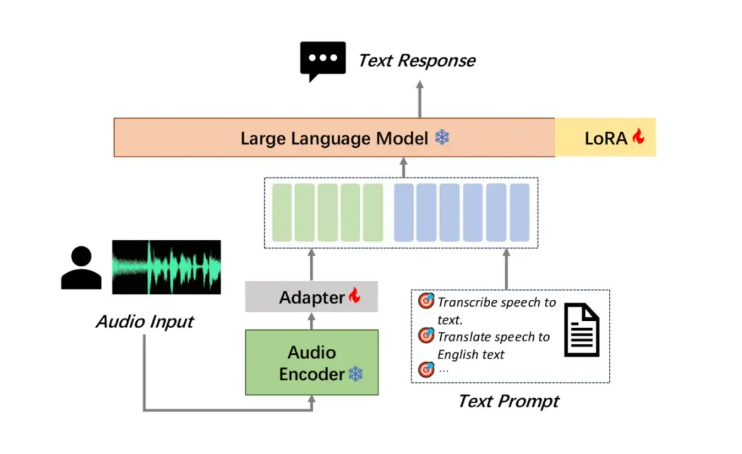
قامت شركة Moore Thread بفتح نموذجها الكبير لفهم الصوت MooER، وهو أول نموذج كلام كبير مفتوح المصدر في الصناعة يعتمد على التدريب والاستدلال على وحدة معالجة الرسومات المحلية كاملة الميزات، وهو ما يمثل علامة فارقة. يدعم MooER التعرف على الكلام الصيني والإنجليزية والترجمة الصوتية الصينية-الإنجليزية، مما يدل على قدرات معالجة قوية متعددة اللغات. يتيح هيكل النموذج المبتكر المكون من ثلاثة أجزاء (التشفير والمحول ووحدة فك التشفير) للنموذج معالجة الصوت بكفاءة وتنفيذ المهام النهائية. في الوقت الحاضر، أصبح كود الاستدلال والنموذج الذي تم تدريبه على أساس 5000 ساعة من البيانات مفتوح المصدر، وفي المستقبل، سيكون كود التدريب والنموذج المحسن الذي تم تدريبه على أساس 80000 ساعة من البيانات مفتوح المصدر، مما سيعزز التطوير بشكل كبير. تكنولوجيا الذكاء الاصطناعي الصوتي في الداخل والخارج.
كان أداء MooER جيدًا في الاختبارات المقارنة للعديد من النماذج الصوتية المعروفة مفتوحة المصدر التي تفهم النماذج الكبيرة، مع معدل خطأ في الكلمات الصينية (CER) يصل إلى 4.21% ومعدل خطأ في الكلمات الإنجليزية (WER) يبلغ 17.98%، وخاصة BLEU في اللغة الصينية. - مجموعة اختبارات الترجمة الإنجليزية تصل نتيجتها إلى 25.2، مما يجعلها رائدة في النماذج الأخرى مفتوحة المصدر. يتمتع نموذج MooER-80k الذي تم تدريبه بناءً على 80,000 ساعة من البيانات بأداء أقوى، حيث تم تخفيض CER وWER إلى 3.50% و12.66% على التوالي، مما يُظهر إمكانات كبيرة. لا تُظهر هذه الخطوة التي قام بها Moore Thread القوة القوية لوحدات معالجة الرسوميات المحلية في مجال الذكاء الاصطناعي فحسب، بل تضخ أيضًا حيوية جديدة في تطوير تقنية الذكاء الاصطناعي الصوتية العالمية. ومن المتوقع أن يحقق MooER المزيد من الاختراقات في المستقبل.
في اختبارات المقارنة مع العديد من النماذج الكبيرة المعروفة للصوت مفتوح المصدر، كان أداء MooER-5K ممتازًا. وفي الاختبار الصيني، وصل معدل خطأ الكلمات (CER) إلى 4.21%؛ وفي اختبار اللغة الإنجليزية، بلغ معدل خطأ الكلمات (WER) 17.98%، وهو أفضل أو يعادل النماذج العليا الأخرى. ومن الجدير بالذكر بشكل خاص أنه في مجموعة اختبار الترجمة الصينية-الإنجليزية Covost2zh2en، تصل درجة BLEU الخاصة بـ MooER إلى 25.2، وهي متقدمة بشكل كبير عن النماذج مفتوحة المصدر الأخرى وتصل إلى مستوى مماثل للتطبيقات على المستوى الصناعي.
والأمر الأكثر إثارة هو أن نموذج MooER-80k الذي تم تدريبه بناءً على 80 ألف ساعة من البيانات يُظهر أداءً أكثر قوة، حيث انخفض معدل خفض الانبعاثات المعتمد (CER) في مجموعة الاختبار الصينية إلى 3.50%، كما تم تحسين معدل WER (WER) في مجموعة اختبار اللغة الإنجليزية أيضًا إلى 12.66. ٪ يظهر إمكانات التنمية الضخمة.
لا يُظهر MooER مفتوح المصدر من Moore Thread قوة تطبيق وحدات معالجة الرسومات المحلية في مجال الذكاء الاصطناعي فحسب، بل يضخ أيضًا حيوية جديدة في تطوير تكنولوجيا الذكاء الاصطناعي الصوتية العالمية. نظرًا لأن المزيد من بيانات وأكواد التدريب أصبحت مفتوحة المصدر، تتوقع الصناعة أن يحقق MooER المزيد من الإنجازات في التعرف على الكلام والترجمة وغيرها من المجالات، وتعزيز تعميم تكنولوجيا الذكاء الاصطناعي الصوتي وتطبيقها المبتكر.
العنوان: https://arxiv.org/pdf/2408.05101
يشير المصدر المفتوح لـ MooER إلى أن وحدات معالجة الرسوميات المحلية قد حققت تقدمًا كبيرًا في مجال نماذج الذكاء الاصطناعي الكبيرة، مما يوفر موارد ومنصات قيمة للمطورين المحليين والأجانب. من المتوقع أن تلعب MooER دورًا في المزيد من سيناريوهات التطبيق في المستقبل وتعزيز الابتكار والتطوير المستمر لتقنية الذكاء الاصطناعي الصوتي.