Sturm
v1.0.0 & EMNLP 2024 Paper Accepted!
| Forschungsvorschau | STURM-Papier | Co-STORM-Papier | Website |
Neueste Nachrichten
[2024/09] Die Co-STORM-Codebasis ist jetzt veröffentlicht und in knowledge-storm -Python-Paket v1.0.0 integriert. Führen Sie pip install knowledge-storm --upgrade um es auszuprobieren.
[2024/09] Wir führen kollaboratives STORM (Co-STORM) ein, um die kollaborative Wissenskuration zwischen Mensch und KI zu unterstützen! Co-STORM Paper wurde zur EMNLP 2024-Hauptkonferenz angenommen.
[2024/07] Sie können unser Paket jetzt mit pip install knowledge-storm installieren!
[2024/07] Wir fügen VectorRM hinzu, um die Basis auf vom Benutzer bereitgestellten Dokumenten zu unterstützen und die bestehende Unterstützung von Suchmaschinen ( YouRM , BingSearch ) zu ergänzen. (siehe Nr. 58)
[2024/07] Wir veröffentlichen Demo Light für Entwickler, eine minimale Benutzeroberfläche, die mit einem Streamlit-Framework in Python erstellt wurde und sich für lokale Entwicklung und Demo-Hosting eignet (Checkout Nr. 54).
[2024/06] Wir werden STORM auf der NAACL 2024 präsentieren! Besuchen Sie uns bei der Postersession 2 am 17. Juni oder schauen Sie sich unser Präsentationsmaterial an.
[2024/05] Wir fügen Bing-Suchunterstützung in rm.py hinzu. Testen Sie STORM mit GPT-4o – wir konfigurieren jetzt den Artikelgenerierungsteil in unserer Demo mit GPT-4o -Modell.
[2024/04] Wir veröffentlichen eine überarbeitete Version der STORM-Codebasis! Wir definieren die Schnittstelle für die STORM-Pipeline und implementieren das STORM-Wiki erneut (siehe src/storm_wiki ), um zu demonstrieren, wie die Pipeline instanziiert wird. Wir bieten eine API zur Unterstützung der Anpassung verschiedener Sprachmodelle und der Abruf-/Suchintegration.
Obwohl das System keine publikationsreifen Artikel produzieren kann, die häufig eine erhebliche Anzahl von Bearbeitungen erfordern, haben erfahrene Wikipedia-Redakteure es in ihrer Vorbereitungsphase als hilfreich empfunden.
Mehr als 70.000 Menschen haben unsere Live-Recherchevorschau ausprobiert. Probieren Sie es aus, um zu sehen, wie STORM Ihnen bei der Wissenserkundung helfen kann, und geben Sie uns bitte Feedback, um uns bei der Verbesserung des Systems zu helfen!
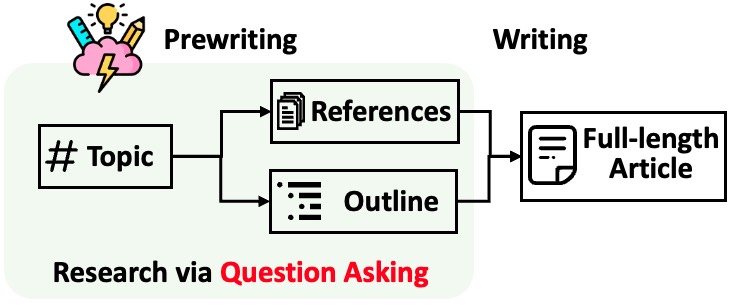
STORM unterteilt die Generierung langer Artikel mit Zitaten in zwei Schritte:
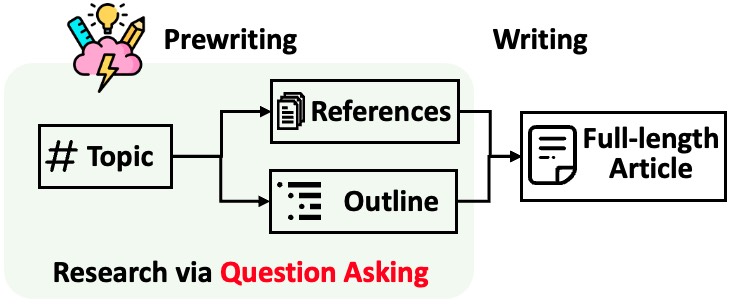
STORM identifiziert den Kern der Automatisierung des Rechercheprozesses darin, automatisch gute Fragen zu stellen. Es funktioniert nicht gut, das Sprachmodell direkt zum Stellen von Fragen aufzufordern. Um die Tiefe und Breite der Fragen zu verbessern, verfolgt STORM zwei Strategien:
Co-STORM schlägt ein kollaboratives Diskursprotokoll vor, das eine Turn-Management-Richtlinie implementiert, um eine reibungslose Zusammenarbeit zwischen zu unterstützen
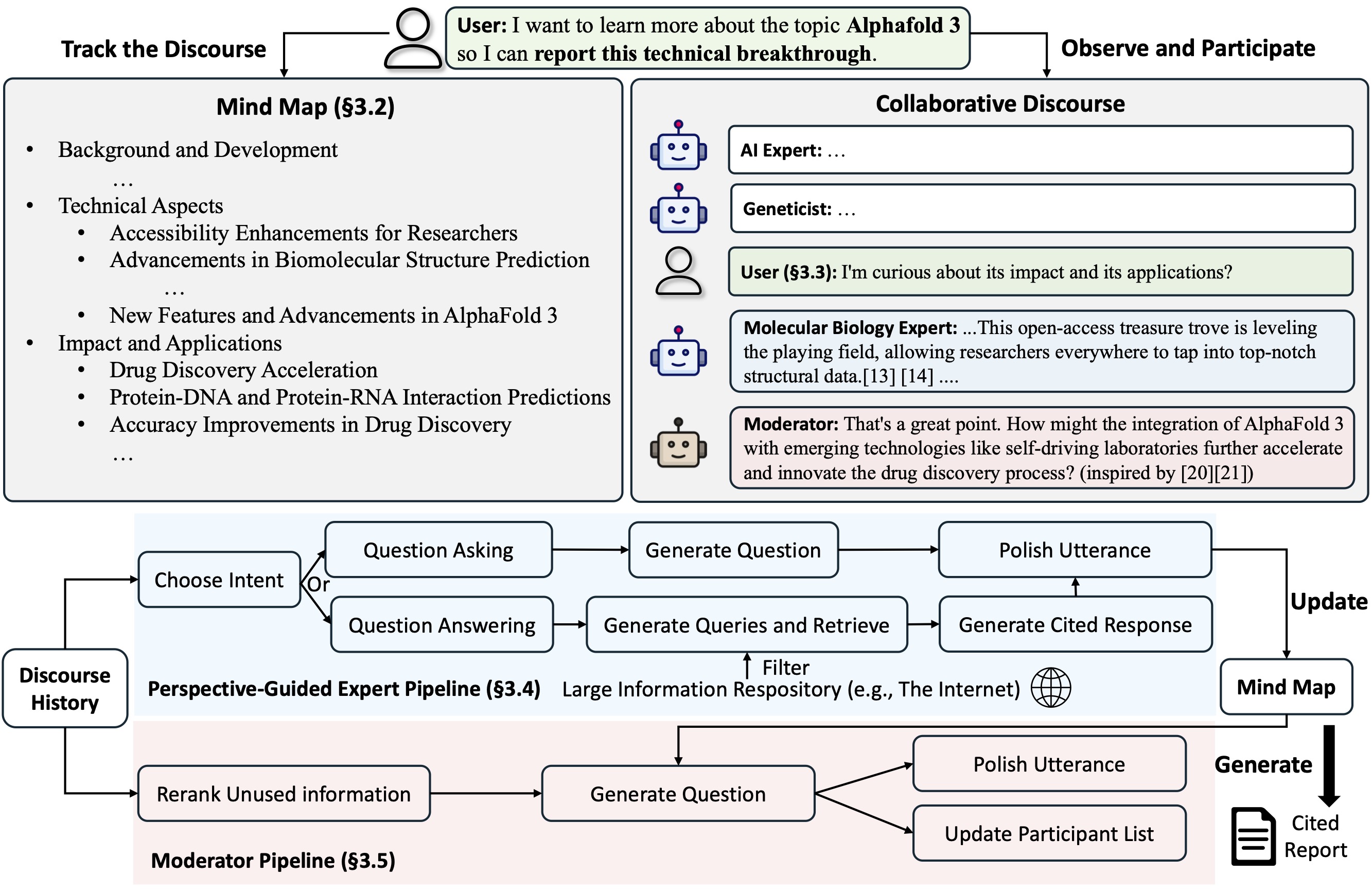
Co-STORM unterhält außerdem eine dynamisch aktualisierte Mindmap , die gesammelte Informationen in einer hierarchischen Konzeptstruktur organisiert und darauf abzielt, einen gemeinsamen konzeptionellen Raum zwischen dem menschlichen Benutzer und dem System zu schaffen . Die Mindmap hilft nachweislich dabei, die mentale Belastung zu reduzieren, wenn der Diskurs lang und tiefgründig ist.
Sowohl STORM als auch Co-STORM werden mit dspy hochmodular implementiert.
Um die Knowledge Storm-Bibliothek zu installieren, verwenden Sie pip install knowledge-storm .
Sie können auch den Quellcode installieren, der es Ihnen ermöglicht, das Verhalten der STORM-Engine direkt zu ändern.
Klonen Sie das Git-Repository.
git clone https://github.com/stanford-oval/storm.git
cd stormInstallieren Sie die erforderlichen Pakete.
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txtDerzeit unterstützt unser Paket:
OpenAIModel , AzureOpenAIModel , ClaudeModel , VLLMClient , TGIClient , TogetherClient , OllamaClient , GoogleModel , DeepSeekModel , GroqModel als SprachmodellkomponentenYouRM , BingSearch , VectorRM , SerperRM , BraveRM , SearXNG , DuckDuckGoSearchRM , TavilySearchRM , GoogleSearch und AzureAISearch als Abrufmodulkomponenten? PRs für die Integration weiterer Sprachmodelle in Knowledge_storm/lm.py und Suchmaschinen/Retriever in Knowledge_storm/rm.py werden sehr geschätzt!
Sowohl STORM als auch Co-STORM arbeiten in der Informationskurationsschicht. Sie müssen das Informationsabrufmodul und das Sprachmodellmodul einrichten, um jeweils ihre Runner -Klassen zu erstellen.
Die STORM-Wissenskurations-Engine ist als einfache Python- STORMWikiRunner Klasse definiert. Hier ist ein Beispiel für die Verwendung der You.com-Suchmaschine und OpenAI-Modelle.
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) Die STORMWikiRunner -Instanz kann mit der einfachen run aufgerufen werden:
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research : Wenn True, Gespräche mit unterschiedlichen Perspektiven simulieren, um Informationen über das Thema zu sammeln; Andernfalls laden Sie die Ergebnisse.do_generate_outline : Wenn True, wird eine Gliederung für das Thema generiert. Andernfalls laden Sie die Ergebnisse.do_generate_article : wenn True, einen Artikel für das Thema basierend auf der Gliederung und den gesammelten Informationen generieren; Andernfalls laden Sie die Ergebnisse.do_polish_article : Wenn True, verfeinern Sie den Artikel, indem Sie einen Zusammenfassungsabschnitt hinzufügen und (optional) doppelten Inhalt entfernen. Andernfalls laden Sie die Ergebnisse. Die Co-STORM-Wissenskurations-Engine ist als einfache Python- CoStormRunner -Klasse definiert. Hier ist ein Beispiel für die Verwendung der Bing-Suchmaschine und OpenAI-Modelle.
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) Die CoStormRunner -Instanz kann mit den Methoden warmstart() und step(...) aufgerufen werden.
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )Als Schnellstart für die Ausführung von STORM und Co-STORM mit unterschiedlichen Konfigurationen stellen wir in unserem Beispielordner Skripte zur Verfügung.
Wir empfehlen die Verwendung von secrets.toml zum Einrichten der API-Schlüssel. Erstellen Sie im Stammverzeichnis eine Datei secrets.toml und fügen Sie den folgenden Inhalt hinzu:
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key " So führen Sie STORM mit gpt Familienmodellen mit Standardkonfigurationen aus:
Führen Sie den folgenden Befehl aus.
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-articleUm STORM mit Ihren bevorzugten Sprachmodellen oder basierend auf Ihrem eigenen Korpus auszuführen: Schauen Sie sich examples/storm_examples/README.md an.
Um Co-STORM mit gpt Familienmodellen mit Standardkonfigurationen auszuführen,
BING_SEARCH_API_KEY="xxx" und ENCODER_API_TYPE="xxx" zu secrets.toml hinzupython examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bingWenn Sie den Quellcode installiert haben, können Sie STORM basierend auf Ihrem eigenen Anwendungsfall anpassen. Die STORM-Engine besteht aus 4 Modulen:
Die Schnittstelle für jedes Modul ist in knowledge_storm/interface.py definiert, während ihre Implementierungen in knowledge_storm/storm_wiki/modules/* instanziiert werden. Diese Module können entsprechend Ihren spezifischen Anforderungen angepasst werden (z. B. Erstellen von Abschnitten im Aufzählungspunktformat anstelle vollständiger Absätze).
Wenn Sie den Quellcode installiert haben, können Sie Co-STORM basierend auf Ihrem eigenen Anwendungsfall anpassen
knowledge_storm/interface.py definiert, während ihre Implementierung in knowledge_storm/collaborative_storm/modules/co_storm_agents.py instanziiert wird. Verschiedene LLM-Agentenrichtlinien können angepasst werden.DiscourseManager in knowledge_storm/collaborative_storm/engine.py bereit. Es kann individuell angepasst und weiter verbessert werden. Um das Studium der automatischen Wissenskuration und der Suche nach komplexen Informationen zu erleichtern, veröffentlicht unser Projekt die folgenden Datensätze:
Der FreshWiki-Datensatz ist eine Sammlung von 100 hochwertigen Wikipedia-Artikeln, die sich auf die am häufigsten bearbeiteten Seiten von Februar 2022 bis September 2023 konzentrieren. Weitere Einzelheiten finden Sie in Abschnitt 2.1 im STORM-Papier.
Sie können den Datensatz direkt von Huggingface herunterladen. Um das Problem der Datenkontamination zu verringern, archivieren wir den Quellcode für die Datenkonstruktionspipeline, der zu einem späteren Zeitpunkt wiederholt werden kann.
Um die Interessen der Benutzer an komplexen Informationssuchaufgaben in freier Wildbahn zu untersuchen, haben wir Daten aus der Web-Recherche-Vorschau verwendet, um den WildSeek-Datensatz zu erstellen. Wir haben die Daten heruntergerechnet, um die Vielfalt der Themen und die Qualität der Daten sicherzustellen. Jeder Datenpunkt ist ein Paar, das ein Thema und das Ziel des Benutzers für die Durchführung einer Tiefensuche zu diesem Thema umfasst. Weitere Einzelheiten finden Sie in Abschnitt 2.2 und Anhang A des Co-STORM-Papiers.
Der WildSeek-Datensatz ist hier verfügbar.
Für STORM-Paper-Experimente wechseln Sie bitte hier zum Zweig NAACL-2024-code-backup .
Für Co-STORM-Paper-Experimente wechseln Sie bitte zum Zweig EMNLP-2024-code-backup (Platzhalter vorerst, wird bald aktualisiert).
Unser Team arbeitet aktiv an:
Wenn Sie Fragen oder Anregungen haben, können Sie gerne ein Issue oder eine Pull-Anfrage eröffnen. Wir freuen uns über Beiträge zur Verbesserung des Systems und der Codebasis!
Ansprechpartner: Yijia Shao und Yucheng Jiang
Wir möchten Wikipedia für seinen hervorragenden Open-Source-Inhalt danken. Der FreshWiki-Datensatz stammt aus Wikipedia und ist unter der Creative Commons Attribution-ShareAlike (CC BY-SA)-Lizenz lizenziert.
Wir sind Michelle Lam für die Gestaltung des Logos für dieses Projekt und Dekun Ma für die Leitung der UI-Entwicklung sehr dankbar.
Bitte zitieren Sie unseren Artikel, wenn Sie diesen Code oder Teile davon in Ihrer Arbeit verwenden:
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}