في السنوات الأخيرة، يعتمد التطور السريع لتكنولوجيا الذكاء الاصطناعي بشكل كبير على تدريب البيانات الضخمة. ومع ذلك، وجد محرر موقع Downcodes أن أحدث الأبحاث من معهد ماساتشوستس للتكنولوجيا ومؤسسات أخرى أشارت إلى أن صعوبة الحصول على البيانات تتزايد بشكل كبير. إن بيانات الشبكة التي كانت متاحة بسهولة في السابق تخضع الآن لقيود متزايدة الصرامة، مما يشكل تحديات هائلة أمام تدريب وتطوير الذكاء الاصطناعي. وتكشف الدراسة، التي قامت بتحليل مجموعات بيانات متعددة مفتوحة المصدر، عن هذه الحقيقة الصارخة.
وراء التطور السريع للذكاء الاصطناعي، هناك مشكلة خطيرة تطفو على السطح، وهي صعوبة الحصول على البيانات. وقد توصلت أحدث الأبحاث التي أجراها معهد ماساتشوستس للتكنولوجيا ومؤسسات أخرى إلى أن بيانات الويب التي كان من السهل الوصول إليها في السابق أصبحت الآن أكثر صعوبة في الوصول إليها، مما يشكل تحديًا كبيرًا للتدريب والبحث في مجال الذكاء الاصطناعي.
وجد الباحثون أن مواقع الويب التي تم الزحف إليها بواسطة مجموعات بيانات متعددة مفتوحة المصدر مثل C4 وRefineWeb وDolma وما إلى ذلك تعمل على تشديد اتفاقيات الترخيص الخاصة بها بسرعة. ولا يؤثر هذا على تدريب نماذج الذكاء الاصطناعي التجارية فحسب، بل يعيق أيضًا البحث الذي تجريه المنظمات الأكاديمية وغير الربحية.

تم إجراء هذا البحث من قبل أربعة من قادة الفرق من MIT Media Lab، وكلية Wellesley، وشركة Raive الناشئة للذكاء الاصطناعي، ومؤسسات أخرى. ويشيرون إلى أن القيود المفروضة على البيانات آخذة في الانتشار وأن عدم التماثل والتناقضات في الترخيص أصبحت واضحة بشكل متزايد.
استخدم فريق البحث بروتوكول استبعاد الروبوتات (REP) وشروط خدمة الموقع (ToS) كطرق بحث. ووجدوا أنه حتى برامج الزحف التابعة لشركات الذكاء الاصطناعي الكبيرة مثل OpenAI واجهت قيودًا صارمة بشكل متزايد.
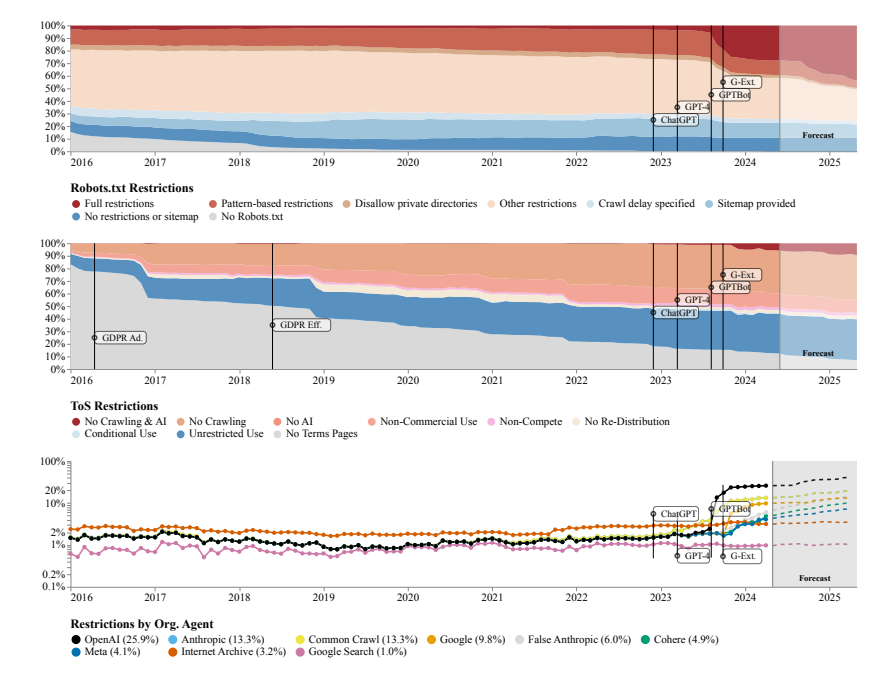
يتوقع نموذج SARIMA أنه في المستقبل، سواء من خلال ملف robots.txt أو ToS، ستستمر القيود المفروضة على بيانات موقع الويب في الزيادة. ويشير هذا إلى أن الوصول إلى بيانات الشبكة المفتوحة سيصبح أكثر صعوبة.
ووجدت الدراسة أيضًا أن البيانات التي تم الزحف إليها من الإنترنت لا تتوافق مع الغرض التدريبي لنموذج الذكاء الاصطناعي، مما قد يكون له تأثير على محاذاة النموذج وممارسات جمع البيانات وحقوق النشر.
ويدعو فريق البحث إلى ضرورة وجود اتفاقيات أكثر مرونة تعكس رغبات أصحاب المواقع، وفصل حالات الاستخدام المسموح بها وغير المسموح بها، ومتزامنة مع شروط الخدمة. وفي الوقت نفسه، يريدون أن يتمكن مطورو الذكاء الاصطناعي من استخدام البيانات الموجودة على شبكة الإنترنت المفتوحة للتدريب، ويأملون أن تدعم القوانين المستقبلية ذلك.
عنوان الورقة: https://www.dataprovenance.org/Consent_in_Crisis.pdf
وقد دق هذا البحث ناقوس الخطر بشأن مشكلة الحصول على البيانات في مجال الذكاء الاصطناعي، كما أثار تحديات جديدة لتدريب وتطوير نماذج الذكاء الاصطناعي المستقبلية. ستصبح كيفية الموازنة بين الحصول على البيانات وحقوق ومصالح أصحاب مواقع الويب قضية رئيسية يجب النظر فيها بجدية وحلها في مجال الذكاء الاصطناعي. يوصي محرر Downcodes بالاهتمام بالورقة لمعرفة المزيد من التفاصيل.