أصدر باحثو مايكروسوفت إطار عمل جديد للذكاء الاصطناعي يسمى Auto Evol-Instruct والذي يمكنه تطوير مجموعات بيانات التوجيه تلقائيًا دون أي تدخل بشري. وهذا له أهمية كبيرة لتحسين قدرة نماذج اللغة الكبيرة (LLMs) على اتباع التعليمات المعقدة. تعتمد الأساليب التطورية التقليدية على قواعد مصممة بشكل مصطنع، وهي غير فعالة ويصعب التكيف مع المهام الجديدة. من ناحية أخرى، يقوم Auto Evol-Instruct بتحليل التعليمات تلقائيًا من خلال LLMs، وتصميم قواعد التطور وتحسينها بشكل مستقل، وتحقيق عملية تطور آلية وفعالة، وتحسين تعقيد مجموعات البيانات وتنوعها بشكل كبير.
في الآونة الأخيرة، اقترح باحثو مايكروسوفت إطار عمل جديد للذكاء الاصطناعي يسمى Auto Evol-Instruct، والذي يمكنه تطوير مجموعات بيانات التوجيه تلقائيًا دون أي تدخل بشري.
في مجال الذكاء الاصطناعي، يعد تطوير نماذج اللغات الكبيرة (LLMs) أمرًا بالغ الأهمية، خاصة في تحسين قدرة هذه النماذج على اتباع التعليمات التفصيلية. يستكشف الباحثون كيفية تحسين مجموعات البيانات المستخدمة لتدريب LLMs لتحسين أداء النماذج وقدرتها على التكيف.
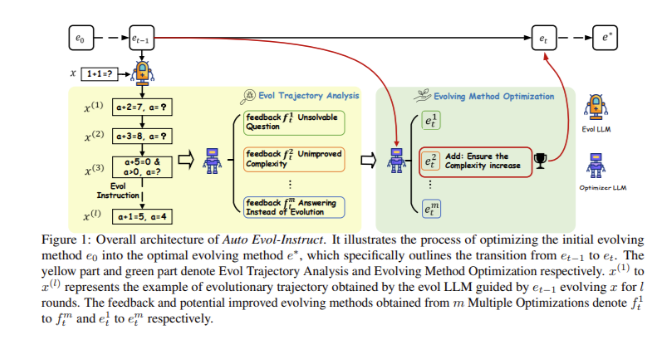
تعتمد أساليب التطور التقليدية مثل Evol-Instruct على قواعد التطور التي يحددها الخبراء البشريون، وهي ليست مكلفة وتستغرق وقتًا طويلاً فحسب، ولكنها تتطلب أيضًا إعادة تصميم الطريقة عند التكيف مع المهام الجديدة. في المقابل، تدرك Auto Evol-Instruct عملية التطور الآلي من خلال استخدام LLMs أولاً لتحليل تعليمات الإدخال وتصميم الطريقة الأولية لقواعد التطور بشكل مستقل. بعد ذلك، يتم تحسين طريقة التطور بشكل متكرر من خلال LLM المُحسّن لتحديد المشكلات وحلها أثناء عملية التطوير لضمان تعقيد واستقرار تعليمات التطور النهائية.
يستخدم Auto Evol-Instruct شهادات LLM لتصميم أساليب التطور من خلال التحليل التلقائي لتعليمات الإدخال وصياغة قواعد التطور، وبالتالي زيادة تعقيد مجموعات البيانات وتنوعها.
فيما يتعلق بتقييم الأداء، فإن أداء Auto Evol-Instruct جيد في اختبارات قياس الأداء المتعددة. على سبيل المثال، من خلال الضبط الدقيق لـ Mixtral-8x7B باستخدام بيانات ShareGPT المتطورة 10K فقط، حقق الإطار 8.09 نقطة على MT-Bench و91.4 نقطة على AlpacaEval، متجاوزًا GPT-3.5-Turbo وWizardLM-70B، ويتنافس مع Claude2.0. مقابل.
علاوة على ذلك، باستخدام بيانات تدريب GSM8K المطورة 7K فقط، يحقق الإطار 82.49 نقطة على GSM8K. فيما يتعلق بإنشاء التعليمات البرمجية، من خلال الضبط الدقيق لـ DeepSeek-Coder-Base-33B باستخدام Code Alpaca المتطور 20K، يحقق الإطار درجة 82.49. HumanEval حقق درجة 77.4، متجاوزًا النماذج المنافسة الأخرى.
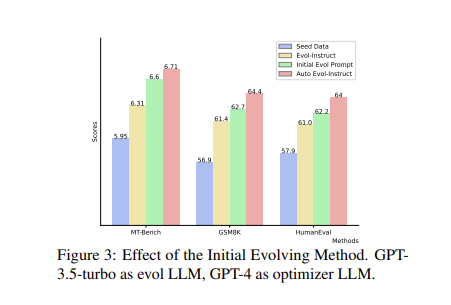
ويمكن ملاحظة أن هذا الإطار الجديد كان أداؤه جيدًا في اختبارات قياس الأداء المتعددة، بما في ذلك MT-Bench وAlpacaEval وGSM8K وHumanEval، مما يدل على قدرته على تحسين متابعة التعليمات والتفكير الرياضي وقدرات توليد التعليمات البرمجية.
عنوان الورقة: https://arxiv.org/abs/2406.00770
أبرز النقاط:
Auto Evol-Instruct هو إطار عمل تلقائي بالكامل للذكاء الاصطناعي يمكنه تحليل مجموعات بيانات التوجيه وتطويرها تلقائيًا دون تدخل بشري.
يعمل الإطار بشكل فعال على زيادة تعقيد مجموعات البيانات وتنوعها من خلال تحسين طريقة التطور، وبالتالي تعزيز الأداء والقدرة على التكيف لـ LLMs في مختلف المهام.
توضح نتائج Auto Evol-Instruct طريقة لتوجيه تطور مجموعات البيانات من خلال الأتمتة.
يمثل ظهور إطار عمل Auto Evol-Instruct ابتكارًا كبيرًا في طريقة تطوير بيانات تدريب LLMs وستعمل ميزاته الآلية والفعالة على تعزيز تطوير LLMs بشكل كبير وتوفير دعم قوي لبناء نماذج ذكاء اصطناعي أكثر قوة وقدرة على التكيف. تم نشر الأبحاث ذات الصلة، ويمكن للقراء المهتمين دراستها بعمق.