أطلقت Apple وMeta AI معًا تقنية جديدة تسمى LazyLLM، والتي تم تصميمها لتحسين كفاءة نماذج اللغات الكبيرة (LLM) بشكل كبير في معالجة منطق النص الطويل. عندما تطالب عمليات LLM الحالية لفترة طويلة، يزداد التعقيد الحسابي لآلية الانتباه مع مربع عدد الرموز، مما يؤدي إلى بطء السرعة، خاصة في مرحلة ما قبل الشحن. يقوم LazyLLM باختيار الرموز المهمة للحساب ديناميكيًا، مما يقلل بشكل فعال من كمية العمليات الحسابية، ويقدم آلية Aux Cache لاستعادة الرموز المميزة بكفاءة، وبالتالي زيادة السرعة بشكل كبير مع ضمان الدقة.
في الآونة الأخيرة، أطلق فريق أبحاث Apple وباحثو Meta AI بشكل مشترك تقنية جديدة تسمى LazyLLM، والتي تعمل على تحسين كفاءة نماذج اللغات الكبيرة (LLM) في التفكير النصي الطويل.
كما نعلم جميعًا، غالبًا ما يواجه LLM الحالي مشاكل في السرعة البطيئة عند معالجة المطالبات الطويلة، خاصة أثناء مرحلة ما قبل الشحن. ويرجع ذلك أساسًا إلى أن التعقيد الحسابي لبنيات المحولات الحديثة عند حساب الاهتمام ينمو بشكل تربيعي مع عدد الرموز المميزة في التلميح. لذلك، عند استخدام نموذج Llama2، غالبًا ما يكون وقت حساب الرمز المميز الأول أكبر بـ 21 مرة من خطوات فك التشفير اللاحقة، وهو ما يمثل 23% من وقت الإنشاء.
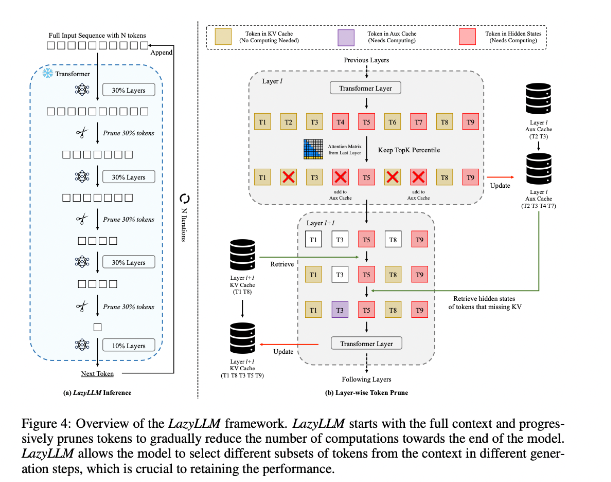
من أجل تحسين هذا الوضع، اقترح الباحثون LazyLLM، وهي طريقة جديدة لتسريع استدلال LLM عن طريق الاختيار الديناميكي لطريقة حساب الرموز المهمة. جوهر LazyLLM هو أنه يقوم بتقييم أهمية كل رمز بناءً على درجة انتباه الطبقة السابقة، وبالتالي تقليل كمية الحساب تدريجيًا. على عكس الضغط الدائم، يمكن لـ LazyLLM استعادة الرموز المميزة عند الضرورة لضمان دقة النموذج. بالإضافة إلى ذلك، يقدم LazyLLM آلية تسمى Aux Cache، والتي يمكنها تخزين الحالة الضمنية للرموز المميزة لاستعادة هذه الرموز المميزة بكفاءة ومنع تدهور الأداء.
يتفوق LazyLLM في سرعة الاستدلال، خاصة في مراحل التعبئة المسبقة وفك التشفير. المزايا الثلاثة الرئيسية لهذه التقنية هي أنها متوافقة مع أي LLM قائم على المحولات، ولا تتطلب إعادة تدريب النموذج أثناء التنفيذ، وتؤدي بشكل فعال للغاية في مجموعة متنوعة من المهام اللغوية. تسمح استراتيجية التقليم الديناميكية لـ LazyLLM بتقليل مقدار العمليات الحسابية بشكل كبير مع الاحتفاظ بالرموز الأكثر أهمية، وبالتالي زيادة سرعة التوليد.
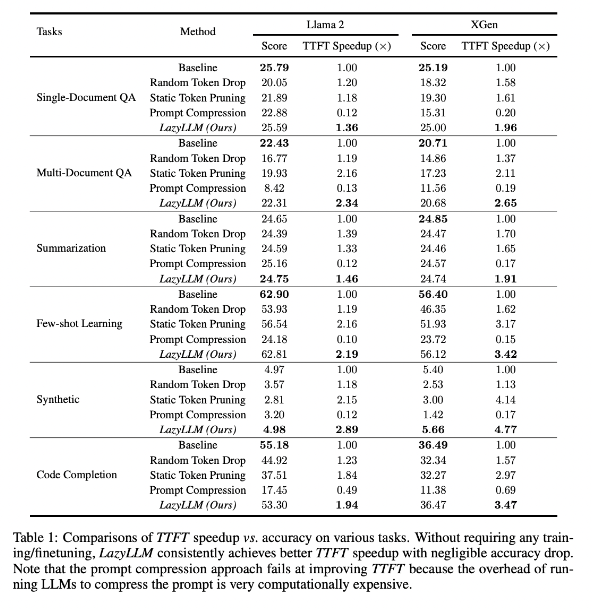
تظهر نتائج الأبحاث أن أداء LazyLLM جيدًا في المهام اللغوية المتعددة، مع زيادة سرعة TTFT بمقدار 2.89 مرة (لـ Llama2) و4.77 مرة (لـ XGen)، في حين أن الدقة تقريبًا نفس خط الأساس. سواء أكان الأمر يتعلق بالإجابة على الأسئلة أو إنشاء الملخص أو مهام إكمال التعليمات البرمجية، يمكن لـ LazyLLM تحقيق سرعة إنشاء أسرع وتحقيق توازن جيد بين الأداء والسرعة. إن إستراتيجية التقليم التقدمية الخاصة بها إلى جانب التحليل طبقة تلو الأخرى تضع الأساس لنجاح LazyLLM.
عنوان الورقة: https://arxiv.org/abs/2407.14057
أبرز النقاط:
يعمل LazyLLM على تسريع عملية التفكير في LLM عن طريق الاختيار الديناميكي للرموز المهمة، خاصة في سيناريوهات النصوص الطويلة.
يمكن لهذه التقنية تحسين سرعة الاستدلال بشكل كبير، ويمكن زيادة سرعة TTFT بما يصل إلى 4.77 مرة، مع الحفاظ على الدقة العالية.
لا يتطلب LazyLLM تعديلات على النماذج الموجودة، وهو متوافق مع أي LLM قائم على المحول، كما أنه سهل التنفيذ.
وبشكل عام، فإن ظهور LazyLLM يوفر أفكارًا جديدة وحلولًا فعالة لحل مشكلة كفاءة التفكير في النصوص الطويلة LLM، ويشير أدائها الممتاز في السرعة والدقة إلى أنها ستلعب دورًا مهمًا في تطبيقات النماذج الكبيرة المستقبلية. تتمتع هذه التكنولوجيا بآفاق تطبيق واسعة وتستحق التطلع إلى مزيد من التطوير والتطبيق.