قام Tencent Youtu Lab والمؤسسات الأخرى بفتح المصدر الأول لنموذج اللغة الكبير متعدد الوسائط VITA، والذي يمكنه معالجة مقاطع الفيديو والصور والنصوص والصوت في نفس الوقت وتوفير تجربة تفاعلية سلسة. يهدف ظهور VITA إلى التعويض عن أوجه القصور في نماذج اللغة الحالية واسعة النطاق في معالجة اللهجات الصينية. استنادًا إلى نموذج Mixtral8×7B، تم توسيع المفردات الصينية وضبط التعليمات ثنائية اللغة بشكل دقيق، مما يجعلها بارعة في اللغة الإنجليزية. ويجيد اللغة الصينية. يمثل هذا تقدمًا كبيرًا لمجتمع المصادر المفتوحة في الفهم والتفاعل متعدد الوسائط.
في الآونة الأخيرة، أطلق باحثون من Tencent Youtu Lab ومؤسسات أخرى أول نموذج لغة كبير متعدد الوسائط ومفتوح المصدر VITA، والذي يمكنه معالجة مقاطع الفيديو والصور والنصوص والصوت في نفس الوقت، كما أن تجربته التفاعلية هي أيضًا من الدرجة الأولى.
تم إنشاء نموذج VITA لسد أوجه القصور في نماذج اللغات الكبيرة في معالجة اللهجات الصينية. وهو يعتمد على نموذج Mixtral8×7B القوي، والمفردات الصينية الموسعة، والتعليمات ثنائية اللغة المضبوطة بدقة، مما يجعل VITA لا يتقن اللغة الإنجليزية فحسب، بل يتقن اللغة الصينية أيضًا.
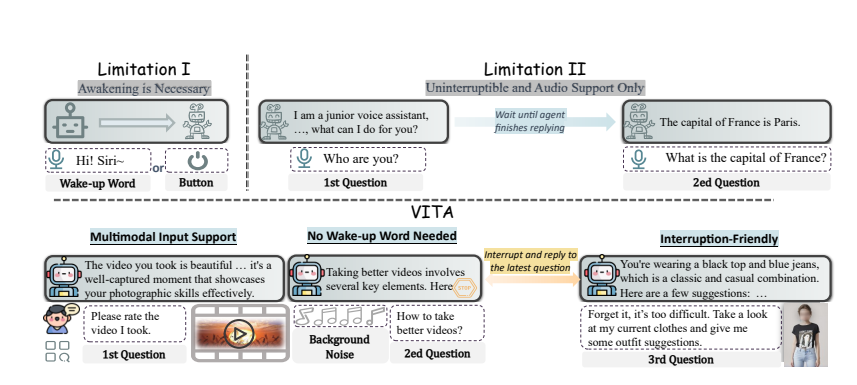
الميزات الرئيسية:
فهم متعدد الوسائط: تعد قدرة VITA على معالجة الفيديو والصور والنص والصوت غير مسبوقة بين النماذج مفتوحة المصدر.
التفاعل الطبيعي: لا داعي لقول "مرحبًا، VITA" في كل مرة، فهو يمكنه الرد في أي وقت عندما تتحدث، وحتى عندما تتحدث مع الآخرين، يمكنه أن يظل مهذبًا ولا يقاطعك حسب الرغبة.
رائد مفتوح المصدر: VITA هي خطوة مهمة لمجتمع المصادر المفتوحة في الفهم والتفاعل متعدد الوسائط، مما يضع الأساس للبحث اللاحق.
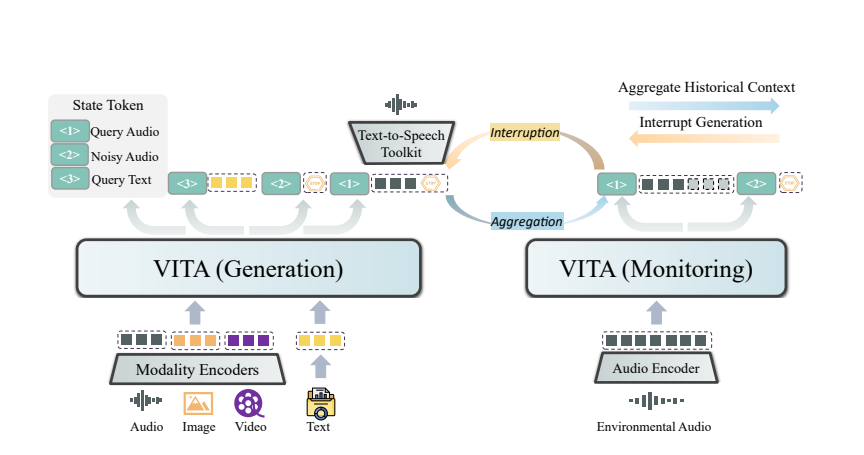
يأتي سحر VITA من نشر النموذج المزدوج. أحد النماذج مسؤول عن إنشاء استجابات لاستفسارات المستخدم، بينما يتتبع النموذج الآخر المدخلات البيئية بشكل مستمر لضمان دقة كل تفاعل وفي الوقت المناسب.
لا تستطيع VITA الدردشة فحسب، بل تعمل أيضًا كشريك دردشة عند ممارسة التمارين الرياضية، وحتى تقديم النصائح عند السفر. ويمكنه أيضًا الإجابة على الأسئلة بناءً على الصور أو محتوى الفيديو الذي تقدمه، مما يُظهر فعاليته العملية.
على الرغم من أن VITA أظهرت إمكانات كبيرة، إلا أنها لا تزال تتطور من حيث تركيب الكلام العاطفي والدعم متعدد الوسائط. ويخطط الباحثون لتمكين الجيل القادم من VITA من توليد صوت عالي الجودة من إدخال الفيديو والنص، وحتى استكشاف إمكانية توليد صوت وفيديو عالي الجودة في وقت واحد.
لا يعد المصدر المفتوح لنموذج VITA انتصارًا تقنيًا فحسب، بل يعد أيضًا ابتكارًا عميقًا في طريق التفاعل الذكي. ومع تعميق البحث، لدينا سبب للاعتقاد بأن VITA ستوفر لنا تجربة تفاعلية أكثر ذكاءً وإنسانية.
عنوان الورقة: https://arxiv.org/pdf/2408.05211
يوفر المصدر المفتوح لـ VITA اتجاهًا جديدًا لتطوير نماذج اللغات الكبيرة متعددة الوسائط، وتشير وظائفه القوية وتجربته التفاعلية المريحة إلى أن التفاعل بين الإنسان والحاسوب سيكون أكثر ذكاءً وإنسانية في المستقبل. نحن نتطلع إلى أن تحقق VITA إنجازات أكبر في المستقبل وتوفر المزيد من الراحة لحياة الناس.