في عصر تزداد فيه شعبية الأجهزة المحمولة والمنازل الذكية، أصبح تشغيل نماذج اللغات الكبيرة (LLM) بكفاءة حاجة ملحة. ومع ذلك، فإن موارد الحوسبة المحدودة وذاكرة الأجهزة المتطورة تصبح بمثابة اختناقات. تقدم هذه المقالة تقنية T-MAC، وهي طريقة تعتمد على جداول البحث، والتي يمكن أن تحسن بشكل كبير كفاءة تشغيل LLM منخفضة البت على الأجهزة الطرفية، مما يوفر إمكانات معالجة ذكية أكثر قوة للأجهزة الذكية، وبالتالي تحقيق مستخدم ذكي أكثر ملاءمة وأكثر كفاءة خبرة.
في هذا العصر الذي تنتشر فيه الأجهزة الذكية في كل مكان، نحن حريصون على جعل الهواتف المحمولة والأجهزة اللوحية وحتى الأجهزة المنزلية الذكية تتمتع بقدرات معالجة ذكية أكثر قوة. ومع ذلك، تتمتع هذه الأجهزة المتطورة بموارد أجهزة محدودة، خاصة الذاكرة وقوة الحوسبة، مما يحد من نشر وتشغيل نماذج اللغات الكبيرة (LLMs) عليها. تخيل كيف سيغير عالمنا إذا تمكنا من تجهيز هذه الأجهزة بنماذج قوية يمكنها فهم اللغة الطبيعية، والإجابة على الأسئلة، وحتى الإبداع؟
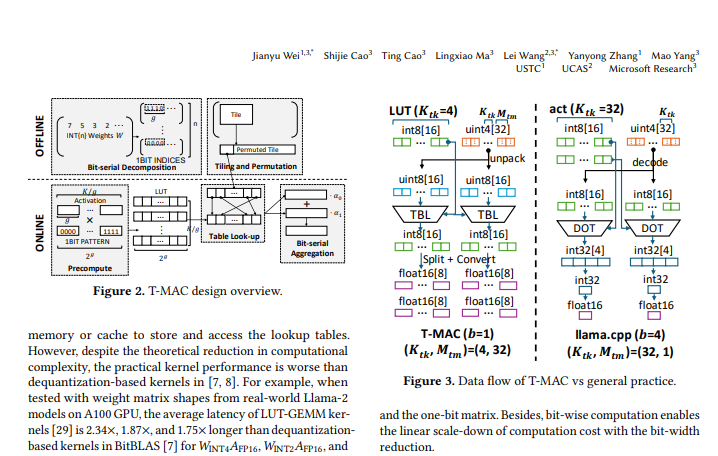
هذه هي الخلفية لميلاد تقنية T-MAC. T-MAC، الاسم الكامل لنظام MAC المستند إلى Table-Lookup، هو طريقة تعتمد على جداول البحث، والتي تسمح لنماذج اللغات الكبيرة ذات البت المنخفض بالعمل بكفاءة على وحدة المعالجة المركزية، وبالتالي تحقيق ترقيات ذكية على الأجهزة الطرفية.
غالبًا ما تحتوي نماذج اللغات الكبيرة على مليارات أو حتى عشرات المليارات من المعلمات، والتي تتطلب كميات كبيرة من الذاكرة لتخزينها. من أجل نشر هذه النماذج على الأجهزة الطرفية، نحتاج إلى تحديد أوزان النموذج، أي استخدام عدد أقل من البتات لتمثيل الأوزان، وبالتالي تقليل أثر ذاكرة النموذج. ومع ذلك، يتطلب النموذج الكمي مضاعفة المصفوفة ذات الدقة المختلطة (mpGEMM) أثناء التشغيل، وهو أمر غير شائع في أنظمة الأجهزة والبرامج الحالية ويفتقر إلى الدعم الفعال.
تتمثل الفكرة الأساسية لـ T-MAC في تحويل عمليات الضرب التقليدية القائمة على نوع البيانات إلى عمليات بحث في جدول بحث قائم على البت (LUT). هذه الطريقة لا تلغي عمليات الضرب فحسب، بل تقلل أيضًا من عمليات الجمع، وبالتالي تعمل على تحسين الكفاءة التشغيلية بشكل كبير.
وعلى وجه التحديد، يتم تنفيذ T-MAC من خلال الخطوات التالية:
قم بتحليل مصفوفة الوزن إلى مصفوفات متعددة ذات بت واحد.
قم بالحساب المسبق لمنتج متجه التنشيط بجميع أنماط البت الواحدة الممكنة وقم بتخزين النتائج في جدول بحث.
أثناء الاستدلال، يتم الحصول على نتيجة ضرب المصفوفة النهائية بسرعة من خلال فهرس جدول البحث وعمليات التراكم.
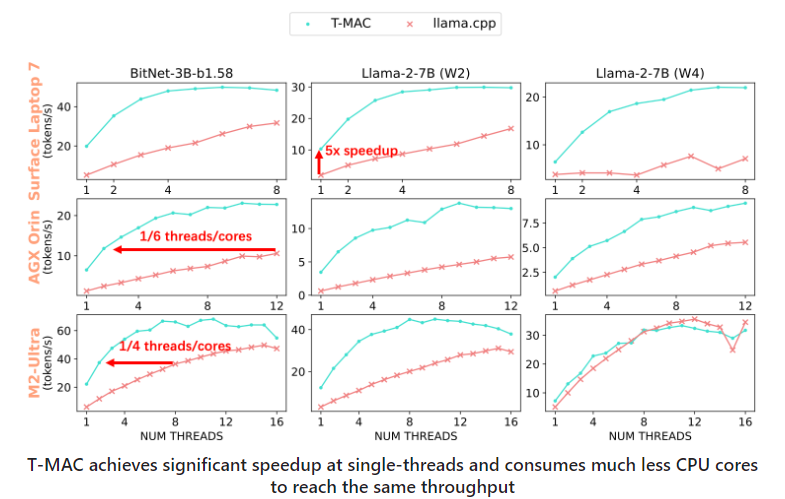
ومن خلال الاختبار على مجموعة متنوعة من الأجهزة المتطورة، أظهر T-MAC مزايا كبيرة في الأداء. بالمقارنة مع تطبيق llama.cpp الحالي، يعمل T-MAC على تحسين الإنتاجية بمقدار 4 مرات وتقليل استهلاك الطاقة بنسبة 70%. وهذا يسمح حتى للأجهزة المنخفضة الجودة، مثل Raspberry Pi5، بإنشاء الرموز بشكل أسرع من متوسط سرعة القراءة للبالغين.
لا يتمتع T-MAC بمزايا نظرية فحسب، بل يتمتع أيضًا بإمكانية التطبيقات العملية. سواء أكان الأمر يتعلق بالتعرف على الكلام في الوقت الفعلي ومعالجة اللغة الطبيعية على الهواتف الذكية، أو توفير تجربة تفاعلية أكثر ذكاءً على الأجهزة المنزلية الذكية، يمكن أن يلعب T-MAC دورًا مهمًا.
توفر تقنية T-MAC حلاً فعالاً وموفرًا للطاقة لنشر نماذج اللغات الكبيرة ذات البت المنخفض على الأجهزة الطرفية. فهو لا يمكنه تحسين مستوى ذكاء الجهاز فحسب، بل يوفر أيضًا للمستخدمين تجربة ذكية أكثر ثراءً وأكثر ملاءمة. ومع التطوير المستمر للتكنولوجيا وتحسينها، لدينا سبب للاعتقاد بأن T-MAC سيلعب دورًا متزايد الأهمية في مجال الذكاء الطرفي.
عنوان مفتوح المصدر: https://github.com/microsoft/T-MAC
عنوان الورقة: https://www.arxiv.org/pdf/2407.00088
لقد أدى ظهور تقنية T-MAC إلى تحقيق اختراقات جديدة في مجال الحوسبة المتطورة، حيث إن كفاءتها العالية وتوفيرها للطاقة تجعلها تتمتع بآفاق تطبيقية واسعة على مختلف الأجهزة الذكية. أعتقد أنه في المستقبل، سيتم تحسين T-MAC بشكل أكبر وسيساهم في بناء عالم أكثر ذكاءً وملاءمة.