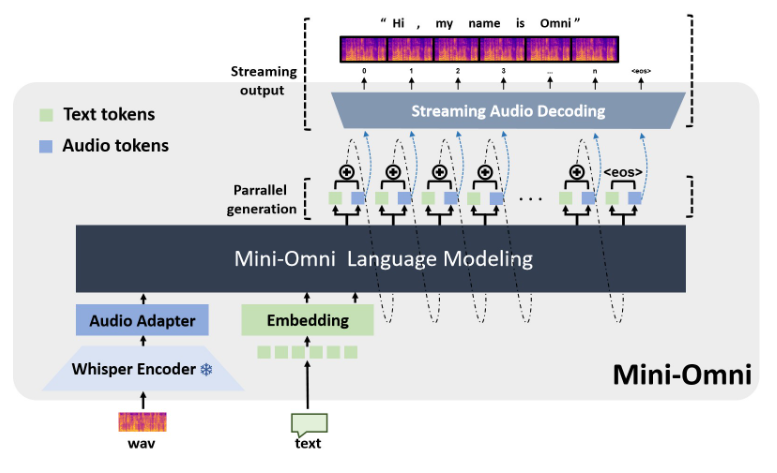
Mini-Omni هو نموذج لغة واسع النطاق ومتعدد الوسائط ومفتوح المصدر، يُحدث ثورة في تكنولوجيا التفاعل الصوتي. فهو يدمج التكنولوجيا المتقدمة لتحقيق الإدخال والإخراج الصوتي في الوقت الفعلي، ولديه القدرة على التفكير والتحدث في نفس الوقت، مما يوفر تجربة تفاعل أكثر طبيعية وسلسة بين الإنسان والكمبيوتر. تكمن الميزة الأساسية لـ Mini-Omni في إمكانيات معالجة الكلام في الوقت الفعلي من طرف إلى طرف، ولا يلزم تكوين إضافي لنماذج ASR أو TTS للاستمتاع بالمحادثات السلسة. وهو يدعم مدخلات مشروطة متعددة ويحولها بمرونة للتكيف مع مختلف السيناريوهات المعقدة وتلبية الاحتياجات المتنوعة.
اليوم، مع التطور السريع للذكاء الاصطناعي، يقود نموذج لغة واسع النطاق متعدد الوسائط مفتوح المصدر يسمى Mini-Omni ابتكار تكنولوجيا التفاعل الصوتي. نظام الذكاء الاصطناعي هذا المتكامل مع العديد من التقنيات المتقدمة لا يتيح فقط الإدخال والإخراج الصوتي في الوقت الفعلي، ولكنه يتمتع أيضًا بقدرة فريدة على التفكير والتحدث في نفس الوقت، مما يوفر للمستخدمين تجربة تفاعل طبيعية غير مسبوقة.
تكمن الميزة الأساسية لـ Mini-Omni في قدرات المعالجة الصوتية الشاملة في الوقت الفعلي. يمكن للمستخدمين الاستمتاع بالمحادثات الصوتية السلسة دون تكوين إضافي لنماذج التعرف التلقائي على الكلام (ASR) أو نماذج تحويل النص إلى كلام (TTS). يعمل هذا التصميم السلس على تحسين تجربة المستخدم بشكل كبير ويجعل التفاعل بين الإنسان والحاسوب أكثر طبيعية وبديهية.
بالإضافة إلى وظيفة الصوت، يدعم Mini-Omni أيضًا الإدخال في أوضاع متعددة مثل النص، ويمكنه التبديل بمرونة بين الأوضاع المختلفة. تسمح قدرة المعالجة متعددة الوسائط للنموذج بالتكيف مع سيناريوهات التفاعل المعقدة المختلفة وتلبية الاحتياجات المتنوعة للمستخدمين.
ومن الجدير بالذكر بشكل خاص وظيفة Mini-Omni's Any Model Can Talk. يمكّن هذا الابتكار نماذج الذكاء الاصطناعي الأخرى من دمج القدرات الصوتية في الوقت الفعلي لـ Mini-Omni بسهولة، مما يوسع بشكل كبير إمكانيات تطبيقات الذكاء الاصطناعي. وهذا لا يوفر للمطورين المزيد من الخيارات فحسب، بل يمهد الطريق أيضًا للتطبيق متعدد المجالات لتقنية الذكاء الاصطناعي.
من حيث الأداء، يظهر Mini-Omni قوته الشاملة. فهو لا يؤدي أداءً جيدًا في مهام الكلام التقليدية مثل التعرف على الكلام (ASR) وتوليد الكلام (TTS) فحسب، بل يُظهر أيضًا إمكانات قوية في المهام متعددة الوسائط التي تتطلب قدرات تفكير معقدة مثل TextQA وSpeechQA. تمكن هذه القدرة الشاملة Mini-Omni من التعامل مع مجموعة متنوعة من سيناريوهات التفاعل المعقدة، بدءًا من الأوامر الصوتية البسيطة وحتى مهام الأسئلة والأجوبة التي تتطلب تفكيرًا متعمقًا.
يتضمن التنفيذ الفني لـ Mini-Omni العديد من نماذج وتقنيات الذكاء الاصطناعي المتقدمة. يستخدم Qwen2 كأساس لنموذج لغة كبير، ويستخدم litGPT للتدريب والاستدلال، ويستخدم Whisper لتشفير الصوت، وsnac مسؤول عن فك تشفير الصوت. لا تعمل طريقة الدمج متعددة التقنيات هذه على تحسين الأداء العام للنموذج فحسب، بل تعزز أيضًا قدرته على التكيف في سيناريوهات مختلفة.
بالنسبة للمطورين والباحثين، يوفر Mini-Omni الاستخدام المريح. من خلال خطوات التثبيت البسيطة، يمكن للمستخدمين تشغيل Mini-Omni في بيئتهم المحلية وإجراء عروض توضيحية تفاعلية من خلال أدوات مثل Streamlit وGradio. توفر هذه الميزة المفتوحة وسهلة الاستخدام دعمًا قويًا لنشر تكنولوجيا الذكاء الاصطناعي وتطبيقها المبتكر.
عنوان المشروع: https://github.com/gpt-omni/mini-omni
بفضل وظائفه القوية واستخدامه المريح وميزاته مفتوحة المصدر، يوفر Mini-Omni إمكانيات جديدة في مجال التفاعل الصوتي بالذكاء الاصطناعي ويستحق اهتمام واستكشاف المطورين والباحثين. كما أن تطورها المستقبلي يستحق التطلع إليه.