يعد ضبط التعليمات للنماذج الكبيرة هو المفتاح لتحسين أدائها. نشرت Tencent Youtu Labs، بالتعاون مع جامعة Shanghai Jiao Tong، مراجعة تفصيلية توفر نظرة متعمقة لتقييم واختيار مجموعات بيانات ضبط التعليمات. توفر هذه المقالة الطويلة المكونة من 10000 كلمة، والتي تعتمد على أكثر من 400 وثيقة ذات صلة، إرشادات شاملة لضبط التعليمات للنماذج الكبيرة من الأبعاد الثلاثة لجودة البيانات والتنوع والأهمية، وتشير إلى تحديات البحث الحالي وآفاق التطوير المستقبلية اتجاه. تغطي المقالة مجموعة متنوعة من طرق التقييم، بما في ذلك المؤشرات المصممة يدويًا، والمؤشرات القائمة على النماذج، والتقييم التلقائي لـ GPT، والتقييم اليدوي، بهدف مساعدة الباحثين على اختيار مجموعة البيانات المثالية وتحسين أداء واستقرار النماذج الكبيرة.
مع الترقيات المتكررة المستمرة، أصبحت النماذج الكبيرة أكثر ذكاءً، ولكن بالنسبة لهم لفهم احتياجاتنا حقًا، فإن ضبط التعليمات هو المفتاح. نشر خبراء من Tencent Youtu Lab وجامعة Shanghai Jiao Tong بشكل مشترك مراجعة مكونة من 10000 كلمة تناقش بعمق تقييم واختيار مجموعات بيانات ضبط التعليمات، وكشفوا النقاب عن سر كيفية تحسين أداء النماذج الكبيرة.
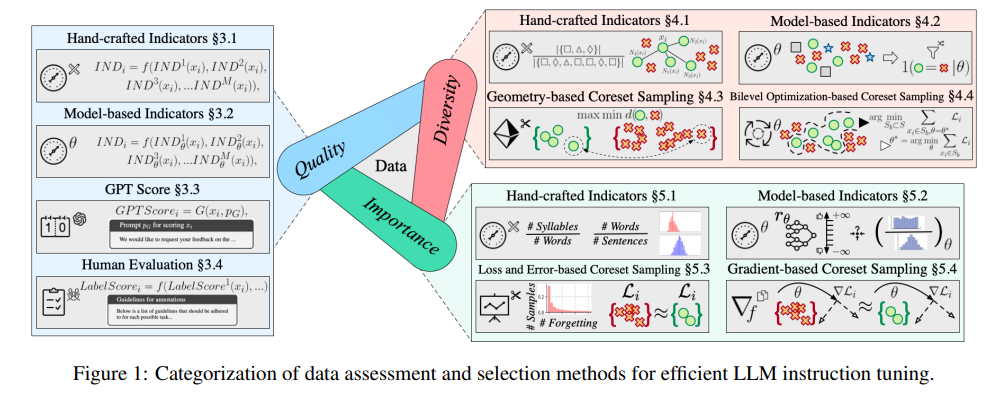
الهدف من النماذج الكبيرة هو إتقان جوهر معالجة اللغة الطبيعية، ويعد ضبط التعليمات خطوة مهمة في عملية التعلم. يقدم الخبراء تحليلاً متعمقًا لكيفية تقييم مجموعات البيانات واختيارها لضمان أداء النماذج الكبيرة بشكل جيد عبر مجموعة متنوعة من المهام.
هذه المراجعة ليست مذهلة في طولها فحسب، بل تغطي أيضًا أكثر من 400 وثيقة ذات صلة، مما يوفر لنا دليلاً مفصلاً للأبعاد الثلاثة لجودة البيانات وتنوعها وأهميتها.
تؤثر جودة البيانات بشكل مباشر على فعالية ضبط التعليمات. اقترح الخبراء مجموعة متنوعة من أساليب التقييم، بما في ذلك المؤشرات المصممة يدويًا، والمؤشرات القائمة على النماذج، والتسجيل التلقائي لـ GPT، والتقييم اليدوي الذي لا غنى عنه.
يركز تقييم التنوع على ثراء مجموعة البيانات، بما في ذلك تنوع المفردات والدلالات وتوزيع البيانات بشكل عام. ومع مجموعات البيانات المتنوعة، يمكن للنماذج تعميمها بشكل أفضل على سيناريوهات مختلفة.
تقييم الأهمية هو اختيار العينات الأكثر أهمية لنموذج التدريب. وهذا لا يؤدي إلى تحسين كفاءة التدريب فحسب، بل يضمن أيضًا استقرار النموذج ودقته عند مواجهة المهام المعقدة.
وعلى الرغم من أن الأبحاث الحالية حققت نتائج معينة، إلا أن الخبراء أشاروا أيضًا إلى التحديات القائمة، مثل ضعف الارتباط بين اختيار البيانات وأداء النموذج، وعدم وجود معايير موحدة لتقييم جودة التعليمات.
للمضي قدمًا، يدعو الخبراء إلى إنشاء معايير متخصصة لتقييم نماذج ضبط التعليمات مع تحسين إمكانية تفسير خطوط الاختيار للتكيف مع المهام النهائية المختلفة.
هذا البحث الذي أجراه Tencent Youtu Lab وجامعة Shanghai Jiao Tong لا يوفر لنا مصدرًا قيمًا فحسب، بل يشير أيضًا إلى الاتجاه لتطوير نماذج كبيرة. ومع استمرار التقدم التكنولوجي، لدينا من الأسباب ما يجعلنا نعتقد أن النماذج الكبيرة سوف تصبح أكثر ذكاءً وتخدم البشر بشكل أفضل.
عنوان الورقة: https://arxiv.org/pdf/2408.02085
يوفر هذا البحث إرشادات قيمة لضبط تعليمات النماذج الكبيرة ويضع أساسًا متينًا لتطوير النماذج الكبيرة في المستقبل. ونحن نتطلع إلى المزيد من نتائج البحوث المماثلة في المستقبل، والتي من شأنها تعزيز التقدم المستمر لتكنولوجيا النماذج الكبيرة وخدمة البشرية بشكل أفضل.