocOwl1.5، وهو نموذج متطور يؤدي بشكل ممتاز في مهام فهم المستندات الخالية من التعرف الضوئي على الحروف (OCR).
في الماضي، عند التعامل مع مهام فهم المستندات، كنا نعتمد غالبًا على تقنية التعرف الضوئي على الحروف (OCR) لاستخراج النص من الصور، ولكن هذا غالبًا ما كان يعاني من التخطيطات المعقدة والضوضاء المرئية. يستخدم mPLUG-DocOwl1.5 إطارًا جديدًا لتعلم البنية الموحدة لتعلم المستندات وفهمها مباشرةً من الصور، مما يؤدي إلى تجنب هذا الاختناق بذكاء.
يغطي هذا النموذج خمسة مجالات بما في ذلك المستندات العادية والجداول والرسوم البيانية وصفحات الويب والصور الطبيعية من خلال تحليل التخطيط والقدرات التنظيمية للمستندات في مجالات مختلفة. فهو لا يتعرف بدقة على النص فحسب، بل يستخدم أيضًا عناصر مثل المسافات وفواصل الأسطر عند فهم بنية المستند.

بالنسبة للجداول، يمكن للنموذج إنشاء تنسيقات Markdown منظمة، وعند تحليل المخططات، فإنه يحولها إلى جداول بيانات من خلال فهم العلاقات بين وسائل الإيضاح والمحاور والقيم. بالإضافة إلى ذلك، يتمتع mPLUG-DocOwl1.5 أيضًا بالقدرة على استخراج النص من الصور الطبيعية.
فيما يتعلق بترجمة النص، فإن mPLUG-DocOwl1.5 قادر على تحديد وتحديد الكلمات والعبارات والسطور والكتل، مما يضمن المحاذاة الدقيقة بين مناطق النص والصورة. تجمع بنية H-Reducer الموجودة خلفها بين الميزات المرئية أفقيًا من خلال عمليات الالتواء، والحفاظ على التخطيط المكاني مع تقليل طول التسلسل، وبالتالي تحسين كفاءة المعالجة.
لتدريب هذا النموذج، استخدم فريق البحث مجموعتين من البيانات المختارة بعناية. DocStruct4M عبارة عن مجموعة بيانات واسعة النطاق تركز على تعلم البنية الموحدة، ويقوم DocReason25K باختبار قدرات الاستدلال للنموذج من خلال الأسئلة والأجوبة خطوة بخطوة.
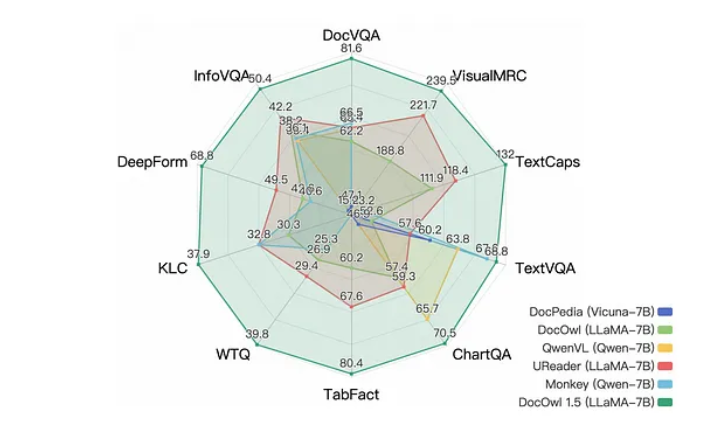
وأظهرت النتائج أن mPLUG-DocOwl1.5 سجل أرقاماً قياسية جديدة في عشرة اختبارات مرجعية، محققاً تحسناً بأكثر من 10 نقاط في نصف المهام مقارنة بالنماذج المماثلة. بالإضافة إلى ذلك، فهو يُظهر مهارات تفكير لفظي ممتازة وقادر على إنشاء تفسيرات مفصلة خطوة بخطوة لإجاباته.
على الرغم من أن mPLUG-DocOwl1.5 قد حقق تقدمًا كبيرًا في العديد من الجوانب، فقد أدرك الباحثون أيضًا أنه لا يزال هناك مجال للتحسين في النموذج، خاصة في التعامل مع البيانات غير المتسقة أو الخاطئة. في المستقبل، يأمل الفريق في توسيع إطار التعلم الهيكلي الموحد لتغطية المزيد من أنواع المستندات ومهامها، وتعزيز التطوير الإضافي للذكاء الاصطناعي للمستندات.
الورقة: https://arxiv.org/abs/2403.12895
الكود: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
تسليط الضوء على:
mPLUG-DocOwl1.5 هو نموذج للذكاء الاصطناعي يؤدي أداءً ممتازًا في مهام فهم المستندات دون التعرف الضوئي على الحروف.
يمكن للنموذج تحليل تخطيط المستند وتغطية أنواع متعددة من المستندات والتعلم مباشرة من الصور.
سجل mPLUG-DocOwl1.5 أرقامًا قياسية جديدة في عشرة اختبارات مرجعية، مما يدل على قدرات التفكير اللغوي الفائقة.
يمثل ظهور mPLUG-DocOwl1.5 علامة فارقة جديدة في تكنولوجيا فهم المستندات. توفر كفاءتها ودقتها وقدرتها القوية على التكيف إمكانيات غير محدودة لمعالجة المستندات واستخراج المعلومات في المستقبل. يعتقد محرر Downcodes أنه مع التقدم المستمر للتكنولوجيا، سيلعب mPLUG-DocOwl1.5 دورًا مهمًا في المزيد من المجالات وسيوفر لنا تجربة معالجة معلومات أكثر ذكاءً.