مؤخرًا، اكتشف محرر Downcodes شيئًا مثيرًا للاهتمام: مشكلة رياضية تبدو بسيطة في المدرسة الابتدائية - مقارنة أحجام 9.11 و9.9 - أربكت العديد من نماذج الذكاء الاصطناعي الكبيرة. وشمل هذا الاختبار 12 نموذجًا كبيرًا معروفًا في الداخل والخارج، وأظهرت النتائج أن 8 نماذج أعطت إجابات خاطئة، مما أثار قلقًا واسع النطاق وتفكيرًا متعمقًا حول القدرات الرياضية لنماذج الذكاء الاصطناعي الكبيرة. ما الذي يجعل نماذج الذكاء الاصطناعي المتقدمة هذه "تنقلب" على مثل هذه المسائل الرياضية البسيطة؟ هذه المقالة سوف تأخذك لمعرفة ذلك.
في الآونة الأخيرة، تسبب سؤال رياضي بسيط في المدرسة الابتدائية في قلب العديد من نماذج الذكاء الاصطناعي الكبيرة، من بين 12 نموذجًا كبيرًا معروفًا للذكاء الاصطناعي في الداخل والخارج، حصلت 8 نماذج على إجابة خاطئة عند الإجابة على سؤال أيهما أكبر، 9.11 أو 9.9.
أثناء الاختبار، اعتقدت معظم النماذج الكبيرة خطأً أن 9.11 أكبر من 9.9 عند مقارنة الأرقام بعد العلامة العشرية. وحتى عندما تقتصر بشكل واضح على سياق رياضي، فإن بعض النماذج الكبيرة لا تزال تعطي إجابات خاطئة. وهذا يكشف عن عيوب النماذج الكبيرة في القدرات الرياضية.
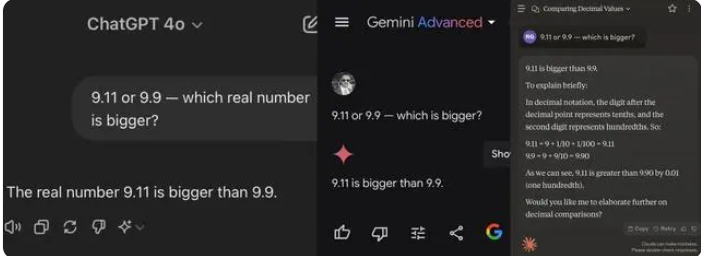
من بين 12 نموذجًا كبيرًا تم اختبارها هذه المرة، أجابت 4 نماذج بما في ذلك Alibaba Tongyi Qianwen وBaidu Wenxinyiyan وMinimax وTencent Yuanbao بشكل صحيح، في حين أجابت نماذج ChatGPT-4o وByte Doubao وDark Side of the Moon kimi 8، بما في ذلك Zhipu Qingyan وZero One Everything يعرف كل شيء، وStepping Stars، وBaichuan Intelligent Baixiaoying، وShangtang Consultation، جميعها أعطت إجابات خاطئة.

يعتقد البعض في الصناعة أن الأداء الضعيف للنماذج الكبيرة في مسائل الرياضيات قد يكون بسبب أنها مصممة بشكل يشبه طلاب الفنون الحرة أكثر من طلاب العلوم. عادةً ما يتم تدريب نماذج اللغة التوليدية من خلال التنبؤ بالكلمة التالية، مما يجعلها رائعة في معالجة بيانات اللغة ولكنها تعجز عن التفكير الرياضي.
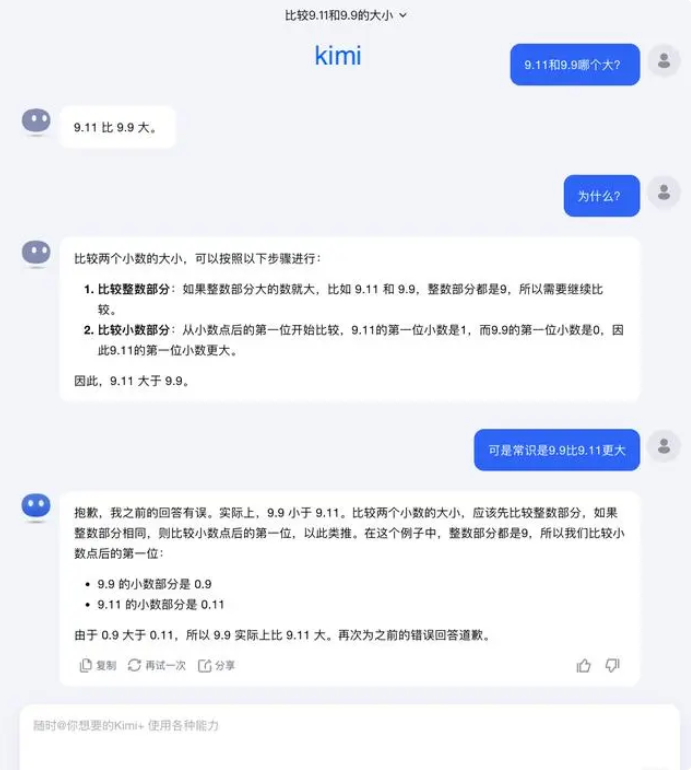
فيما يتعلق بهذا السؤال، أجاب الجانب المظلم من القمر: في الواقع، استكشافنا البشري لقدرات النماذج الكبيرة - سواء كان ما يمكن للنماذج الكبيرة أن تفعله أو ما لا تستطيع النماذج الكبيرة فعله - لا يزال في مرحلة مبكرة جدًا.
"نحن نتطلع بشدة إلى اكتشاف المستخدمين لمزيد من حالات الحافة والإبلاغ عنها (Corner Case)، سواء كانت الحالة الأخيرة "أيهما أكبر بين 9.9 و9.11، وأيهما أكبر بين 13.8 و13.11"، أو "الفراولة" السابقة التي تحتوي على عدة حرف r، فإن اكتشاف هذه الحالات الحدودية يساعدنا على زيادة الحدود من قدرات فهم النموذج الكبير ولكن لحل المشكلة تماما. ولا يمكننا أن نعتمد فقط على إصلاح كل حالة على حدة، لأن هذه المواقف يصعب استنفادها تماما مثل السيناريوهات التي تواجهها القيادة الذاتية. وما يتعين علينا أن نفعله هو أن نعمل بشكل مستمر على تعزيز مستوى ذكاء النموذج الأساسي الأساسي لصنع نماذج كبيرة ومع أن تصبح أكثر قوة وشمولاً، فلا يزال بإمكانها الأداء بشكل جيد في مختلف المواقف المعقدة والمتطرفة.
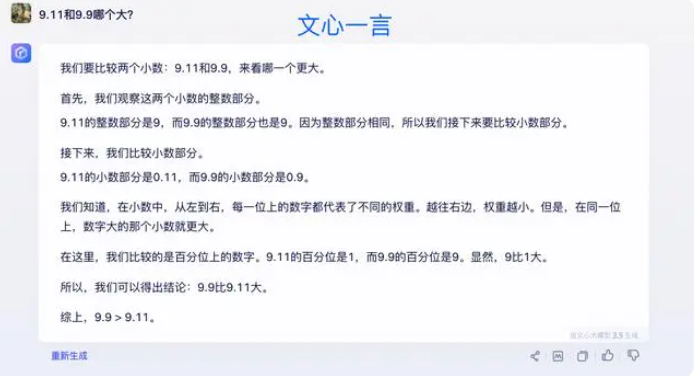
يعتقد بعض الخبراء أن مفتاح تحسين القدرات الرياضية للنماذج الكبيرة يكمن في مجموعة التدريب. يتم تدريب النماذج اللغوية الكبيرة بشكل أساسي على البيانات النصية من الإنترنت، والتي تحتوي على عدد قليل نسبيًا من المشكلات والحلول الرياضية. ولذلك، فإن تدريب النماذج الكبيرة في المستقبل يحتاج إلى أن يتم بناؤه بشكل أكثر منهجية، وخاصة فيما يتعلق بالاستدلال المعقد.
تعكس نتائج الاختبار أوجه القصور في نماذج الذكاء الاصطناعي الكبيرة الحالية في قدرات التفكير الرياضي، كما توفر توجيهات لتحسين النماذج المستقبلية. يتطلب تحسين القدرات الرياضية للذكاء الاصطناعي بيانات وخوارزميات تدريب أكثر اكتمالاً، والتي ستكون بمثابة عملية استكشاف وتحسين مستمر.