datablations
1.0.0
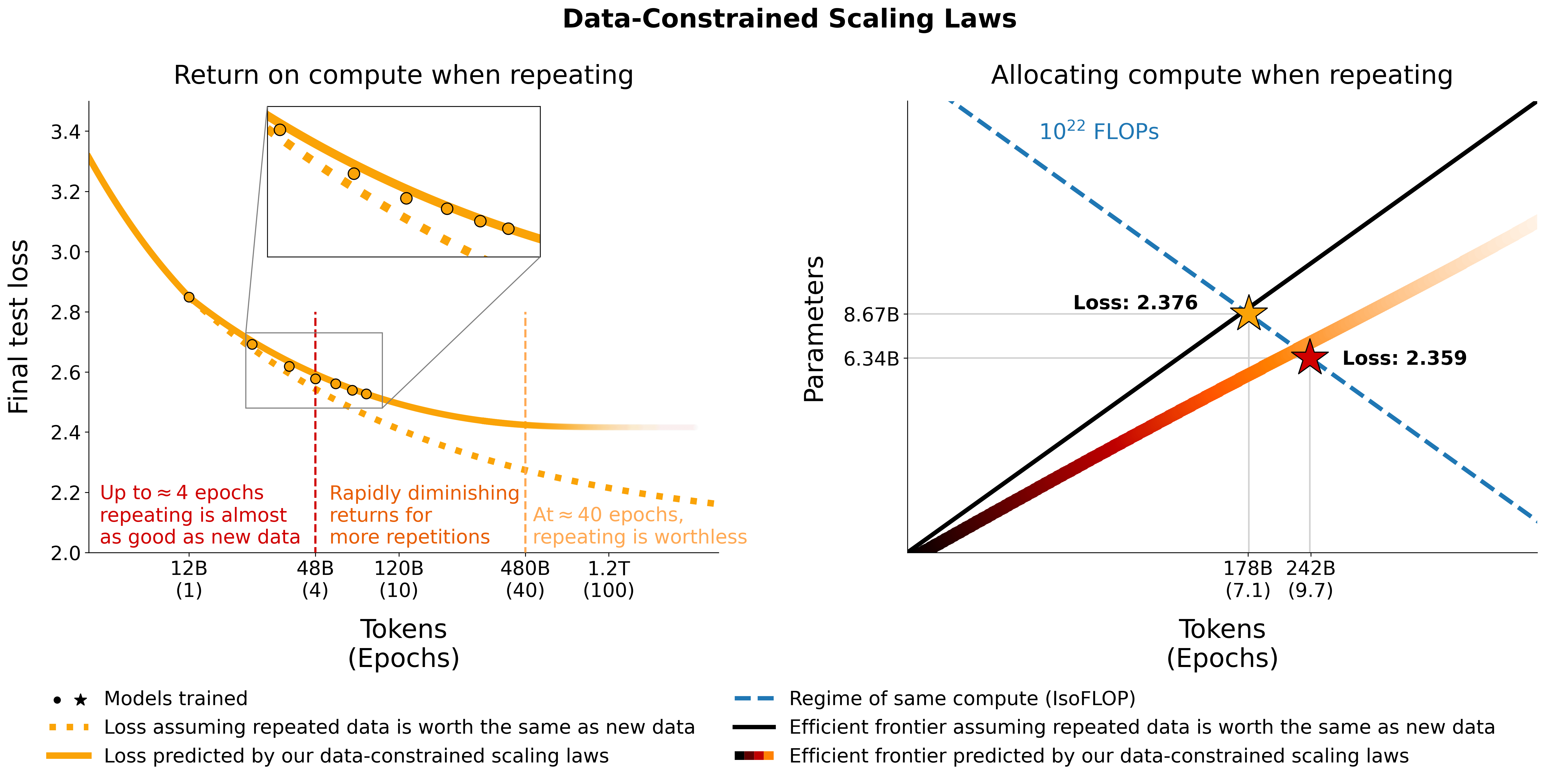
Dieses Repository bietet einen Überblick über alle Komponenten aus dem Artikel Scaling Data-Constrained Language Models. Vorträge zum Papier:
Wir untersuchen die Skalierung von Sprachmodellen in datenbeschränkten Regimen. Wir führen eine große Reihe von Experimenten durch, die das Ausmaß der Datenwiederholung und das Rechenbudget variieren und bis zu 900 Milliarden Trainingstokens und 9 Milliarden Parametermodelle umfassen. Basierend auf unseren Durchläufen schlagen wir ein Skalierungsgesetz für die Berechnungsoptimalität vor und validieren es empirisch, das den abnehmenden Wert wiederholter Token und überschüssiger Parameter berücksichtigt. Wir experimentieren auch mit Ansätzen zur Minderung der Datenknappheit, einschließlich der Erweiterung des Trainingsdatensatzes um Codedaten, Perplexity-Filterung und Deduplizierung. Modelle und Datensätze aus unseren 400 Trainingsläufen sind über dieses Repository verfügbar.
Wir experimentieren mit sich wiederholenden Daten zu C4 und der nicht deduplizierten englischen Aufteilung von OSCAR. Für jeden Datensatz laden wir die Daten herunter und wandeln sie in eine einzelne JSONL-Datei um, c4.jsonl bzw. oscar_en.jsonl .
Dann entscheiden wir über die Anzahl der eindeutigen Token und die entsprechende Anzahl an Proben, die wir aus dem Datensatz benötigen. Beachten Sie, dass C4 über 478.625834583 Token pro Probe verfügt und OSCAR über 1312.0951072 mit dem GPT2Tokenizer. Dies wurde berechnet, indem der gesamte Datensatz mit Tokens versehen und die Anzahl der Tokens durch die Anzahl der Stichproben dividiert wurde. Wir verwenden diese Zahlen, um die benötigten Proben zu berechnen.
Für 1,9 Milliarden einzigartige Token benötigen wir beispielsweise 1.9B / 478.625834583 = 3969697.96178 Proben für C4 und 1.9B / 1312.0951072 = 1448065.76107 Proben für OSCAR. Um die Daten zu tokenisieren, müssen wir zunächst das Megatron-DeepSpeed-Repository klonen und dessen Einrichtungsanleitung befolgen. Anschließend wählen wir diese Samples aus und tokenisieren sie wie folgt:
C4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64OSKAR:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64 Dabei verweist gpt2 auf einen Ordner, der alle Dateien von https://huggingface.co/gpt2/tree/main enthält. Durch die Verwendung von head stellen wir sicher, dass verschiedene Teilmengen überlappende Stichproben haben, um die Zufälligkeit zu reduzieren.
Für die Auswertung während des Trainings und die abschließende Auswertung nutzen wir das Validierungsset für C4:
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2 Für OSCAR, das keinen offiziellen Validierungssatz hat, nehmen wir einen Teil des Trainingssatzes, indem wir tail -364608 oscar_en.jsonl > oscarvalidation.jsonl ausführen und ihn dann wie folgt tokenisieren:
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2Wir haben mehrere vorverarbeitete Teilmengen zur Verwendung mit Megatron hochgeladen:
Einige Bin-Dateien waren zu groß für Git und wurden daher aufgeteilt, z. B. mit split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin. und split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. . Um sie für das Training zu verwenden, müssen Sie sie erneut zusammenfassen, indem Sie cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin und cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin .
Wir experimentieren mit dem Mischen von Code mit den Daten in natürlicher Sprache, indem wir den Python-Split von the-stack-dedup verwenden. Wir laden die Daten herunter, wandeln sie in eine einzelne JSONL-Datei um und verarbeiten sie mit dem gleichen Ansatz wie oben beschrieben vor.
Wir haben die vorverarbeitete Version zur Verwendung mit Megatron hier hochgeladen: https://huggingface.co/datasets/datablations/python-megatron. Wir haben die Bin-Datei mit split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. , also müssen Sie sie für das Training erneut zusammenfassen, indem Sie cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin verwenden.
Wir erstellen Versionen von C4 und OSCAR mit Perplexität und deduplizierungsbezogenen Filtermetadaten:
Anweisungen zum Neuerstellen dieser Metadaten-Datensätze finden Sie unter filtering/README.md .
Wir stellen die tokenisierten Versionen zur Verfügung, die für das Training mit Megatron verwendet werden können unter:
.bin Dateien wurden mit etwas wie split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. , also müssen Sie sie über cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin .
Um die tokenisierten Versionen anhand des Metadaten-Datensatzes neu zu erstellen,
filtering/deduplication/filter_oscar_jsonl.pyBefolgen Sie die nachstehenden Anweisungen, um die Perplexitätsperzentile zu erstellen.
C4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )OSKAR:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )Anschließend können Sie die resultierenden JSONL-Dateien für das Training mit Megatron tokenisieren, wie im Abschnitt „Wiederholen“ beschrieben.
C4: Für C4 müssen Sie lediglich alle Samples entfernen, bei denen das repetitions ausgefüllt ist, z. B. über
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR: Für OSCAR stellen wir unter filtering/filter_oscar_jsonl.py ein Skript zur Verfügung, um den deduplizierten Datensatz zu erstellen, wenn der Datensatz mit Filtermetadaten ausgestattet ist.
Anschließend können Sie die resultierenden JSONL-Dateien für das Training mit Megatron tokenisieren, wie im Abschnitt „Wiederholen“ beschrieben.
Alle Modelle können unter https://huggingface.co/datablations heruntergeladen werden.
Modelle werden im Allgemeinen wie folgt benannt: lm1-{parameters}-{tokens}-{unique_tokens} , insbesondere werden einzelne Modelle in den Ordnern wie folgt benannt: {parameters}{tokens}{unique_tokens}{optional specifier} , zum Beispiel wäre 1b12b8100m 1,1 Milliarden Parameter, 2,8 Milliarden Token, 100 Millionen einzigartige Token. Die xby -Konvention ( 1b1 , 2b8 usw.) führt zu Unklarheiten darüber, ob Zahlen zu Parametern oder Token gehören. Sie können jedoch jederzeit das Sbatch-Skript im entsprechenden Ordner überprüfen, um die genauen Parameter/Token/eindeutigen Token anzuzeigen. Wenn Sie Modelle konvertieren möchten, die noch nicht in huggingface/transformers konvertiert wurden, können Sie den Anweisungen im Training folgen.
Der einfachste Weg, ein einzelnes Modell herunterzuladen, ist z. B.:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553 Wenn dies zu lange dauert, können Sie mit wget auch einzelne Dateien direkt aus dem Ordner herunterladen, z. B.:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.ptFür Modelle, die den Experimenten in der Arbeit entsprechen, konsultieren Sie die folgenden Repositories:
lm1-misc/*dedup* für den Deduplizierungsvergleich für 100 Millionen eindeutige Token im AnhangAndere Modelle, die in der Arbeit nicht analysiert werden:
Wir trainieren Modelle mit unserem Fork von Megatron-DeepSpeed, der mit AMD-GPUs funktioniert (über ROCm): https://github.com/TurkuNLP/Megatron-DeepSpeed. Wenn Sie NVIDIA-GPUs verwenden möchten (über cuda), können Sie die verwenden Originalbibliothek: https://github.com/bigscience-workshop/Megatron-DeepSpeed
Sie müssen den Setup-Anweisungen beider Repositorys folgen, um Ihre Umgebung zu erstellen (unser spezielles Setup für LUMI ist in training/megdssetup.md detailliert beschrieben).
Jeder Modellordner enthält ein Sbatch-Skript, das zum Trainieren des Modells verwendet wurde. Sie können diese als Referenz verwenden, um Ihre eigenen Modelle zu trainieren und dabei die erforderlichen Umgebungsvariablen anzupassen. Die Sbatch-Skripte verweisen auf einige zusätzliche Dateien:
*txt Dateien, die die Datenpfade angeben. Sie finden sie unter utils/datapaths/* . Allerdings müssen Sie den Pfad wahrscheinlich anpassen, um auf Ihren Datensatz zu verweisen.model_params.sh , das sich unter utils/model_params.sh befindet und Architekturvoreinstellungen enthält.launch.sh , das Sie unter training/launch.sh finden. Es enthält für unser Setup spezifische Befehle, die Sie möglicherweise entfernen möchten. Nach dem Training können Sie Ihr Modell in Transformatoren konvertieren, z. B. mit python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1 .
Für Wiederholungsmodelle laden wir auch ihre Tensorboards nach dem Training hoch, indem wir z. B. tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar" , wodurch sie einfach für die Visualisierung im Papier verwendet werden können.
Für die muP-Ablation im Anhang verwenden wir das Skript unter training_scripts/mup.py . Es enthält Einrichtungsanweisungen.
Sie können unsere Formel verwenden, um den erwarteten Verlust anhand von Parametern, Daten und eindeutigen Token wie folgt zu berechnen:
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867Beachten Sie, dass der tatsächliche Verlustwert wahrscheinlich nicht aussagekräftig ist, sondern eher der Trend des Verlusts, wenn z. B. die Anzahl der Parameter zunimmt oder zwei Modelle wie im obigen Beispiel verglichen werden sollen. Um die optimale Zuordnung zu berechnen, können Sie eine einfache Rastersuche verwenden:
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test Wenn Sie anstelle der obigen Rastersuche einen geschlossenen Ausdruck für die optimale Zuordnung ableiten, teilen Sie uns dies bitte mit :) Wir passen datenbeschränkte Skalierungsgesetze und die C4-Skalierungskoeffizienten mithilfe des Codes unter utils/parametric_fit.ipynb an, der diesem Colab entspricht .
Training > Regular models um eine Trainingsumgebung einzurichten.pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git . Wir haben Version 0.2.0 verwendet, aber neuere Versionen sollten auch funktionieren.sbatch utils/eval_rank.sh aus und ändern Sie zunächst die erforderlichen Variablen im Skriptpython Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.json CSVaddtasks -Zweig des Evaluierungs-Harness: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13 dh alle Anforderungen außer promptsource, das von einem Fork mit den richtigen Eingabeaufforderungen installiert wirdsbatch utils/eval_generative.sh aus und ändern Sie zunächst die erforderlichen Variablen im Skriptpython utils/merge_generative.py zusammen und konvertieren sie dann mit python utils/csv_generative.py merged.json CSVbabi -Zweig des Evaluierungs-Harness: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (Beachten Sie, dass dieser Zweig nicht mit dem addtasks Zweig für generative Aufgaben, wie er stammt, kompatibel ist EleutherAI/lm-evaluation-harness , während addtasks auf bigscience/lm-evaluation-harness basiert )cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh aus und ändern Sie zunächst die erforderlichen Variablen im Skript plotstables/return_alloc.pdf , plotstables/return_alloc.ipynb , colabplotstables/dataset_setup.pdf , plotstables/dataset_setup.ipynb , colabplotstables/contours.pdf , plotstables/contours.ipynb , colabplotstables/isoflops_training.pdf , plotstables/isoflops_training.ipynb , colabplotstables/return.pdf , plotstables/return.ipynb , colabplotstables/strategies.pdf , plotstables/strategies.drawioplotstables/beyond.pdf , plotstables/beyond.ipynb , colabplotstables/cartoon.pdf , plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf und dasselbe Colab wie Abbildung 3plotstables/mup.pdf , plotstables/dd.pdf , plotstables/dedup.pdf , plotstables/mup_dd_dd.ipynb , colabplotstables/isoloss_alphabeta_100m.pdf und dasselbe Colab wie Abbildung 3plotstables/galactica.pdf , plotstables/galactica.ipynb , colabtraining_c4.pdf , validation_c4oscar.pdf , training_oscar.pdf , validation_epochs_c4oscar.pdf und dasselbe Colab wie Abbildung 4plotstables/perplexity_histogram.pdf , plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf , plotstables/training_validation_filter.pdf , plotstables/beyond_losses.ipynb & colabutils/parametric_fit.ipynb und entsprechen diesem Colab.plotstables/repetition.ipynb & colabplotstables/python.ipynb & colabplotstables/filtering.ipynb & colabAlle Modelle und Code sind unter Apache 2.0 lizenziert. Gefilterte Datensätze werden mit derselben Lizenz veröffentlicht wie die Datensätze, aus denen sie stammen.
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

