أطلقت شركة علي بابا نموذجًا جديدًا للكلام مفتوح المصدر Qwen2-Audio، والذي أدى إلى تحسين كبير في التعرف على الكلام والترجمة وتحليل الصوت، حيث تجاوزت وظائفه وأدائه منتج الجيل السابق Qwen-Audio، بل وتجاوزته في العديد من الاختبارات المعيارية لـ OpenAI. كبير-v3. يدعم Qwen2-Audio عدة لغات ويوفر إصدارًا أساسيًا وإصدارًا مضبوطًا مع التعليمات، ويمكن للمستخدمين طرح الأسئلة من خلال الصوت وإجراء التعرف على المحتوى الصوتي وتحليله، مثل تحديد عمر المتحدث وعاطفته أو تحليل الأصوات المختلفة. المكونات في الصوت. يستخدم النموذج المزيد من المطالبات باللغة الطبيعية للتدريب المسبق، مما يحسن بشكل كبير قدرات الفهم والاستجابة، ويقدم وضعين للدردشة الصوتية والتحليل الصوتي لتعزيز طبيعة تفاعل المستخدم.
أطلقت علي بابا مؤخرًا نموذجًا جديدًا للكلام مفتوح المصدر Qwen2-Audio استنادًا إلى Qwen-Audio. لا يؤدي هذا النموذج أداءً جيدًا في التعرف على الكلام والترجمة وتحليل الصوت فحسب، بل يحقق أيضًا تحسينات كبيرة في الوظائف والأداء. يوفر Qwen2-Audio إصدارًا أساسيًا وإصدارًا مضبوطًا من التعليمات، ويمكن للمستخدمين طرح أسئلة على النموذج الصوتي من خلال الصوت، والتعرف على المحتوى وتحليله.
على سبيل المثال، يمكن للمستخدم أن يطلب من امرأة التحدث، ويمكن لـ Qwen2-Audio تحديد عمرها أو تحليل عواطفها؛ إذا تم إدخال صوت صاخب، فيمكن للنموذج تحليل مكونات الصوت المختلفة. يدعم Qwen2-Audio لغات متعددة بما في ذلك الصينية والكانتونية والفرنسية والإنجليزية واليابانية، مما يوفر راحة كبيرة لتطوير تطبيقات تحليل المشاعر والترجمة.
مدخل المنتج: https://top.aibase.com/tool/qwen2-audio
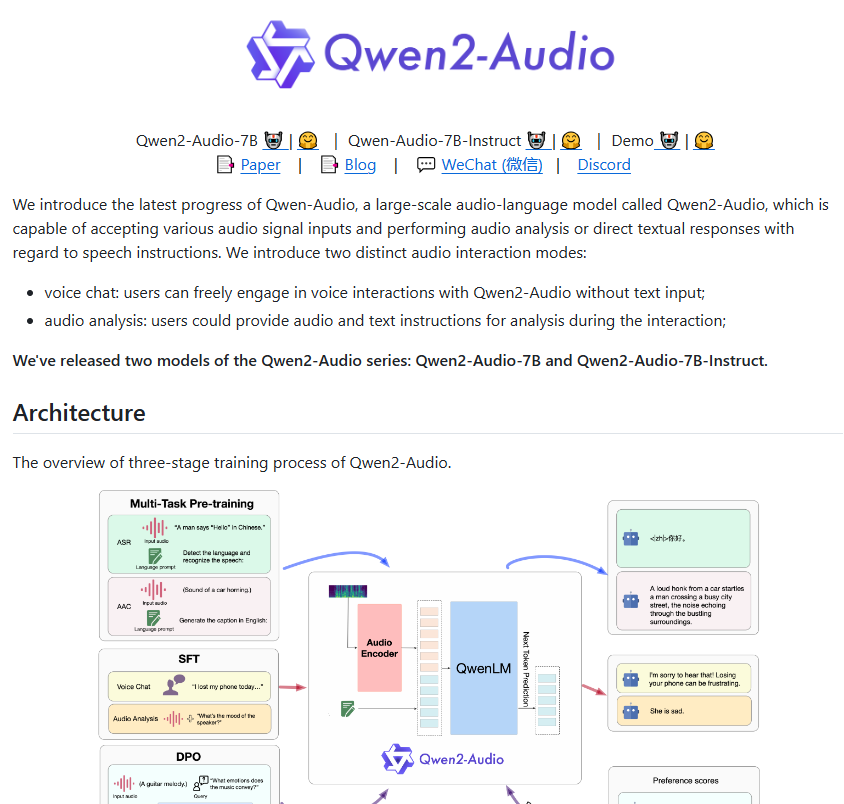
بالمقارنة مع الجيل الأول من Qwen-Audio، تم تحسين Qwen2-Audio بالكامل من حيث البنية والأداء. في مرحلة ما قبل التدريب، يستخدم هذا النموذج الجديد المزيد من إشارات اللغة الطبيعية لتحل محل التسميات الهرمية المعقدة السابقة. هذا التحسين يجعل النموذج أسهل في الفهم والاستجابة لمختلف المهام، كما تم تحسين قدرته على التعميم بشكل ملحوظ.
تم أيضًا تحسين قدرة Qwen2-Audio على متابعة الأوامر بشكل كبير، ويمكنه فهم أوامر المستخدم بشكل أكثر دقة. على سبيل المثال، عندما يصدر المستخدم الأمر "تحليل الاتجاه العاطفي في هذا الصوت"، يمكن لـ Qwen2-Audio تحديد المشاعر الموجودة في الصوت بدقة. بالإضافة إلى ذلك، يقدم النموذج وضعين: الدردشة الصوتية والتحليل الصوتي، مما يجعل التفاعل الصوتي للمستخدمين أكثر طبيعية. في وضع تحليل الصوت، يمكن لـ Qwen2-Audio تحليل أنواع مختلفة من الصوت بعمق وتقديم نتائج تحليل مفصلة ودقيقة.
للتأكد من أن مخرجات النموذج تلبي التوقعات البشرية، تقدم Qwen2-Audio أيضًا تقنيات متقدمة مثل الضبط الدقيق الخاضع للإشراف وتحسين التفضيل المباشر. تبدو النماذج أكثر طبيعية ودقة عند التفاعل مع البشر.
فيما يتعلق باختبار الأداء، كان أداء Qwen2-Audio جيدًا في العديد من الاختبارات القياسية السائدة، خاصة في دقة التعرف على الكلام والترجمة، متجاوزًا Whisper-large-v3 من OpenAI. لم يجذب أداء هذا النموذج الجديد اهتمامًا واسع النطاق في الصناعة فحسب، بل كان يبشر أيضًا بمستقبل جديد للتكنولوجيا الصوتية.
تسليط الضوء على:
Qwen2-Audio هو أحدث نموذج كلام مفتوح المصدر من Alibaba، وهو يدعم لغات متعددة ويتمتع بقدرات قوية على التعرف والتحليل.
بالمقارنة مع الجيل السابق، تم تحسين Qwen2-Audio بشكل كبير في الأداء والهندسة المعمارية، مما أدى إلى تحسين قدرته على الفهم والاستجابة.
في اختبارات الأداء المتعددة، تفوقت Qwen2-Audio على Whisper الخاص بـ OpenAI، مما أظهر قدرة تنافسية قوية.
سيعمل المصدر المفتوح لـ Qwen2-Audio على تعزيز تطوير مجال تكنولوجيا الصوت، وتزويد المطورين بأدوات قوية، وتعزيز ولادة المزيد من التطبيقات المبتكرة. إن مزاياها في الدعم والأداء متعدد اللغات تجعلها اتجاهًا مهمًا لتطوير تكنولوجيا الصوت في المستقبل. نتطلع إلى تطبيق Qwen2-Audio في المزيد من السيناريوهات.