أصدر فريق Alibaba Tongyi Qianwen سلسلة Qwen2 من النماذج مفتوحة المصدر. تتضمن هذه السلسلة 5 أحجام من نماذج التدريب المسبق والتعليمات الدقيقة، وقد تم تحسين عدد المعلمات والأداء بشكل ملحوظ مقارنة بالجيل السابق من Qwen1.5. كما حققت سلسلة Qwen2 طفرة كبيرة في قدرات اللغات المتعددة، حيث تدعم 27 لغة أخرى غير الإنجليزية والصينية. من حيث فهم اللغة الطبيعية والترميز والقدرات الرياضية وما إلى ذلك، فإن النموذج الكبير (70B+ المعلمات) يعمل بشكل جيد، وخاصة نموذج Qwen2-72B، الذي يتفوق على الجيل السابق في الأداء وعدد المعلمات. يمثل هذا الإصدار ارتفاعًا جديدًا في تكنولوجيا الذكاء الاصطناعي، مما يوفر إمكانيات أوسع لتطبيق الذكاء الاصطناعي وتسويقه عالميًا.
في وقت مبكر من هذا الصباح، أصدر فريق Alibaba Tongyi Qianwen سلسلة Qwen2 من النماذج مفتوحة المصدر. تتضمن هذه السلسلة من النماذج 5 أحجام من النماذج المدربة مسبقًا والتعليمات الدقيقة: Qwen2-0.5B، Qwen2-1.5B، Qwen2-7B، Qwen2-57B-A14B وQwen2-72B. تظهر المعلومات الأساسية أن عدد المعلمات وأداء هذه النماذج قد تم تحسينه بشكل ملحوظ مقارنة بالجيل السابق Qwen1.5.
بالنسبة للقدرات المتعددة اللغات للنموذج، استثمرت سلسلة Qwen2 الكثير من الجهد في زيادة كمية ونوعية مجموعة البيانات، والتي تغطي 27 لغة أخرى باستثناء الإنجليزية والصينية. بعد الاختبار المقارن، كان أداء النموذج الكبير (70B + المعلمات) جيدًا في فهم اللغة الطبيعية والترميز والقدرات الرياضية وما إلى ذلك. وقد تجاوز نموذج Qwen2-72B الجيل السابق من حيث الأداء وعدد المعلمات.
لا يُظهر نموذج Qwen2 قدرات قوية في تقييم نموذج اللغة الأساسي فحسب، بل يحقق أيضًا نتائج مبهرة في تقييم نموذج ضبط التعليمات. تؤدي قدراتها المتعددة اللغات أداءً جيدًا في الاختبارات المعيارية مثل M-MMLU وMGSM، مما يوضح الإمكانات القوية لنموذج ضبط تعليمات Qwen2.
تمثل نماذج سلسلة Qwen2 التي تم إصدارها هذه المرة ارتفاعًا جديدًا في تكنولوجيا الذكاء الاصطناعي، مما يوفر إمكانيات أوسع لتطبيقات الذكاء الاصطناعي العالمية وتسويقها. وبالتطلع إلى المستقبل، ستعمل Qwen2 على توسيع نطاق النموذج وقدرات الوسائط المتعددة لتسريع عملية تطوير مجال الذكاء الاصطناعي مفتوح المصدر.
معلومات النموذجتتضمن سلسلة Qwen2 5 أحجام من النماذج الأساسية والمضبوطة حسب الأوامر، بما في ذلك Qwen2-0.5B، وQwen2-1.5B، وQwen2-7B، وQwen2-57B-A14B، وQwen2-72B. نوضح المعلومات الأساسية لكل نموذج في الجدول أدناه:
نموذج Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B # المعلمة 049 مليون 154 مليون 707B57.41B72.71B # المعلمة غير Ember 035 مليون 131B598 مليون 5632 مليون 7021B ضمان الجودة هو حقًا حقًا من الارتباط الحقيقي الحقيقي المضمن صحيح صحيح خطأ خطأ خطأ خطأ طول السياق 32 ألف 32 ألف 128 ألف 64 ألف 128 ألفعلى وجه التحديد، في Qwen1.5، استخدم Qwen1.5-32B وQwen1.5-110B فقط انتباه الاستعلام الجماعي (GQA). هذه المرة، قمنا بتطبيق GQA على جميع أحجام النماذج حتى يتمكنوا من الاستمتاع بفوائد السرعات الأعلى وبصمة الذاكرة الأصغر في استنتاج النموذج. بالنسبة للنماذج الصغيرة، نفضل تطبيق التضمينات المربوطة لأن التضمينات المتفرقة الكبيرة تمثل جزءًا كبيرًا من إجمالي معلمات النموذج.
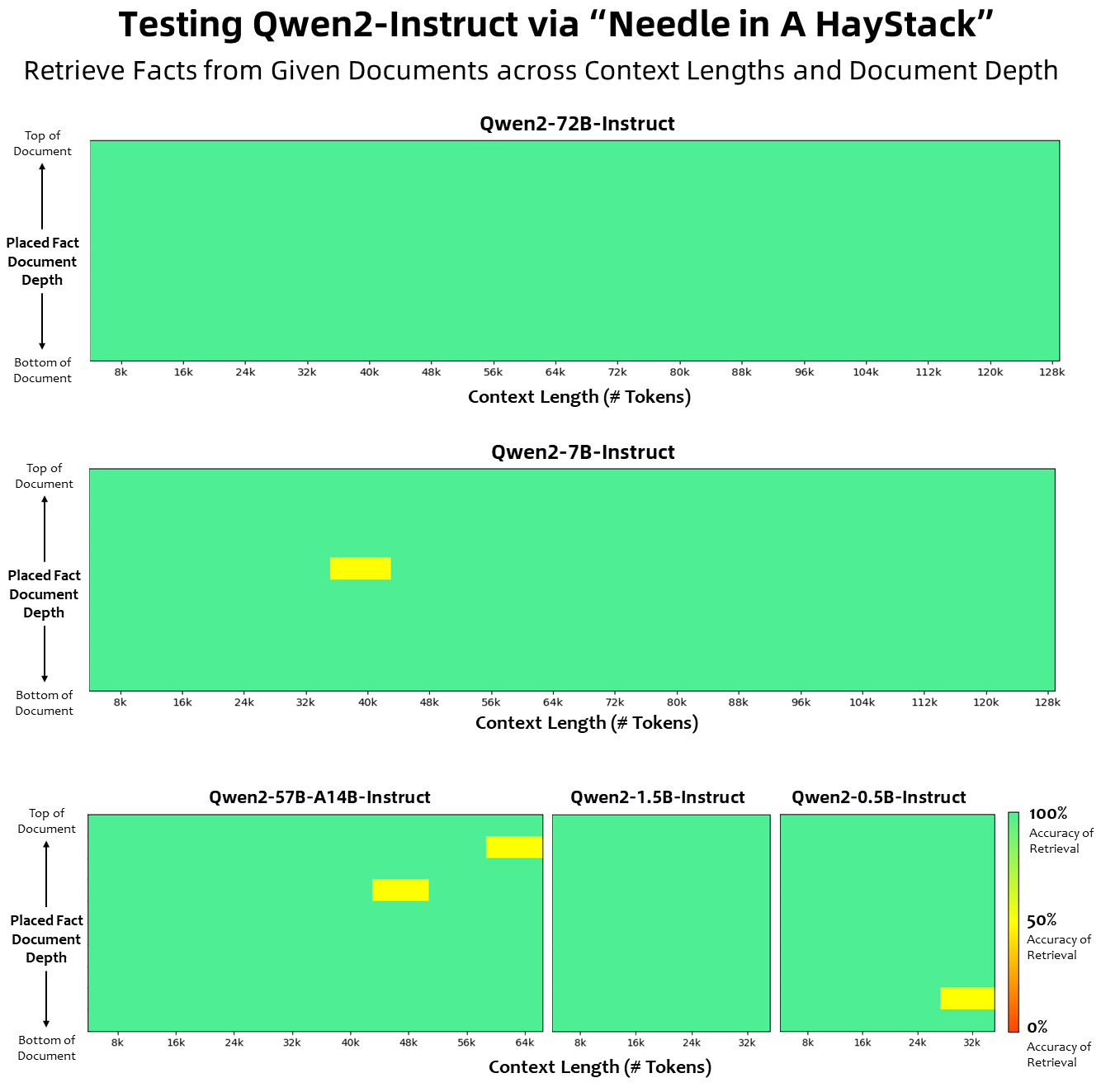
فيما يتعلق بطول السياق، تم تدريب جميع نماذج اللغة الأساسية مسبقًا على بيانات طول السياق لـ 32 ألف رمز مميز، ولاحظنا قدرات استقراء مرضية تصل إلى 128 ألفًا في تقييم PPL. ومع ذلك، بالنسبة للنماذج التي تم ضبطها للتعليمات، فإننا لسنا راضين عن تقييم PPL فقط؛ فنحن بحاجة إلى النموذج ليكون قادرًا على فهم السياق الطويل بشكل صحيح وإكمال المهمة. في الجدول، ندرج إمكانات طول السياق لنموذج ضبط التعليمات، كما تم تقييمها من خلال التقييم في مهمة Needlein a Haystack. تجدر الإشارة إلى أنه عند تعزيزها باستخدام YARN، يُظهر كل من طرازي Qwen2-7B-Instruct وQwen2-72B-Instruct قدرات مذهلة ويمكنهما التعامل مع أطوال سياق تصل إلى 128 ألف رمز مميز.
لقد بذلنا جهودًا كبيرة لزيادة كمية ونوعية مجموعات البيانات قبل التدريب والتعليمات المضبوطة التي تغطي لغات متعددة بخلاف الإنجليزية والصينية لتعزيز قدراتها المتعددة اللغات. على الرغم من أن النماذج اللغوية الكبيرة لديها القدرة الكامنة على التعميم على اللغات الأخرى، إلا أننا نؤكد صراحةً على إدراج 27 لغة أخرى في تدريبنا:
اللغات الإقليمية أوروبا الغربية الألمانية، الفرنسية، الإسبانية، البرتغالية، الإيطالية، الهولندية شرق ووسط أوروبا الروسية، التشيكية، البولندية الشرق الأوسط العربية، الفارسية، العبرية، التركية شرق آسيا اليابانية، الكورية جنوب شرق آسيا الفيتنامية، التايلاندية، الإندونيسية، الملايو، لاو، البورمية، السيبيونو، الخمير، التاغالوغية، جنوب آسيا الهندية، البنغالية، الأرديةبالإضافة إلى ذلك، فإننا نبذل جهدًا كبيرًا في حل مشكلات تحويل الشفرة التي غالبًا ما تنشأ في التقييمات متعددة اللغات. ولذلك، تم تحسين قدرة نموذجنا على التعامل مع هذه الظاهرة بشكل ملحوظ. أكدت التقييمات التي تستخدم الإشارات التي تستلزم عادةً التبديل بين اللغات، حدوث انخفاض كبير في المشكلات ذات الصلة.
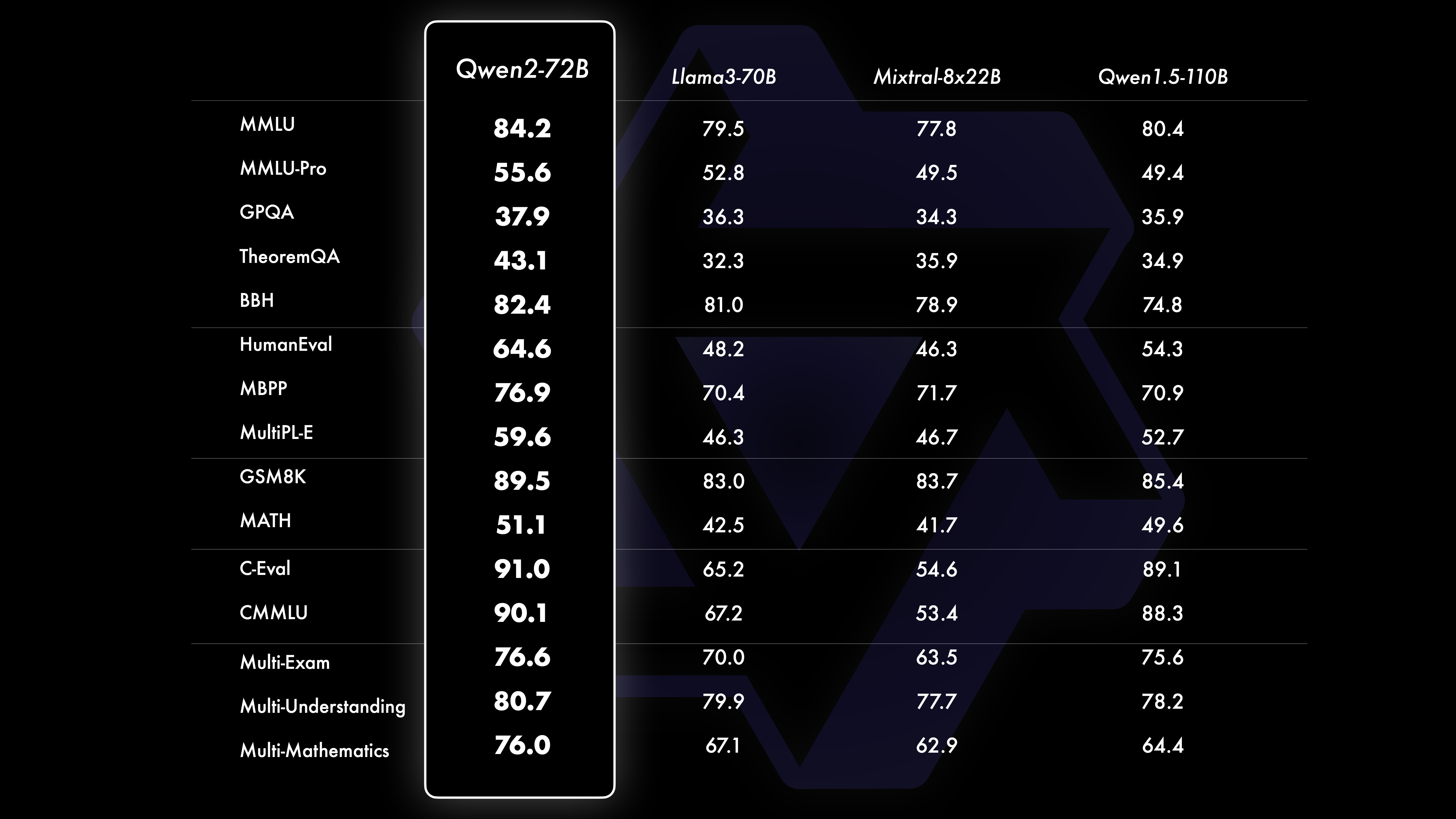
أداءتظهر نتائج الاختبار المقارن أن أداء النموذج واسع النطاق (70B+ معلمات) قد تحسن بشكل ملحوظ مقارنة بـ Qwen1.5. تركز هذا الاختبار على النموذج واسع النطاق Qwen2-72B. ومن حيث نماذج اللغة الأساسية، قمنا بمقارنة أداء Qwen2-72B وأفضل النماذج المفتوحة الحالية من حيث فهم اللغة الطبيعية واكتساب المعرفة وقدرات البرمجة والقدرات الرياضية وقدرات اللغات المتعددة وغيرها من القدرات. بفضل مجموعات البيانات المختارة بعناية وطرق التدريب المحسنة، يتفوق Qwen2-72B على النماذج الرائدة مثل Llama-3-70B، بل ويتفوق على الجيل السابق Qwen1.5- مع عدد أقل من المعلمات 110B.
بعد تدريب مسبق واسع النطاق، نقوم بإجراء ما بعد التدريب لزيادة تعزيز ذكاء كوين وجعله أقرب إلى البشر. تعمل هذه العملية على تحسين قدرات النموذج في مجالات مثل الترميز والرياضيات والاستدلال ومتابعة التعليمات والفهم متعدد اللغات. علاوة على ذلك، فإنه يعمل على مواءمة مخرجات النموذج مع القيم الإنسانية، مما يضمن أنه مفيد وصادق وغير ضار. تم تصميم مرحلة ما بعد التدريب لدينا وفقًا لمبادئ التدريب القابل للتطوير والحد الأدنى من التعليقات التوضيحية البشرية. على وجه التحديد، ندرس كيفية الحصول على بيانات العرض التقديمي وبيانات التفضيلات عالية الجودة وموثوقة ومتنوعة وإبداعية من خلال استراتيجيات المحاذاة التلقائية المختلفة، مثل أخذ عينات الرفض للرياضيات، وردود الفعل على التنفيذ للبرمجة ومتابعة التعليمات، والترجمة العكسية للكتابة الإبداعية ، والإشراف على لعب الأدوار، وأكثر من ذلك. أما بالنسبة للتدريب، فإننا نستخدم مزيجًا من الضبط الدقيق الخاضع للإشراف، والتدريب على نماذج المكافآت، وتدريب DPO عبر الإنترنت. نحن نستخدم أيضًا مُحسِّنًا جديدًا للدمج عبر الإنترنت لتقليل ضرائب المحاذاة. تعمل هذه الجهود المشتركة على تحسين قدرات وذكاء نماذجنا بشكل كبير، كما هو موضح في الجدول أدناه.
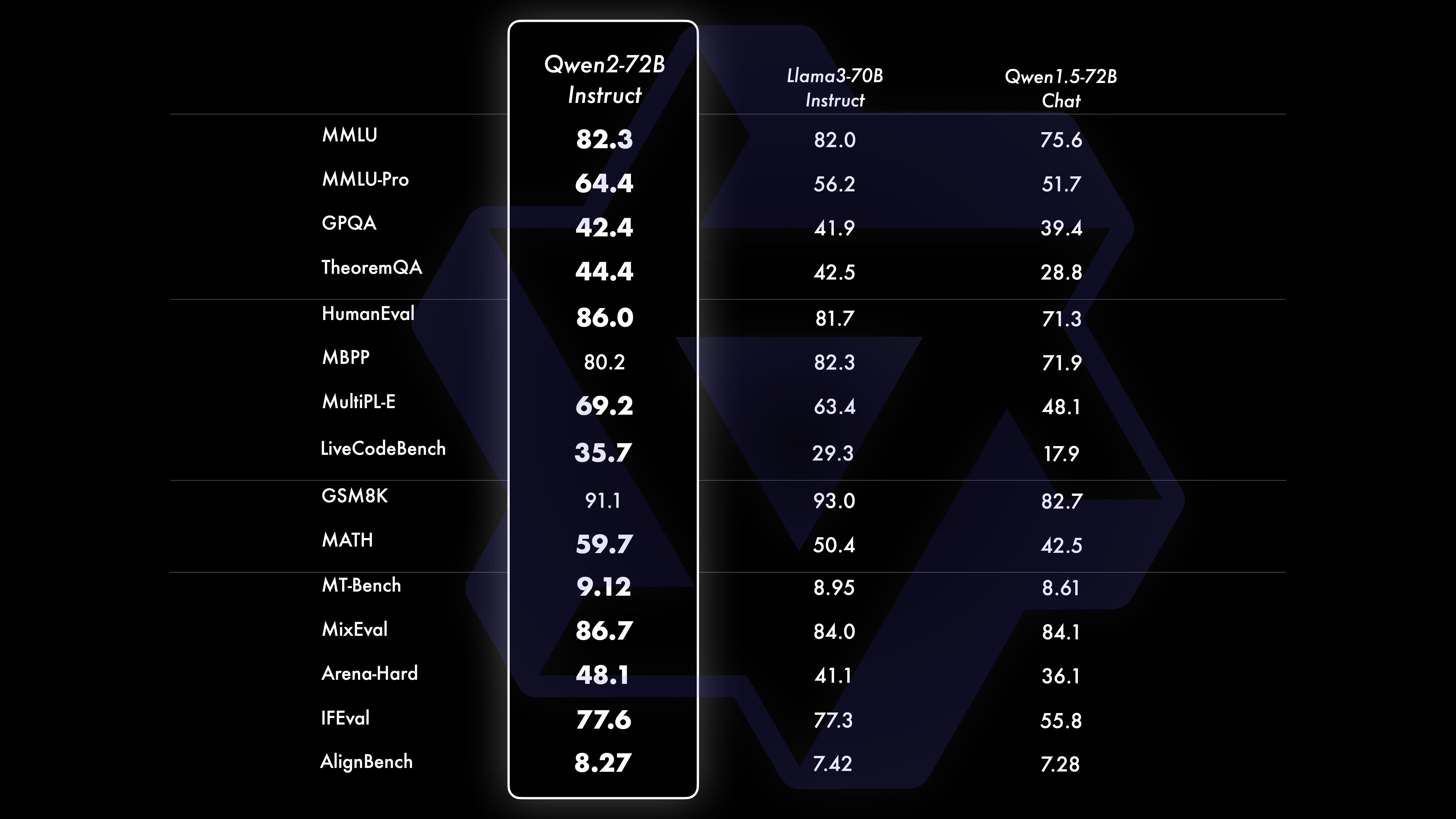
لقد أجرينا تقييمًا شاملاً لـ Qwen2-72B-Instruct، يغطي 16 معيارًا في مختلف المجالات. يحقق Qwen2-72B-Instruct التوازن بين اكتساب قدرات أفضل والتوافق مع القيم الإنسانية. على وجه التحديد، يتفوق Qwen2-72B-Instruct بشكل كبير على Qwen1.5-72B-Chat في جميع المعايير ويحقق أيضًا أداءً تنافسيًا مقارنةً بـ Llama-3-70B-Instruct.
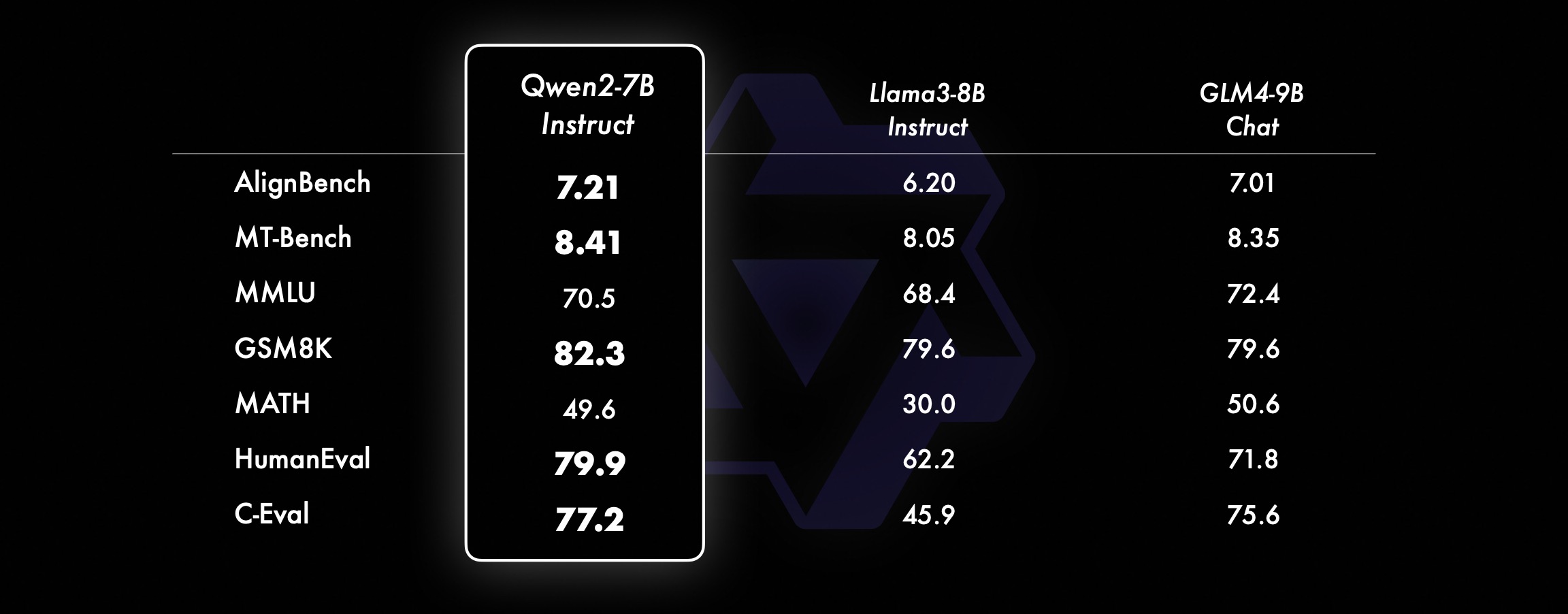
في الموديلات الأصغر حجمًا، تتفوق موديلات Qwen2 الخاصة بنا أيضًا على موديلات SOTA المماثلة وحتى الأكبر حجمًا. بالمقارنة مع نموذج SOTA الذي تم إصداره للتو، لا يزال Qwen2-7B-Instruct يُظهر مزايا في العديد من الاختبارات المعيارية، خاصة في التشفير والمؤشرات ذات الصلة باللغة الصينية.
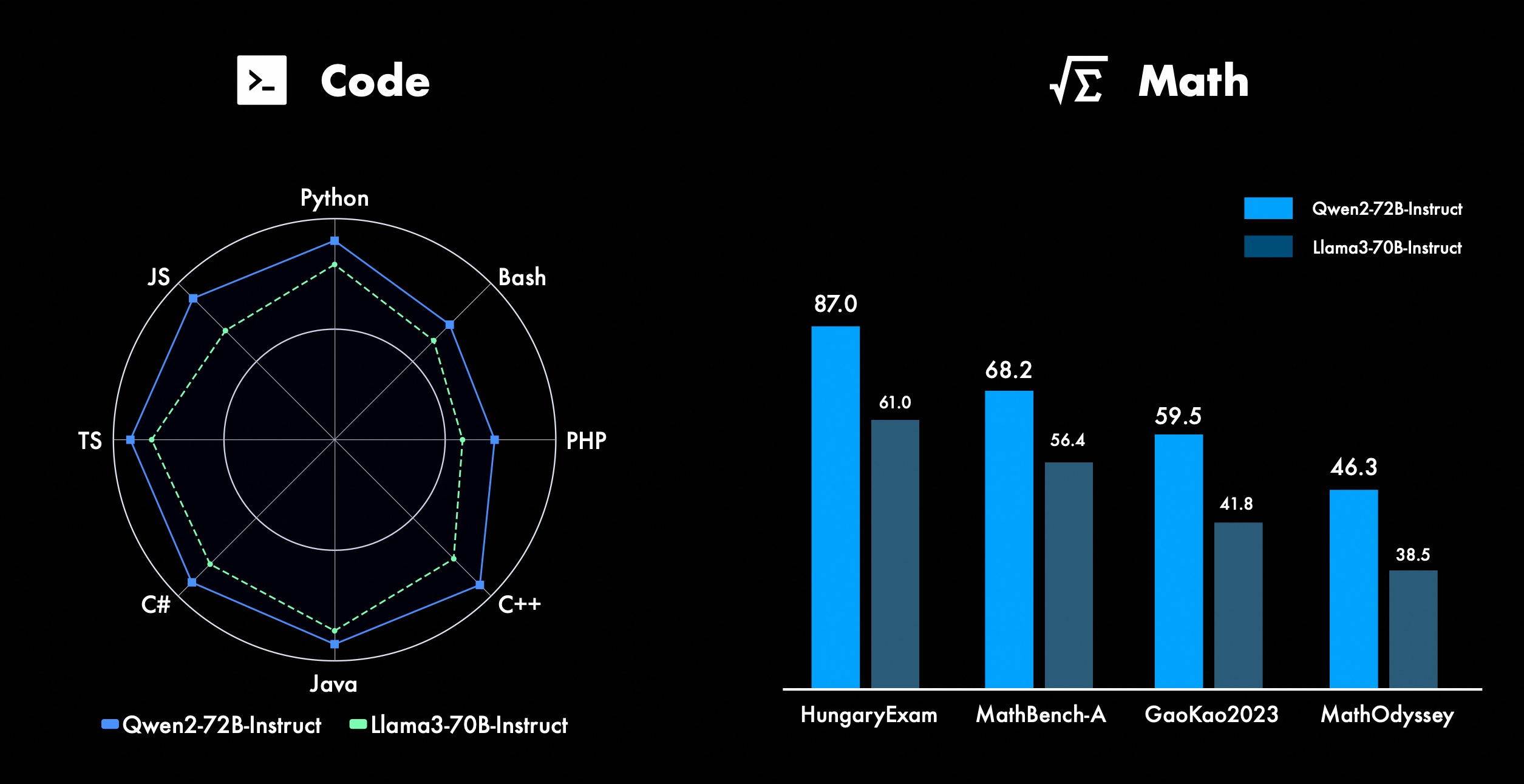
نحن نعمل باستمرار على تحسين ميزات Qwen المتقدمة، خاصة في البرمجة والرياضيات. فيما يتعلق بالبرمجة، نجحنا في دمج تجربة التدريب على التعليمات البرمجية وبيانات CodeQwen1.5، مما أدى إلى تحقيق Qwen2-72B-Instruct تحسينات كبيرة في لغات البرمجة المختلفة. في الرياضيات، يوضح Qwen2-72B-Instruct القدرات المحسنة في حل المشكلات الرياضية من خلال الاستفادة من مجموعة بيانات واسعة النطاق وعالية الجودة.
في Qwen2، يتم تدريب جميع نماذج ضبط التعليمات على سياقات بطول 32 كيلو بايت ويتم استقراءها إلى أطوال سياقية أطول باستخدام تقنيات مثل YARN أو Dual Chunk Attention.
توضح الصورة أدناه نتائج اختبارنا على Needle in a Haystack. تجدر الإشارة إلى أن Qwen2-72B-Instruct يمكنه التعامل بشكل مثالي مع مهمة استخراج المعلومات في سياق 128 كيلو بايت، إلى جانب أدائه القوي المتأصل، ويمكن استخدامه عندما تكون الموارد كافية في هذه الحالة، يصبح الخيار الأول لمعالجة المهام النصية الطويلة.
علاوة على ذلك، تجدر الإشارة إلى القدرات الرائعة للنماذج الأخرى في السلسلة: يتعامل Qwen2-7B-Instruct مع سياقات تصل إلى 128 كيلو بايت تقريبًا بشكل مثالي، ويدير Qwen2-57B-A14B-Instruct سياقات تصل إلى 64 كيلو بايت، والسلسلة الاثنين تدعم النماذج الأصغر سياقات 32 كيلو بايت.
بالإضافة إلى نموذج السياق الطويل، فإننا نوفر حل وكيل مفتوح المصدر للمعالجة الفعالة للمستندات التي تحتوي على ما يصل إلى مليون علامة. لمزيد من التفاصيل، راجع منشور مدونتنا المخصص حول هذا الموضوع.
يوضح الجدول أدناه نسبة الاستجابات الضارة الناتجة عن نموذج كبير لأربع فئات من الاستعلامات غير الآمنة متعددة اللغات (النشاط غير القانوني، والاحتيال، والمواد الإباحية، والعنف الخاص). تأتي بيانات الاختبار من Jailbreak ويتم ترجمتها إلى لغات متعددة للتقييم. لقد وجدنا أن Llama-3 لا يتعامل مع الإشارات متعددة اللغات بكفاءة، وبالتالي لم ندرجه في المقارنة. من خلال اختبار الأهمية (P_value)، وجدنا أن الأداء الأمني لنموذج Qwen2-72B-Instruct يعادل أداء GPT-4، وأفضل بكثير من نموذج Mistral-8x22B.
اللغة النشاط غير القانوني الاحتيال المواد الإباحية الخصوصية العنف GPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide Chinese0%13%0 %0%17%0%43%47%53%0%10%0%الإنجليزية0%7%0%0%23% 0%37%67%63%0%27%3%الحسابات المدينة0%13%0% 0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%فرنسا0%3%0% 3%3%7%3%19%7%0%27%0%ك0%4%0%3 %8%4%17%29%10%0%26%4%نقطة0%7%0%3% 7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0%4% 11%0%22%26%22%0%0%0%average0%8%0% 3%11%2%27%39%31%3%16%2% استخدم Qwen2 للتطويرحاليًا، تم إصدار جميع النماذج في Hugging Face وModelScope. نرحب بك لزيارة بطاقة النموذج لعرض طرق الاستخدام التفصيلية ومعرفة المزيد حول الخصائص والأداء والمعلومات الأخرى لكل نموذج.
لفترة طويلة، دعم العديد من الأصدقاء تطوير Qwen، بما في ذلك الضبط الدقيق (Axolotl، Llama-Factory، Firefly، Swift، XTuner)، القياس الكمي (AutoGPTQ، AutoAWQ، Neural Compressor)، النشر (vLLM، SGL، SkyPilot، TensorRT-LLM، OpenVino، TGI)، منصة API (معًا، Fireworks، OpenRouter)، التشغيل المحلي (MLX، Llama.cpp، Ollama، LM Studio)، Agent and RAG Framework (LlamaIndex، CrewAI، OpenDevin)، التقييم (LMSys، OpenCompass وOpen LLM Leaderboard والتدريب على النماذج (Dolphin وOpenbuddy) وما إلى ذلك. حول كيفية استخدام Qwen2 مع أطر عمل الطرف الثالث، يرجى الرجوع إلى الوثائق الخاصة بها بالإضافة إلى وثائقنا الرسمية.

هناك العديد من الفرق والأفراد الذين ساهموا في كوين ولم نذكرهم. نحن نقدر بشدة دعمهم ونأمل أن يؤدي تعاوننا إلى تعزيز البحث والتطوير في مجتمع الذكاء الاصطناعي مفتوح المصدر.
رخصةهذه المرة، قمنا بتغيير إذن النموذج إلى إذن مختلف. لا يزال Qwen2-72B ونموذج ضبط التعليمات الخاص به يستخدمان ترخيص Qianwen الأصلي، في حين أن جميع الطرز الأخرى، بما في ذلك Qwen2-0.5B وQwen2-1.5B وQwen2-7B وQwen2-57B-A14B، قد تحولت إلى Apache2.0! أن المزيد من الانفتاح لنموذجنا على المجتمع يمكن أن يؤدي إلى تسريع تطبيق وتسويق Qwen2 حول العالم.
ما هي الخطوة التالية بالنسبة لـ Qwen2؟نحن نقوم بتدريب نموذج Qwen2 أكبر لاستكشاف امتدادات النموذج بالإضافة إلى امتدادات البيانات الحديثة لدينا. علاوة على ذلك، قمنا بتوسيع نموذج لغة Qwen2 ليكون متعدد الوسائط، وقادرًا على فهم المعلومات المرئية والصوتية. في المستقبل القريب، سنواصل فتح نماذج جديدة مفتوحة المصدر لتسريع الذكاء الاصطناعي مفتوح المصدر. ابقوا متابعين!
يقتبسسنصدر تقريرًا فنيًا عن Qwen2 قريبًا. اقتباسات موضع ترحيب!
@article{qwen2، الملحق تقييم نموذج اللغة الأساسييركز تقييم النماذج الأساسية بشكل أساسي على أداء النموذج مثل فهم اللغة الطبيعية والإجابة على الأسئلة العامة والترميز والرياضيات والمعرفة العلمية والاستدلال وقدرات اللغات المتعددة.
تشمل مجموعات البيانات التي تم تقييمها ما يلي:
المهام الإنجليزية: MMLU (5 مرات)، MMLU-Pro (5 مرات)، GPQA (5 مرات)، Theorem QA (5 مرات)، BBH (3 مرات)، HellaSwag (10 مرات)، Winogrande (5 مرات)، TruthfulQA ( 0 مرة)، ARC-C (25 مرة)
مهام البرمجة: EvalPlus (0-shot) (HumanEval، MBPP، HumanEval+، MBPP+)، MultiPL-E (0-shot) (Python، C++، JAVA، PHP، TypeScript، C#، Bash، JavaScript)
مهام الرياضيات: GSM8K (4 مرات)، MATH (4 مرات)
المهام الصينية: C-Eval (5 طلقات)، CMMLU (5 طلقات)
مهام متعددة اللغات: اختبارات متعددة (M3Exam 5 مرات، IndoMMLU 3 مرات، ruMMLU 5 مرات، mmMLU 5 مرات)، فهم متعدد (BELEBELE 5 مرات، XCOPA 5 مرات، XWinograd 5 مرات، XStoryCloze 0 مرات، PAWS-X 5 مرات) ، رياضيات متعددة (MGSM 8 مرات)، ترجمات متعددة (فلوريس-1015 مرة)
مجموعة بيانات الأداء Qwen2-72B DeepSeek-V2Mixtral-8x22BCamel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72Bالهندسة المعماريةوزارة التعليمDenseDenseDenseDense#المعلمات المفعلة 21B39B70B72B110B72B#المعلمات 236B140B70B72B1 10B72B الإنجليزية موهرمان ·Lu 78.577.879.577.580.484.2MMLU-الإصدار الاحترافي-49.552. 845.849.455.6 ضمان الجودة-34.336.336.335.937.9 نظرية سؤال وجواب-35.932.329.334.943.1بيبيهي 78.978.981.065.574.88 2.4 شيراسواج 87.888.788.086 87.6 نوافذ كبيرة 84.885.085.383.083.585.1ARC-C70.070.768.865.969. 668.9 أسئلة وأجوبة صادقة 42.251.045.659.649.654.8 تقييم القوى العاملة بالترميز 45.746.348.246.354.364.6 إدارة الخدمة العامة الماليزية 73 .971.770.466.970.976.9 التقييم 55.054.154.852.95 7.765.4 مختلف 44.446.746.341.852.759.6 الرياضيات GSM8K79. 283.783.079.585.489.5 الرياضيات 43.641.742.534.149.651.1 تقييم C الصيني 81.754.665.284.189.191.0 جامعة مونتريال، كندا 84.053 .467.283.588.390.1 لغات متعددة وامتحانات متعددة 67.563.570.066.475.676.6فهم متعدد 77.077.779.978.278.280.7 رياضيات متعددة 58.862.967.161.764.476.0 ترجمات متعددة 36.023.338.035.636.2 37.8Qwen2-57B-A14B مجموعة البيانات Jabba Mixtral-8x7B Instrument-1.5-34BQwen1. 5-32BQwen2-57B-A14B الهندسة المعمارية MoE MoE كثيفة كثيفة MoE #المعلمات المفعلة 12B12B34B32B14B #Parameters 52B47B34B32B57B الإنجليزية Moleman Lu 67.471.877.174.376.5MMLU - الإصدار الاحترافي - 41.048.344.043.0 ضمان الجودة - 29.2 - 30.834.3 نظرية أسئلة وأجوبة - 2 3.2 - 28.833.5 بايبي أسود 45.450.376.466.867.0 شيلا Swag 87.186.585.985.085.2 Winogrand 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 أسئلة وأجوبة صادقة 46.451.153.957.457.7 تقييم القوى العاملة للترميز 29.337.246.34 3.353.0 الخدمة العامة ماليزيا - 63.965.564.271.9 التقييم - 46.451 .950.457.2 متنوع - 39.03 9.538.549 .8 الرياضيات GSM8K59.962.582.776.880.7 الرياضيات-30.841.736.143.0 تقييم C الصيني---83.587.7 جامعة مونتريال، كندا--84.882.388.5 لغات متعددة والامتحانات المتعددة-56.158.361.665.5 فهم متعدد الأطراف -70.773.976.577.0رياضيات متعددة -45.049.356.162.3ترجمة متعددة -29.830.033.534.5Qwen2-7B Dataset Mistral -7B Jemma -7B Camel -3-8BQwen1.5 -7BQwen2-7B# المعلمات 7.2B850 مليون 8.0B7.7B7.6B# المعلمات غير emb 7.0B780 مليون 7.0B650 مليون 650 مليون الإنجليزية Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 ضمان الجودة 24.725 .725.826. 731.8 نظرية سؤال وجواب 19.221.522.114.231.1 بايبي بلاك 56.155.157.740.262.6 شيراسواجر 83.282.282.178.580.7 وينوجراند 78.479.077.471.377.0ARC-C60.061.159 . 354.260.6 أسئلة وأجوبة صادقة 42.244 .844.051.154.2 تقييم القوى العاملة بالترميز 29.337.233.536 .051.2 الخدمة العامة ماليزيا 51.150.653.951.665.9 التقييم 36.439.640.340.054.2 متعدد 29.429.722.628.146.3 الرياضيات GSM8K52.246.456.0 62.579.9 الرياضيات 13.124.320.5 20.344.2 تقييم C البشري في الصين 47.443.649.574.183.2 جامعة مونتريال ، كندا - 50.873.183.9 الاختبار المتعدد متعدد اللغات 47.142.752.347.759.2 الفهم المتعدد 63.358.368.667.672.0 الرياضيات متعددة المتغيرات 26.339.136.337.357.5 الترجمة المتعددة 23.331.231 .928.431.5Qwen2 -0.5B ومجموعة بيانات Qwen2-1.5B Phi-2Gemma -2B الحد الأدنى لـ CPM Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B# المعلمات غير المضمنة 250 مليون 2.0B2.4B1.3B035 مليون 1.3 B Mohrman Lu 52.742.353.546.845.456.5MMLU-Professional-15.9--14.721.8 نظرية سؤال وجواب----8.915.0 تقييم القوى العاملة 47.622.050.020.122.031.1 إدارة الخدمة العامة الماليزية 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 الرياضيات 3.511.810.210.110 .721.7 بايبي بلاك 43.435.236.924.228.437. 2 شيلا سواج 73.171.468.361.449.366.6 Winogrand 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 أسئلة وأجوبة صادقة 44.533.1-39.439.745.9C - التقييم 23.428.0 51.159.758.270.6 جامعة مونتريال، كندا 24.2 - 51.157.855.170.3 تقييم نموذج ضبط التعليمات Qwen2-72B - مجموعة البيانات الموجهة Camel - 3-70B - إرشادات Qwen1.5-72B - الدردشة Qwen2-72B - الإرشادات الإنجليزية Mohr Man Lu 82.075.682.3MMLU - الإصدار الاحترافي 56.251. 764.4 ضمان الجودة 41.939.442.4 نظرية الأسئلة والأجوبة 42.528.844.4MT - المقعد 8.958.619.12 الساحة - الصعب 41.136.148.1 IFEval (الوصول الدقيق الفوري) 77.355.877.6 تقييم القوى العاملة الترميز 81.771.386.0 الخدمة العامة ماليزيا 82.371.980.2 التقييم المتعدد 63.448.169.2 75.266.979.0 اختبار الكود المباشر 29.317.935.7 الرياضيات GSM 8K93.082.7 91.1 الرياضيات 50.442.559.7 تقييم C الصيني 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-Instruction DatasetMix tral-8x7B-Instruct-v0.1Yi-1.5 -34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B - الهندسة المعمارية الإرشادية وزارة التربية والتعليم كثيفة الكثافة # المعلمة المفعلة 12B34B32B14B # المعلمة 47B34B32B57B الإنجليزية Mohr Man Lu 71.476.874.875.4MMLU - الإصدار الاحترافي 43.352.346.452 .8 الجودة الضمان - 30.834.3 أسئلة وأجوبة نظرية - -30.933.1MT-Bench8.308.508.308.55 تقييم القوى العاملة الترميز 45.175.268.379.9 الخدمة العامة ماليزيا 59.574.667.970.9 مختلف -50.766.4 تقييم 48.5-63.671. 6 لايف اختبار الكود 12.3-15.225.5 الرياضيات GSM8K65.790.283.679.6 الرياضيات 30.750.142.449.1 تقييم C الصيني--76.780.5AlignBench5.707.207.197.36Qwen2-7B-Guide Dataset Camel-3-8B-Guide Yi-1.5 -9ب -Chat GLM-4- 9B-Chat Qwen1.5-7B-Chat Qwen2-7B-Guide English Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 ضمان الجودة 34.2--27.825.3 نظرية سؤال وجواب 23.0- -14.125 .3MT-Bench8.058.208.357.608.41 الترميز الإنساني 62.266.571.846.379.9 الخدمة العامة ماليزيا 67.9--48.967.2 متعدد 48.5--27.259.1 التقييم 60.9--44.870.3 اختبار الكود المباشر 17.3--6 .026. 6 الرياضيات GSM8K79.684.879.660.382.3 الرياضيات 30.047.750.623.249.6 تقييم C الصيني 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 Qwen2-0.5B-Instruct وQwen2-1.5B-Instruct مجموعة البيانات Q ون1.5- 0.5B-Chat Qwen2-0.5B-Guide Qwen1.5-1.8B-Chat Qwen2-1.5B-Guide Morman Lu35.037.943.752.4 تقييم القوى العاملة 9.117.125.037.8GSM8K11.340.135.361.6C-التقييم 37.245.255.3 63.8التقييم ( المطالبة بالوصول الصارم) يضبط الأمر 14.620.016.829.0 إمكانيات اللغات المتعددة للنموذجقمنا بمقارنة نموذج ضبط تعليمات Qwen2 مع حاملي شهادات LLM الحديثة الأخرى على العديد من المعايير المفتوحة عبر اللغات بالإضافة إلى التقييم البشري. بالنسبة لخط الأساس، نقدم النتائج على مجموعتي بيانات التقييم:
Okapi's M-MMLU: تقييم المعرفة العامة متعدد اللغات (نستخدم مجموعات فرعية من ar وde وes وfr وit وnl وru وuk وvi وzh للتقييم) MGSM: لتقييمات اللغة الألمانية والإنجليزية والإسبانية والفرنسية والرياضيات باللغة اللغات اليابانية والروسية والتايلاندية والصينية والبرازيليةيتم حساب متوسط النتائج عبر اللغات لكل معيار وهي كما يلي:
نموذج M-MMLU (5 طلقات) MGSM (0 طلقات، CoT) الملكية LLM GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3 -sonnet-2024022971.085.6 مفتوح المصدر LL.M Command-r-plus-110b65.563.5Qwen1.5-7B-chat 50.037.0Qwen1.5-32B-chat 65.065.0Qwen1.5 -72B-Chat 68.471.7Qwen2-7B -الدليل 60.057.0Qwen2-57B-A14B-الدليل 68.074.0Qwen2-72B-الدليل 78.086.6للتقييم اليدوي، نقارن Qwen2-72B-Instruct مع GPT3.5 وGPT4 وClaude-3-Opus باستخدام مجموعة تقييم داخلية، والتي تتضمن 10 لغات ar وes وfr وko وth وvi و pt وid وja وru (نطاق الدرجات من 1 إلى 5):
نموذج حسابات القبض الإسبانية الفرنسية كوري ست نقاط معرف جيارو متوسط كلود-3-وركس-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3 93 .724.324.09 جي بي تي-4-تيربو- 04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-دليل 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 53.923 .943.873.833.953.553.773.063.633.71GPT- 3.5-Turbo-11062.524. 073.472.373.382.903.373.562.753.243.16تم تجميع النتائج حسب نوع المهمة، وهي كما يلي:
فهم المعرفة النموذجية في إنشاء الرياضيات Claude-3-Works-202402293.644.454.423.81GPT-4o-05133.764.354.453.53GPT-4-Turbo-04093.424.294.353.58Qwen2-72B-Guide3.414.074.363.61G بي تي- 4-06133.424. 32GPT-3.5-توربو-11063.373.673.892.97توضح هذه النتائج القدرات القوية متعددة اللغات لنموذج ضبط التعليمات Qwen2.
لقد حسنت نماذج سلسلة Qwen2 مفتوحة المصدر من Alibaba الأداء بشكل كبير وقدرات اللغات المتعددة، مما ساهم بشكل مهم في مجتمع الذكاء الاصطناعي مفتوح المصدر. في المستقبل، ستواصل Qwen2 تطوير وتوسيع نطاق النموذج وقدرات الوسائط المتعددة، وهو أمر يستحق التطلع إليه.