يستغرق التدريب على الذكاء الاصطناعي وقتًا طويلاً ويستهلك قوة الحوسبة، وهو ما كان دائمًا بمثابة عنق الزجاجة في مجال الذكاء الاصطناعي. أصدر فريق DeepMind مؤخرًا دراسة مذهلة واقترح طريقة جديدة لفحص البيانات تسمى JEST، والتي تحل هذه المشكلة بشكل فعال. سيمنحك محرر Downcodes فهمًا متعمقًا لكيفية قيام JEST بتحسين كفاءة تدريب الذكاء الاصطناعي بشكل كبير وشرح المبادئ التقنية الكامنة وراءه.
في مجال الذكاء الاصطناعي، كانت قوة الحوسبة والوقت دائمًا من العوامل الرئيسية التي تحد من التقدم التكنولوجي. ومع ذلك، فإن أحدث نتائج الأبحاث التي أجراها فريق DeepMind توفر حلاً لهذه المشكلة.
واقترحوا طريقة جديدة لفحص البيانات تسمى JEST، والتي تحقق انخفاضًا كبيرًا في وقت تدريب الذكاء الاصطناعي ومتطلبات طاقة الحوسبة من خلال الفحص الذكي لأفضل مجموعات البيانات للتدريب. ويقال إنه يمكن أن يقلل وقت تدريب الذكاء الاصطناعي بمقدار 13 مرة ويقلل متطلبات طاقة الحوسبة بنسبة 90%.
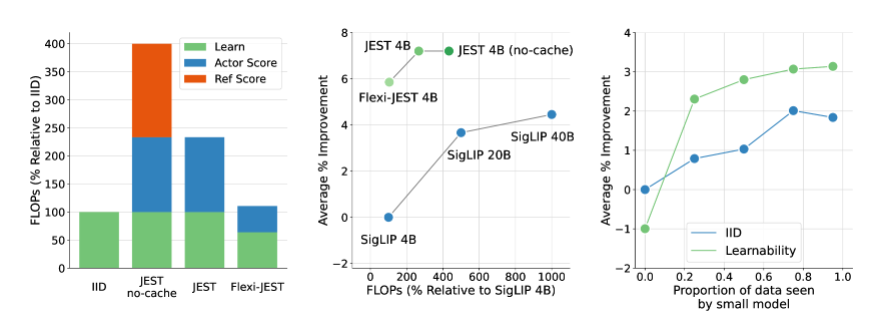
يكمن جوهر طريقة JEST في الاختيار المشترك لأفضل مجموعات البيانات بدلاً من العينات الفردية، وهي استراتيجية أثبتت فعاليتها بشكل خاص في تسريع التعلم متعدد الوسائط. بالمقارنة مع أساليب فحص البيانات التقليدية واسعة النطاق قبل التدريب، فإن JEST لا يقلل بشكل كبير من عدد التكرارات وعمليات الفاصلة العائمة فحسب، بل يتفوق أيضًا على أحدث التقنيات السابقة مع استخدام 10٪ فقط من ميزانية FLOP.
كشف بحث فريق DeepMind عن ثلاث نقاط رئيسية: اختيار مجموعات البيانات الجيدة أكثر فعالية من انتقاء نقاط البيانات بشكل فردي، ويمكن استخدام النماذج التقريبية عبر الإنترنت لتصفية البيانات بشكل أكثر كفاءة، ويمكن تشغيل مجموعات البيانات الصغيرة عالية الجودة للاستفادة من المجموعات الأكبر حجمًا. مجموعة بيانات غير منسقة. توفر هذه النتائج أساسًا نظريًا للأداء الفعال لطريقة JEST.
مبدأ عمل JEST هو تقييم إمكانية تعلم نقاط البيانات من خلال الاعتماد على الأبحاث السابقة حول فقدان RHO والجمع بين فقدان نموذج التعلم والنموذج المرجعي المُدرب مسبقًا. فهو يختار نقاط البيانات الأسهل بالنسبة للنموذج المُدرب مسبقًا ولكن الأكثر صعوبة بالنسبة لنموذج التعلم الحالي لتحسين كفاءة التدريب وفعاليته.
بالإضافة إلى ذلك، تتبنى JEST أيضًا طريقة تكرارية تعتمد على منع أخذ عينات Gibbs لبناء الدُفعات تدريجيًا، واختيار مجموعة فرعية جديدة من العينات بناءً على درجة قابلية التعلم المشروطة في كل تكرار. ويستمر هذا النهج في التحسن مع تصفية المزيد من البيانات، بما في ذلك استخدام النماذج المرجعية المدربة مسبقًا فقط لتسجيل نقاط البيانات.
لا يحقق هذا البحث الذي أجرته DeepMind تقدمًا مذهلاً في مجال التدريب على الذكاء الاصطناعي فحسب، بل يوفر أيضًا أفكارًا وأساليب جديدة لتطوير تكنولوجيا الذكاء الاصطناعي في المستقبل. ومع المزيد من التحسين والتطبيق لأسلوب JEST، لدينا سبب للاعتقاد بأن تطور الذكاء الاصطناعي سوف يفتح آفاقًا أوسع.
الورقة: https://arxiv.org/abs/2406.17711
تسليط الضوء على:
**ثورة كفاءة التدريب**: تقلل طريقة JEST من DeepMind من وقت تدريب الذكاء الاصطناعي بمقدار 13 مرة وتقلل من متطلبات طاقة الحوسبة بنسبة 90%.
**فحص مجموعة البيانات**: تعمل JEST على تحسين كفاءة التعلم متعدد الوسائط بشكل كبير من خلال الاختيار المشترك لأفضل مجموعات البيانات بدلاً من العينات الفردية.
️ **طريقة تدريب مبتكرة**: تستخدم JEST تقريب النماذج عبر الإنترنت وتوجيهات مجموعة البيانات عالية الجودة لتحسين توزيع البيانات وقدرات تعميم النماذج للتدريب المسبق على نطاق واسع.
لقد جلب ظهور طريقة JEST أملًا جديدًا للتدريب على الذكاء الاصطناعي، ومن المتوقع أن تعمل استراتيجيتها الفعالة لفحص البيانات على تعزيز تطبيق وتطوير تكنولوجيا الذكاء الاصطناعي في مختلف المجالات. في المستقبل، نتطلع إلى رؤية أداء JEST في المزيد من التطبيقات العملية ومواصلة تعزيز الإنجازات في مجال الذكاء الاصطناعي. سيستمر محرر Downcodes في الاهتمام بالتطورات ذات الصلة وتقديم المزيد من التقارير المثيرة للقراء.