في الآونة الأخيرة، أثار سؤال المقارنة الرياضية الذي يبدو بسيطًا "أيهما أكبر، 13.8 أم 13.11" حيرة الكثير من الناس، بما في ذلك بعض نماذج الذكاء الاصطناعي المتقدمة. سيأخذك محرر Downcodes للتعمق في هذه الحادثة، وتحليل أوجه القصور في الذكاء الاصطناعي في التعامل مع القضايا المنطقية، واتجاه التحسين المستقبلي. وهذا لا يكشف عن حدود تكنولوجيا الذكاء الاصطناعي فحسب، بل يحفز الناس أيضًا على التفكير في التطوير المستقبلي للذكاء الاصطناعي.
في الآونة الأخيرة، لم يحير سؤال رياضي بسيط - أيهما أكبر، 13.8 أم 13.11؟ - بعض البشر فحسب، بل وضع أيضًا العديد من النماذج اللغوية الكبيرة في مشكلة. أثار هذا السؤال نقاشًا واسع النطاق حول قدرة الذكاء الاصطناعي على التعامل مع المشكلات المنطقية.
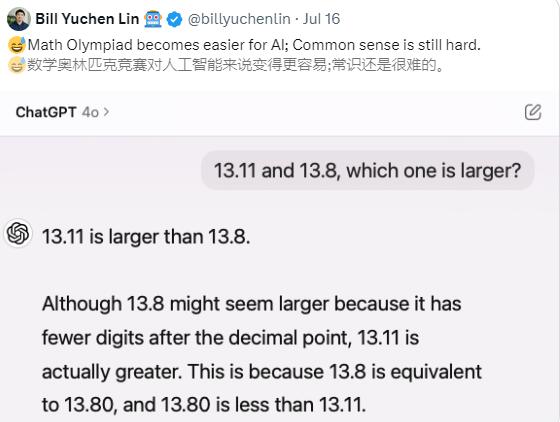
وفي برنامج متنوع معروف، أثارت هذه القضية مناقشات ساخنة بين مستخدمي الإنترنت. يعتقد الكثير من الناس أن 13.11% يجب أن تكون أكبر من 13.8%، ولكن في الواقع 13.8% أكبر.
وجد الباحث في الذكاء الاصطناعي Lin Yuchen أنه حتى النماذج اللغوية الكبيرة، مثل GPT-4o، ترتكب أخطاء في مشكلة المقارنة البسيطة هذه. اعتقد GPT-4o خطأً أن 13.11 أكبر من 13.8 وقدم تفسيرًا خاطئًا.
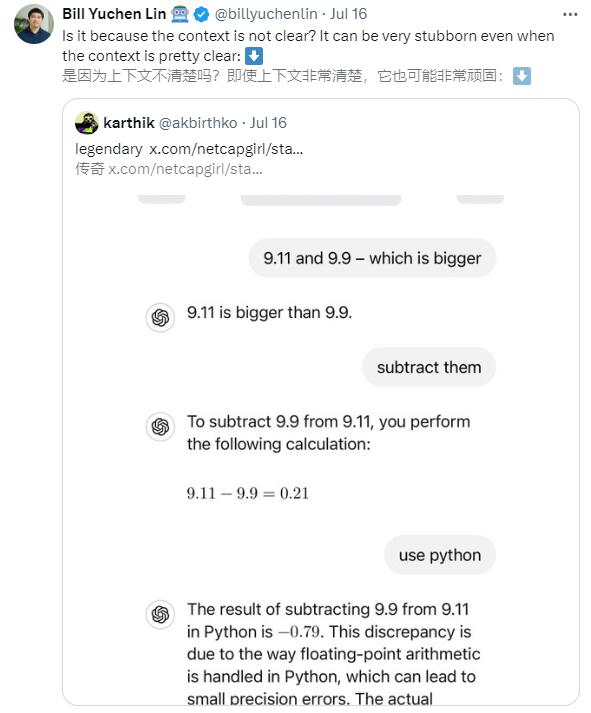
أثار اكتشاف لين يوشن بسرعة مناقشات ساخنة في مجتمع الذكاء الاصطناعي. العديد من نماذج اللغات الكبيرة الأخرى، مثل Gemini وClaude3.5Sonnet وما إلى ذلك، ترتكب أيضًا نفس الخطأ في مشكلة المقارنة البسيطة هذه.
ويكشف ظهور هذه المشكلة عن الصعوبات التي يمكن أن يواجهها الذكاء الاصطناعي عند التعامل مع المهام التي تبدو بسيطة ولكنها في الواقع تنطوي على مقارنات عددية دقيقة.
على الرغم من أن الذكاء الاصطناعي قد حقق تقدمًا كبيرًا في العديد من المجالات، مثل فهم اللغة الطبيعية، والتعرف على الصور، واتخاذ القرارات المعقدة، إلا أنه لا يزال من الممكن أن يرتكب أخطاء عندما يتعلق الأمر بالعمليات الرياضية الأساسية والتفكير المنطقي، مما يوضح حدود التكنولوجيا الحالية.
لماذا يرتكب الذكاء الاصطناعي مثل هذه الأخطاء؟
التحيز في بيانات التدريب: قد لا تحتوي بيانات التدريب الخاصة بنموذج الذكاء الاصطناعي على أمثلة كافية للتعامل بشكل صحيح مع هذا النوع المحدد من مشاكل المقارنة الرقمية. إذا تعرض النموذج لبيانات أثناء التدريب تشير في المقام الأول إلى أن الأعداد الأكبر تحتوي دائمًا على المزيد من المنازل العشرية، فقد يفسر بشكل غير صحيح المزيد من المنازل العشرية على أنها قيم أكبر.
مشكلات دقة النقطة العائمة: في علوم الكمبيوتر، يتضمن تمثيل وحساب أرقام الفاصلة العائمة مشكلات تتعلق بالدقة. حتى الاختلافات الصغيرة يمكن أن تسبب نتائج خاطئة عند المقارنة، خاصة إذا لم يتم تحديد الدقة بشكل صريح.
عدم كفاية الفهم السياقي: على الرغم من أن وضوح السياق قد لا يكون مشكلة رئيسية في هذه الحالة، إلا أن نماذج الذكاء الاصطناعي غالبًا ما تحتاج إلى تفسير المعلومات بشكل صحيح بناءً على السياق. يمكن أن ينتج سوء الفهم إذا تمت صياغة السؤال بطريقة غير واضحة بما فيه الكفاية أو لا تتطابق مع الأنماط الشائعة للذكاء الاصطناعي في بيانات التدريب.
تأثير التصميم الفوري: إن كيفية طرح الأسئلة على الذكاء الاصطناعي أمر بالغ الأهمية للحصول على الإجابة الصحيحة. قد تؤثر طرق الأسئلة المختلفة على فهم الذكاء الاصطناعي ودقة الإجابات.
كيفية التحسن؟
تحسين بيانات التدريب: من خلال توفير بيانات تدريب أكثر تنوعًا ودقة، يمكن مساعدة نماذج الذكاء الاصطناعي على فهم المقارنات الرقمية والمفاهيم الرياضية الأساسية الأخرى بشكل أفضل.
تحسين التصميم السريع: يمكن لصياغة المشكلة المصممة جيدًا أن تزيد من فرصة الذكاء الاصطناعي في تقديم الإجابة الصحيحة. على سبيل المثال، يمكن أن يؤدي استخدام تمثيلات رقمية وطرق طرح أكثر وضوحًا إلى تقليل الغموض.
تحسين دقة المعالجة الرقمية: تطوير واعتماد الخوارزميات والتقنيات التي تتعامل مع عمليات الفاصلة العائمة بشكل أكثر دقة لتقليل الأخطاء الحسابية.
تعزيز قدرات التفكير المنطقي والمنطق السليم: من خلال التدريب الذي يركز بشكل خاص على التفكير المنطقي والمنطق السليم، يتم تعزيز قدرات الذكاء الاصطناعي في هذه المجالات، مما يسمح له بفهم المهام المتعلقة بالحس السليم والتعامل معها بشكل أفضل.
وبشكل عام، فإن العيوب التي كشفها الذكاء الاصطناعي في التعامل مع مسائل المقارنة الرياضية البسيطة تذكرنا بأن تكنولوجيا الذكاء الاصطناعي لا تزال في مرحلة التطوير وتحتاج إلى التحسين والتحسين المستمر. في المستقبل، من خلال تحسين بيانات التدريب وتحسين الخوارزميات وتعزيز قدرات التفكير المنطقي، سيحقق الذكاء الاصطناعي تقدمًا أكبر في التعامل مع المشكلات المنطقية.