أحدث نموذج كبير متعدد الوسائط للأغراض العامة من Alibaba، mPLUG-Owl3، أحدث عاصفة في مجال الذكاء الاصطناعي بفضل قدراته القوية على فهم الوسائط المتعددة وكفاءة التفكير المذهلة. يمكنه فهم ساعتين من محتوى الفيديو في 4 ثوانٍ والإجابة بدقة على الأسئلة المختلفة التي يطرحها المستخدمون، مما يدل على أداء ممتاز في فهم الصور والفيديو والنص. ولا يعد هذا التقدم التكنولوجي علامة فارقة في الأوساط الأكاديمية فحسب، بل يبشر أيضًا بتغيير مستقبلي في الطريقة التي يتفاعل بها الذكاء الاصطناعي مع البشر.
في عصر الانفجار المعلوماتي هذا، نستخدم الصور ومقاطع الفيديو لتسجيل حياتنا ومشاركة سعادتنا كل يوم. ولكن هل فكرت يومًا فيما سيحدث إذا كانت هناك تقنية تسمح للآلات ليس فقط بفهم هذه الصور ومقاطع الفيديو مثل البشر، ولكن أيضًا بالتواصل معنا بعمق؟
أحدث طراز كبير متعدد الوسائط للأغراض العامة mPLUG-Owl3 أصدره فريق Alibaba، بكفاءته المذهلة وقدرته على الفهم، يسمح لنا بمشاهدة فيلم مدته ساعتان في 4 ثوانٍ. هذا ليس مجرد نموذج، ولكنه أشبه إنه مساعد الذكاء الاصطناعي يمكنه الرؤية والاستماع والتحدث والتفكير.
mPLUG-Owl3، الاسم يبدو وكأنه بومة ترتدي نظارات، ذكية ومنتبهة. وتتمثل قدرتها الأساسية في فهم تسلسلات الصور الطويلة. سواء كان ذلك عبارة عن سلسلة من الصور أو مقاطع الفيديو، يمكنه فهم المحتوى وحتى فهم القصة.
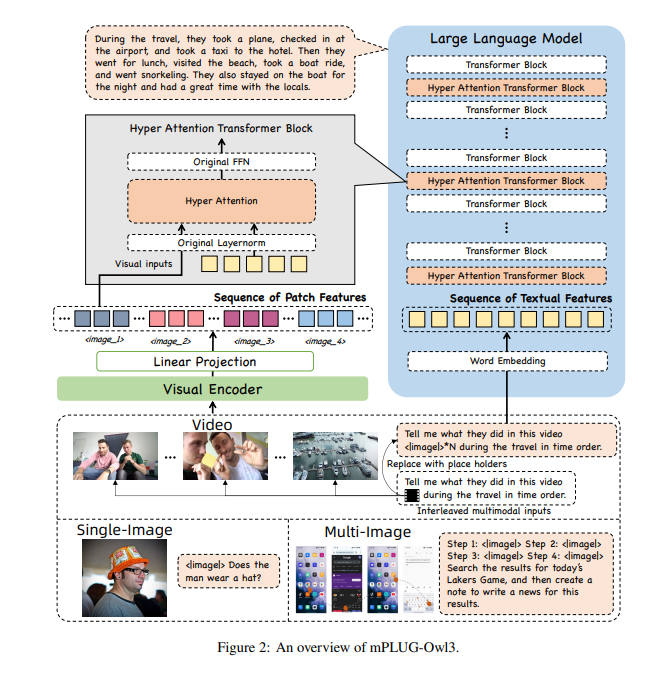
من أجل السماح لـ mPLUG-Owl3 بمعالجة الكثير من المعلومات، قام الباحثون بتزويده بوحدة فائقة الانتباه للدماغ. تشبه هذه الوحدة العقل الفائق للذكاء الاصطناعي، فهو قادر على معالجة المعلومات المرئية واللغوية في نفس الوقت، مما يسمح للذكاء الاصطناعي بفهم كل من الصور والمعلومات النصية ذات الصلة.
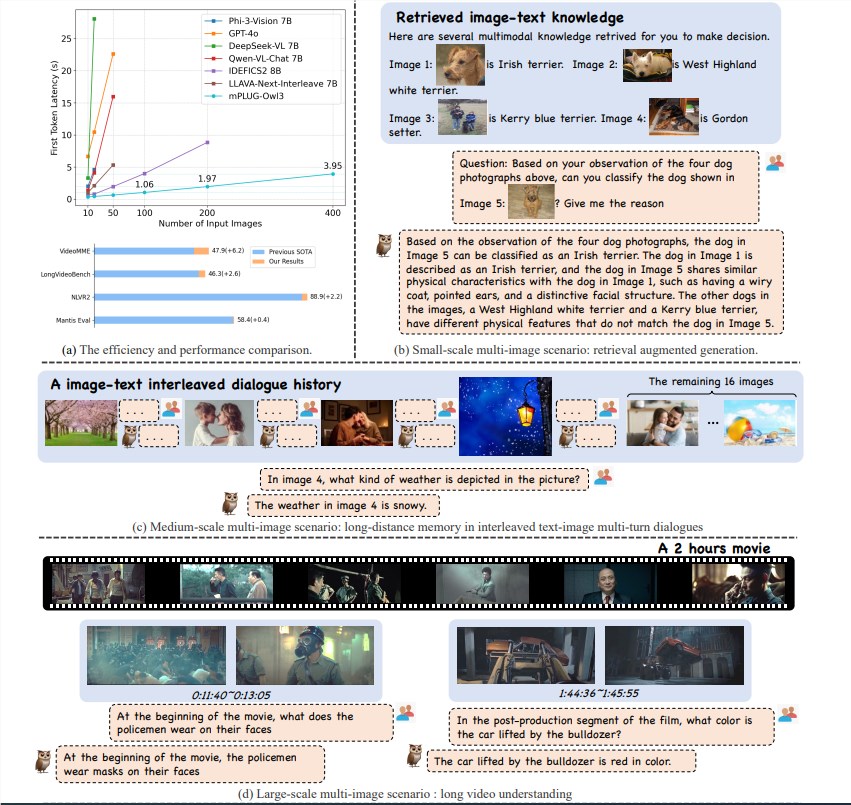
حقق نموذج mPLUG-Owl3 تقدمًا كبيرًا في مجال الفهم متعدد الوسائط بفضل كفاءته المنطقية الممتازة. إنه لا يصل فقط إلى SOTA (حالة الفن) في معايير متعددة السيناريوهات مثل الصورة الفردية، والصور المتعددة، والفيديو، وما إلى ذلك، ولكنه يقلل أيضًا من زمن وصول الرمز المميز الأول بمقدار 6 مرات، وعدد الصور التي يمكن معالجتها بواسطة بطاقة رسومية واحدة A100 تزيد بمقدار 8 مرات لتصل إلى 400 ورقة.
يمكن لـ mPLUG-Owl3 فهم المعرفة متعددة الوسائط الواردة بدقة واستخدامها للإجابة على الأسئلة. ويمكنه أيضًا أن يخبرك عن المعرفة التي يبني عليها حكمه، بالإضافة إلى الأساس التفصيلي لحكمه.
يستطيع mPLUG-Owl3 فهم علاقات المحتوى في المواد المختلفة بشكل صحيح وإجراء تفكير متعمق. سواء أكان الأمر يتعلق بالاختلافات الأسلوبية أو التعرف على الشخصيات، فإنه يتعامل مع كل ذلك بسهولة.
يستطيع mPLUG-Owl3 مشاهدة وفهم مقاطع الفيديو التي تصل مدتها إلى ساعتين ويمكنه البدء في الإجابة على أسئلة المستخدم في غضون 4 ثوانٍ، بغض النظر عن جزء الفيديو الذي يتضمنه السؤال.
يستخدم mPLUG-Owl3 وحدة Hyper Attention خفيفة الوزن لتوسيع كتلة المحولات إلى وحدة نمطية جديدة قادرة على التفاعل مع ميزات الرسم والنص ونمذجة النص. يقلل هذا التصميم بشكل كبير من عدد المعلمات الجديدة الإضافية المقدمة، مما يجعل تدريب النموذج أسهل، كما يتم تحسين كفاءة التدريب والاستدلال.
من خلال تجربة مجموعة واسعة من مجموعات البيانات، يحقق mPLUG-Owl3 نتائج SOTA في معظم المعايير القياسية متعددة الوسائط ذات الصورة الواحدة. وفي تقييمات الصور المتعددة، فإنه يتفوق على النماذج المحسنة خصيصًا لسيناريوهات الصور المتعددة. في LongVideoBench، تجاوز النماذج الحالية، وأظهر قدرته الممتازة في فهم مقاطع الفيديو الطويلة.
إن إصدار Alibaba mPLUG-Owl3 لا يمثل قفزة تكنولوجية فحسب، بل يوفر أيضًا إمكانيات جديدة لتطبيق النماذج الكبيرة متعددة الوسائط. ومع استمرار تحسن التكنولوجيا، فإننا نتطلع إلى جلب mPLUG-Owl3 المزيد من المفاجآت في المستقبل.
عنوان الورقة: https://arxiv.org/pdf/2408.04840
الكود: https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl3
التجربة عبر الإنترنت: https://huggingface.co/spaces/mPLUG/mPLUG-Owl3
يمثل ظهور mPLUG-Owl3 مرحلة جديدة في تطوير تكنولوجيا النماذج الكبيرة متعددة الوسائط، حيث تفتح قدرات المعالجة الفعالة وقدرات الفهم الدقيقة آفاقًا واسعة لتطبيقات تكنولوجيا الذكاء الاصطناعي المستقبلية. أعتقد أنه مع استمرار نضج التكنولوجيا، فإن mPLUG-Owl3 سيجلب المزيد من الراحة والمفاجآت لحياة الناس. نتطلع إلى المزيد من التطبيقات المبتكرة المعتمدة على mPLUG-Owl3.