أصدرت Apple، بالتعاون مع جامعة واشنطن ومؤسسات أخرى، نموذجًا لغويًا قويًا يسمى DCLM كمصدر مفتوح، بحجم معلمة يبلغ 700 مليون وكمية مذهلة من بيانات التدريب تصل إلى 2.5 تريليون رمز بيانات. لا يعد DCLM مجرد نموذج لغة فعال، ولكن الأهم من ذلك أنه يوفر أداة تسمى "منافسة مجموعة البيانات" (DataComp) لتحسين مجموعة البيانات الخاصة بنموذج اللغة. لا يعمل هذا الابتكار على تحسين أداء النموذج فحسب، بل يوفر أيضًا أساليب ومعايير جديدة لأبحاث نماذج اللغة، الأمر الذي يستحق الاهتمام.
ومؤخرًا، تعاون فريق الذكاء الاصطناعي التابع لشركة Apple مع العديد من المؤسسات مثل جامعة واشنطن لإطلاق نموذج لغة مفتوح المصدر يسمى DCLM. يحتوي هذا النموذج على 700 مليون معلمة ويستخدم ما يصل إلى 2.5 تريليون رمز مميز للبيانات أثناء التدريب لمساعدتنا على فهم اللغة وتوليدها بشكل أفضل.
إذًا، ما هو نموذج اللغة؟ ببساطة، هو برنامج يمكنه تحليل اللغة وتوليدها، مما يساعدنا على إكمال المهام المختلفة مثل الترجمة وتوليد النص وتحليل المشاعر. ولكي تؤدي هذه النماذج أداءً أفضل، نحتاج إلى مجموعات بيانات عالية الجودة. ومع ذلك، فإن الحصول على هذه البيانات وتنظيمها ليس بالمهمة السهلة لأننا نحتاج إلى تصفية المحتوى غير ذي الصلة أو الضار وإزالة المعلومات المكررة.
ولمواجهة هذا التحدي، أطلق فريق بحث Apple DataComp for Language Models (DCLM)، وهي أداة لتحسين مجموعة البيانات لنماذج اللغة. لقد قاموا مؤخرًا بفتح مصدر نموذج DCIM ومجموعة البيانات على منصة Hugging Face. تشمل الإصدارات مفتوحة المصدر DCLM-7B، وDCLM-1B، وdclm-7b-it، وDCLM-7B-8k، وdclm-baseline-1.0، وdclm-baseline-1.0-parquet. ويمكن للباحثين إجراء عدد كبير من التجارب من خلال هذه المنصة وإيجاد أفضل الحلول الفعالة لمجادلة البيانات.
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
القوة الأساسية لـ DCLM هي سير العمل المنظم. يمكن للباحثين اختيار نماذج بأحجام مختلفة حسب احتياجاتهم، تتراوح من 412 مليون إلى 700 مليون معلمة، ويمكنهم أيضًا تجربة طرق مختلفة لتنظيم البيانات، مثل إلغاء البيانات المكررة والتصفية. ومن خلال هذه التجارب المنهجية، يمكن للباحثين تقييم جودة مجموعات البيانات المختلفة بوضوح. وهذا لا يضع الأساس للبحث المستقبلي فحسب، بل يساعدنا أيضًا على فهم كيفية تحسين أداء النموذج من خلال تحسين مجموعة البيانات.
على سبيل المثال، باستخدام مجموعة البيانات المعيارية التي أنشأتها DCLM، قام فريق البحث بتدريب نموذج لغة يحتوي على 700 مليون معلمة، وحقق دقة 5 لقطات بنسبة 64% في اختبار MMLU المعياري، وهو تحسن بنسبة 6.6 مقارنة بالاختبار السابق أعلى مستوى من النقاط ويستخدم موارد حوسبة أقل بنسبة 40%. أداء النموذج الأساسي DCLM يمكن مقارنته أيضًا بـ Mistral-7B-v0.3 وLlama38B، اللذين يتطلبان المزيد من موارد الحوسبة.
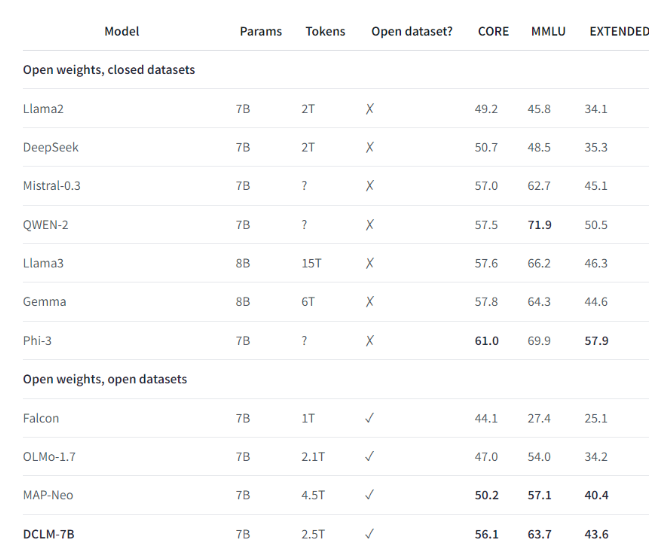
يوفر إطلاق DCLM معيارًا جديدًا لأبحاث نماذج اللغة، مما يساعد العلماء على تحسين أداء النموذج بشكل منهجي مع تقليل موارد الحوسبة المطلوبة.
أبرز النقاط:
1️⃣ تعاونت Apple AI مع مؤسسات متعددة لإطلاق DCLM، مما أدى إلى إنشاء نموذج لغة قوي مفتوح المصدر.
2️⃣ يوفر DCLM أدوات موحدة لتحسين مجموعة البيانات لمساعدة الباحثين على إجراء تجارب فعالة.
3️⃣ يحقق النموذج الجديد تقدمًا كبيرًا في الاختبارات المهمة مع تقليل متطلبات الموارد الحسابية.
بشكل عام، ضخ المصدر المفتوح لـ DCLM حيوية جديدة في مجال أبحاث نماذج اللغة، ومن المتوقع أن يؤدي نموذجها الفعال وأدوات تحسين مجموعة البيانات إلى تعزيز التطوير الأسرع في هذا المجال وتعزيز ولادة نماذج لغوية أكثر قوة وكفاءة. في المستقبل، نتوقع أن يحقق DCLM نتائج بحثية أكثر إثارة للدهشة.