تواجه نماذج اللغات الكبيرة (LLMs) تحديات في فهم النص الطويل، ويحد حجم نافذة السياق الخاصة بها من قدرات المعالجة الخاصة بها. لحل هذه المشكلة، قام الباحثون بتطوير اختبار LooGLE المعياري لتقييم قدرة فهم السياق الطويل لماجستير القانون. يحتوي LooGLE على 776 مستندًا طويلًا للغاية (متوسط 19.3 ألف كلمة) تم إصدارها بعد عام 2022 و6448 نسخة اختبار، تغطي مجالات متعددة، بهدف إجراء تقييم أكثر شمولاً لقدرة النموذج على فهم النصوص الطويلة ومعالجتها. يقوم هذا المعيار بتقييم أداء LLMs الحالي ويوفر مرجعًا قيمًا لتطوير النماذج المستقبلية.
في مجال معالجة اللغة الطبيعية، كان فهم السياق الطويل دائمًا يمثل تحديًا. على الرغم من أن نماذج اللغة الكبيرة (LLMs) تؤدي أداءً جيدًا في مجموعة متنوعة من المهام اللغوية، إلا أنها غالبًا ما تكون محدودة عند معالجة النص الذي يتجاوز حجم نافذة السياق الخاصة بها. من أجل التغلب على هذا القيد، عمل الباحثون بجد لتحسين قدرة حاملي الماجستير في القانون على فهم النصوص الطويلة، وهو أمر ليس مهمًا للبحث الأكاديمي فحسب، بل أيضًا لسيناريوهات التطبيق في العالم الحقيقي، مثل فهم المعرفة الخاصة بالمجال، والنصوص الطويلة. يعد إنشاء الحوار والقصص الطويلة أو إنشاء التعليمات البرمجية وما إلى ذلك أمرًا بالغ الأهمية أيضًا.
في هذه الدراسة، يقترح المؤلفون اختبارًا قياسيًا جديدًا - LooGLE (تقييم اللغة العام للسياق الطويل)، والذي تم تصميمه خصيصًا لتقييم قدرة فهم السياق الطويل لماجستير القانون في اللغة. يحتوي هذا المعيار على 776 مستندًا طويلًا جدًا بعد عام 2022، وتحتوي كل وثيقة على متوسط 19.3 ألف كلمة، وتحتوي على 6448 نسخة اختبار، تغطي مجالات متعددة، مثل الأكاديميين والتاريخ والرياضة والسياسة والفن والأحداث والترفيه وما إلى ذلك.
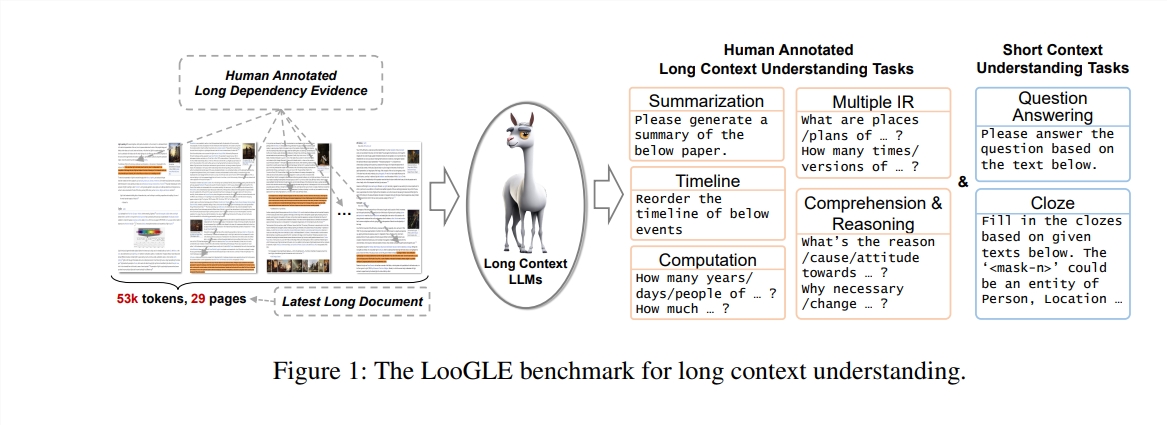
مميزات برنامج لوجل
مستندات حقيقية طويلة جدًا: يتجاوز طول المستندات في ooGLE حجم نافذة السياق الخاصة بـ LLMs، مما يتطلب أن يكون النموذج قادرًا على تذكر النص الأطول وفهمه.
مهام التبعية الطويلة والقصيرة المصممة يدويًا: يحتوي الاختبار المعياري على 7 مهام رئيسية، بما في ذلك التبعية القصيرة ومهام التبعية الطويلة، لتقييم قدرة LLM على فهم محتوى التبعيات الطويلة والقصيرة.
وثائق جديدة نسبيًا: تم إصدار جميع المستندات بعد عام 2022، مما يضمن عدم تعرض معظم حاملي شهادات الماجستير الحديثة لهذه المستندات أثناء التدريب المسبق، مما يسمح بإجراء تقييم أكثر دقة لقدراتهم على التعلم السياقي.
البيانات المشتركة عبر المجالات: تأتي البيانات المعيارية من مستندات شائعة مفتوحة المصدر، مثل أوراق arXiv ومقالات Wikipedia ونصوص الأفلام والبرامج التلفزيونية وما إلى ذلك.
أجرى الباحثون تقييماً شاملاً لثمانية ماجستير إدارة أعمال على أحدث طراز، وكشفت النتائج عن النتائج الرئيسية التالية:
يتفوق النموذج التجاري على النموذج مفتوح المصدر في الأداء.
يؤدي LLMs أداءً جيدًا في المهام ذات التبعية القصيرة ولكنه يمثل تحديات في المهام الأكثر تعقيدًا ذات التبعية الطويلة.
توفر الأساليب المعتمدة على تعلم السياق وسلاسل التفكير تحسينات محدودة فقط في فهم السياق الطويل.
تظهر التقنيات القائمة على الاسترجاع مزايا كبيرة في الإجابة على الأسئلة القصيرة، في حين أن استراتيجيات توسيع طول نافذة السياق من خلال بنية المحولات المحسنة أو التشفير الموضعي لها تأثير محدود على فهم السياق الطويل.
لا يوفر معيار LooGLE نظام تقييم منهجي وشامل لتقييم LLMs ذات السياق الطويل فحسب، بل يوفر أيضًا إرشادات للتطوير المستقبلي للنماذج التي تتمتع بقدرات "فهم حقيقي للسياق الطويل". تم نشر كافة أكواد التقييم على GitHub للرجوع إليها واستخدامها من قبل مجتمع البحث.
عنوان الورقة: https://arxiv.org/pdf/2311.04939
عنوان الرمز: https://github.com/bigai-nlco/LooGLE
يوفر معيار LooGLE أداة مهمة لتقييم وتحسين قدرات فهم النصوص الطويلة لمدارس LLM، كما أن نتائج أبحاثها لها أهمية كبيرة في تعزيز تطوير مجال معالجة اللغة الطبيعية. إن اتجاهات التحسين التي اقترحها الباحثون تستحق الاهتمام، وأعتقد أن المزيد والمزيد من برامج LLM القوية ستظهر في المستقبل للتعامل بشكل أفضل مع النصوص الطويلة.