ComfyUI N Nodes
1.0.0
Eine Suite benutzerdefinierter Knoten für ComfyUI, die Integer-, String- und Float-Variablenknoten, GPT-Knoten und Videoknoten umfasst.
Wichtig
Diese Knoten wurden hauptsächlich in Windows in der von ComfyUI bereitgestellten Standardumgebung und in der vom Notebook für Paperspace speziell mit dem Docker-Image cyberes/gradient-base-py3.10:latest erstellten Umgebung getestet. Andere Umgebungen wurden nicht getestet.
Klonen Sie das Repository: git clone https://github.com/Nuked88/ComfyUI-N-Nodes.git
in Ihr ComfyUI-Verzeichnis custom_nodes .
WICHTIG: Wenn Sie die GPT-Knoten auf der GPU haben möchten, müssen Sie install_dependency bat files ausführen. Es gibt zwei Versionen: install_dependency_ggml_models.bat für die alten ggmlv3-Modelle und install_dependency_gguf_models.bat für alle neuen Modelle (GGUF). SIE KÖNNEN NUR EINES VON IHNEN AUF EINMAL VERWENDEN! Da llama-cpp-python aus dem Quellcode kompiliert werden muss, damit es die GPU nutzen kann, müssen zum Kompilieren zunächst CUDA und Visual Studio 2019 oder 2022 (im Fall meiner Fledermaus) installiert sein. Einzelheiten und den vollständigen Leitfaden finden Sie HIER.
Wenn Sie GPTLoaderSimple mit dem Moondream-Modell verwenden möchten, müssen Sie das Skript „install_extra.bat“ ausführen, das die Transformers-Version 4.36.2 installiert.
Starten Sie ComfyUI neu
Falls Sie diese Änderungen rückgängig machen müssen (aufgrund der Inkompatibilität mit anderen Knoten), können Sie das Skript „remove_extra.bat“ verwenden.
ComfyUI lädt beim Start automatisch alle benutzerdefinierten Skripte und Knoten.
Notiz
Die Installation von Lama-CPP-Python wird automatisch vom Skript durchgeführt. Wenn Sie über eine NVIDIA-GPU verfügen, ist dank jllllll Repo kein CUDA-Build mehr erforderlich. Ich habe auch die Unterstützung für GGMLv3-Modelle eingestellt, da alle namhaften Modelle mittlerweile auf die neueste Version von GGUF umgestiegen sein sollten.
Notiz
Seit dem 14.02.2024 wurde der Knoten einer massiven Neufassung unterzogen, die auch zur Änderung aller Knotennamen führte, um künftige Konflikte mit anderen Erweiterungen zu vermeiden (zumindest hoffe ich das). Folglich sind die alten Arbeitsabläufe nicht mehr kompatibel und erfordern einen manuellen Austausch jedes Knotens. Um dies zu vermeiden, habe ich ein Tool erstellt, das einen automatischen Austausch ermöglicht. Ziehen Sie unter Windows einfach einen beliebigen *.json-Workflow auf die Datei migrate.bat in (custom_nodes/ComfyUI-N-Nodes), und ein weiterer Workflow mit dem Suffix _migrated wird im selben Ordner wie der aktuelle Workflow erstellt. Unter Linux können Sie das Skript folgendermaßen verwenden: python libs/migrate.py path/to/original/workflow/. Aus Sicherheitsgründen wird der ursprüngliche Workflow nicht gelöscht.“ Um die letzte Version dieses Repositorys zu installieren, bevor sich diese von der Comfyui-N-Suite ändert, führen Sie git checkout 29b2e43baba81ee556b2930b0ca0a9c978c47083 aus
ComfyUI-N-Nodes in custom_nodescomfyui-n-nodes in ComfyUIwebextensionsn-styles.csv und n-styles.csv.backup in ComfyUIstylesGPTcheckpoints -Ordner in ComfyUImodelscustom_nodes/ComfyUI-N-Nodesgit pull
Der LoadVideoAdvanced-Knoten ermöglicht das Laden einer Videodatei und das Extrahieren von Frames daraus. Der Name wurde von LoadVideo in LoadVideoAdvanced geändert, um Konflikte mit dem LoadVideo animierteniff-Knoten zu vermeiden.
video : Wählen Sie die zu ladende Videodatei aus.framerate : Wählen Sie, ob die ursprüngliche Framerate beibehalten oder auf die halbe oder viertel Geschwindigkeit reduziert werden soll.resize_by : Wählen Sie aus, wie die Größe von Frames geändert werden soll – „none“, „height“ oder „width“.size : Zielgröße bei Größenänderung nach Höhe oder Breite.images_limit : Begrenzen Sie die Anzahl der zu extrahierenden Bilder.batch_size : Stapelgröße für die Kodierung von Frames.starting_frame : Wählen Sie aus, mit welchem Frame begonnen werden soll.autoplay : Wählen Sie aus, ob das Video automatisch abgespielt werden soll.use_ram : Verwenden Sie RAM statt Festplatte zum Dekomprimieren von Videobildern. IMAGES : Extrahierte Rahmenbilder als PyTorch-Tensoren.LATENT : Leere latente Vektoren.METADATA : Videometadaten – FPS und Anzahl der Bilder.WIDTH: Rahmenbreite.HEIGHT : Rahmenhöhe.META_FPS : Bildrate.META_N_FRAMES : Anzahl der Frames.Der Knoten extrahiert Frames aus dem Eingabevideo mit der angegebenen Framerate. Bei Auswahl ändert es die Größe von Frames und gibt sie als Stapel von PyTorch-Bildtensoren zusammen mit latenten Vektoren, Metadaten und Frame-Abmessungen zurück.
Der SaveVideo-Knoten nimmt extrahierte Frames auf und speichert sie als Videodatei zurück. 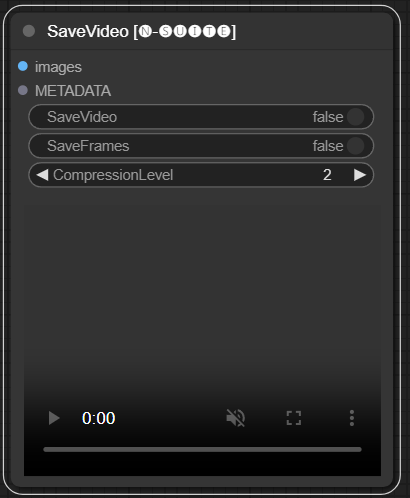
images : Bilder als Tensoren rahmen.METADATA : Metadaten vom LoadVideo-Knoten.SaveVideo : Schaltet das Speichern der Ausgabevideodatei um.SaveFrames : Speichern von Frames in einem Ordner umschalten.CompressionLevel : PNG-Komprimierungsstufe zum Speichern von Frames. Speichert die ausgegebene Videodatei und/oder extrahierte Frames.
Der Knoten nimmt extrahierte Frames und Metadaten und kann sie als neue Videodatei und/oder einzelne Frame-Bilder speichern. Videokomprimierung und Frame-PNG-Komprimierung können konfiguriert werden. HINWEIS: Wenn Sie LoadVideo als Quelle der Frames verwenden, bleibt der Ton der Originaldatei erhalten, jedoch nur, wenn images_limit und Starting_frame gleich Null sind.
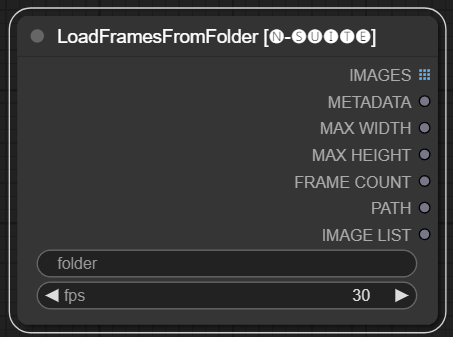
Der LoadFramesFromFolder-Knoten ermöglicht das Laden von Bildrahmen aus einem Ordner und deren Rückgabe als Stapel.
folder : Pfad zum Ordner, der die Rahmenbilder enthält. Muss im PNG-Format vorliegen und mit einer Nummer benannt sein (z. B. 1.png oder sogar 0001.png). Die Bilder werden nacheinander geladen.fps : Bilder pro Sekunde, die den geladenen Bildern zugewiesen werden sollen. IMAGES : Stapel geladener Rahmenbilder als PyTorch-Tensoren.METADATA : Metadaten, die den eingestellten FPS-Wert enthalten.MAX_WIDTH : Maximale Rahmenbreite.MAX_HEIGHT : Maximale Rahmenhöhe.FRAME COUNT : Anzahl der Frames im Ordner.PATH : Pfad zum Ordner, der die Rahmenbilder enthält.IMAGE LIST : Liste der Rahmenbilder im Ordner (keine echte Liste, sondern nur eine durch n geteilte Zeichenfolge).Der Knoten lädt alle Bilddateien aus dem angegebenen Ordner, konvertiert sie in PyTorch-Tensoren und gibt sie als Batch-Tensor zusammen mit einfachen Metadaten zurück, die den festgelegten FPS-Wert enthalten.
Dies ermöglicht das einfache Laden einer Reihe von Frames, die zuvor extrahiert und gespeichert wurden, um sie beispielsweise erneut zu laden und zu verarbeiten. Durch die Einstellung des FPS-Wertes können die Frames richtig als Videosequenz interpretiert werden.
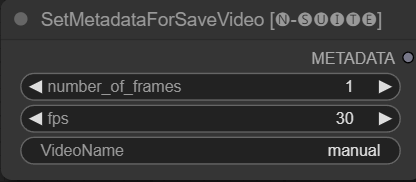
Der SetMetadataForSaveVideo-Knoten ermöglicht das Festlegen von Metadaten für den SaveVideo-Knoten.
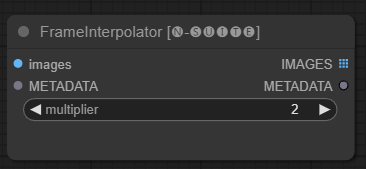
Der FrameInterpolator-Knoten ermöglicht die Interpolation zwischen extrahierten Videobildern, um die Bildrate zu erhöhen und Bewegungen zu glätten.
images : Extrahierte Rahmenbilder als Tensoren.METADATA : Metadaten aus dem Video – FPS und Anzahl der Bilder.multiplier : Faktor, um den die Bildrate erhöht werden soll. IMAGES : Interpolierte Frames als Bildtensoren.METADATA : Aktualisierte Metadaten mit neuer Bildrate.Der Knoten verwendet extrahierte Frames und Metadaten als Eingabe. Es verwendet ein Interpolationsmodell (RIFE), um zusätzliche Zwischenbilder mit einer höheren Bildrate zu erzeugen.
Die ursprüngliche Bildrate in den Metadaten wird mit dem multiplier multipliziert, um die neue interpolierte Bildrate zu erhalten.
Die interpolierten Frames werden als Stapel von Bildtensoren zurückgegeben, zusammen mit aktualisierten Metadaten, die die neue Framerate enthalten.
Dadurch können Sie die Bildrate eines vorhandenen Videos erhöhen, um flüssigere Bewegungen und eine langsamere Wiedergabe zu erzielen. Das Interpolationsmodell erstellt neue realistische Frames, um die Lücken zu füllen, anstatt nur vorhandene Frames zu duplizieren.
Der Originalcode wurde HIER entnommen
Da der primitive Knoten Einschränkungen hinsichtlich der Verknüpfungen aufweist (zu der Zeit, in der ich diesen Artikel schreibe, können Sie beispielsweise „start_at_step“ und „steps“ eines anderen ksamplers nicht miteinander verknüpfen), habe ich beschlossen, diese einfachen Knotenvariablen zu erstellen, um diese Einschränkung zu umgehen. Variablen sind:
Diese benutzerdefinierten Knoten sollen die Funktionen des ConfyUI-Frameworks erweitern, indem sie die Textgenerierung mithilfe von GGUF-GPT-Modellen ermöglichen. Diese README-Datei bietet einen Überblick über die beiden benutzerdefinierten Knoten und ihre Verwendung in ConfyUI.
Sie können in extra_model_paths.yaml den Pfad hinzufügen, in dem sich Ihre Modell-GGUF auf diese Weise befinden (Beispiel):
other_ui: base_path: I:\text-generation-webui GPTcheckpoints: models/
Andernfalls wird im Modellordner von ComfyUI ein GPTcheckpoints-Ordner erstellt, in dem Sie Ihre .gguf-Modelle ablegen können.
Außerdem wurden im Verzeichnis „Llava“ im Ordner „GPTcheckpoints“ für das LLava-Modell zwei Ordner erstellt:
clips : Dieser Ordner dient zum Speichern der Clips für Ihre LLava-Modelle (normalerweise Dateien, die im Repository mit mm beginnen). models : Dieser Ordner dient zum Speichern der LLava-Modelle.
Dieser Knoten unterstützt tatsächlich 4 verschiedene Modelle:
Die GGUF-Modelle können vom Huggingface Hub heruntergeladen werden
HIER ein Video mit einem Beispiel für die Verwendung der GGUF-Modelle von Boricuapab
Hier eine kleine Liste der von diesem Knoten unterstützten Modelle:
LlaVa 1.5 7B LlaVa 1.5 13B LlaVa 1.6 Mistral 7B BakLLaVa Nous Hermes 2 Vision
####Beispiel mit Llava-Modell: 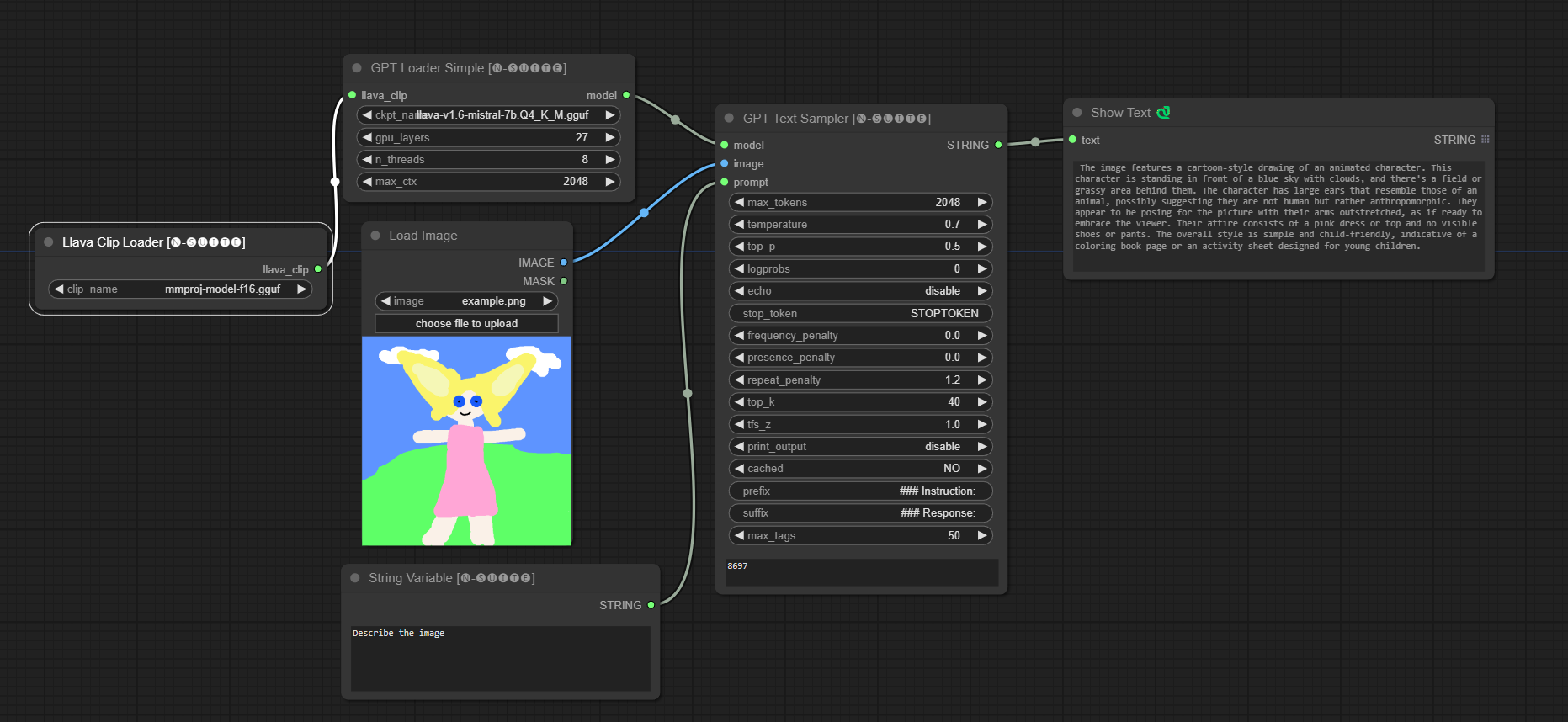
Das Modell wird automatisch heruntergeladen, wenn Sie es zum ersten Mal ausführen. Wie auch immer, es ist HIER verfügbar. Der Code stammt aus diesem Repository
####Beispiel mit Moondream-Modell: 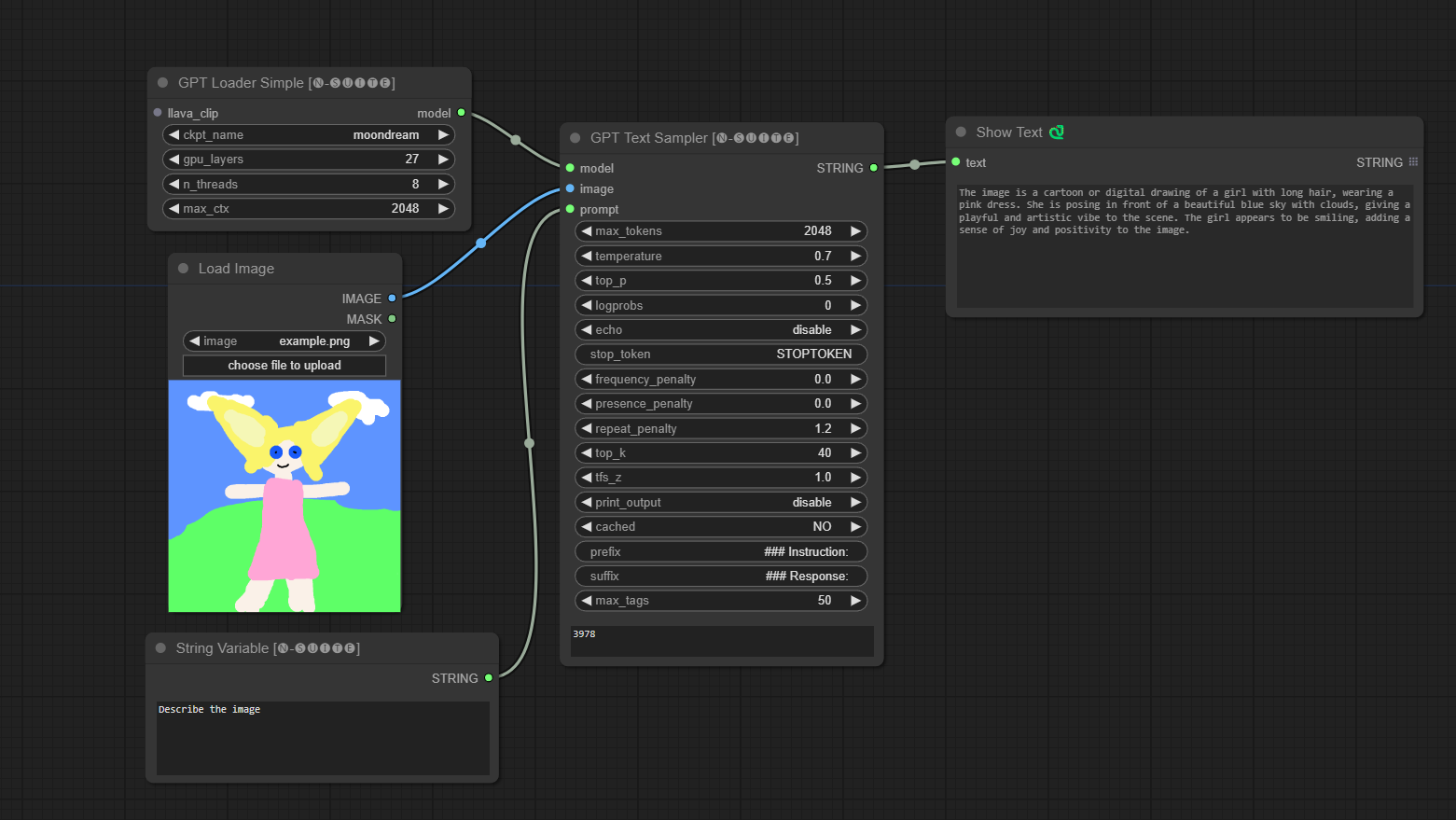
Das Modell wird automatisch heruntergeladen, wenn Sie es zum ersten Mal ausführen. Wie auch immer, es ist HIER verfügbar. Der Code stammt aus diesem Repository
####Beispiel mit Joytag-Modell: 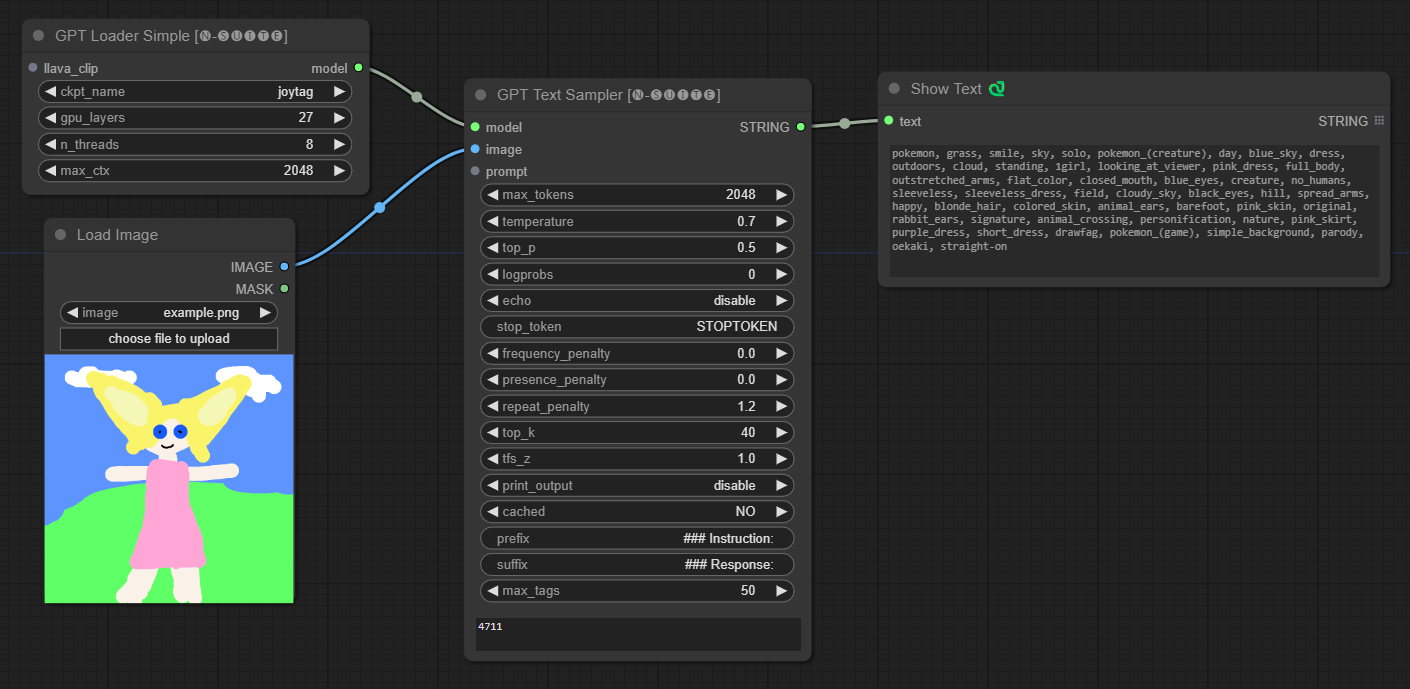
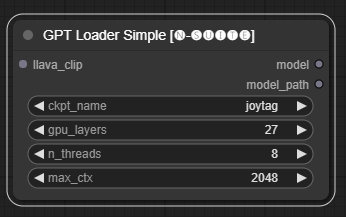
Der GPTLoaderSimple Knoten ist für das Laden von GPT-Modellprüfpunkten und das Erstellen einer Instanz der Llama-Bibliothek für die Textgenerierung verantwortlich. Es bietet eine Schnittstelle zum Konfigurieren von GPU-Ebenen, der Anzahl der Threads und des maximalen Kontexts für die Textgenerierung.
ckpt_name : Wählen Sie den GPT-Checkpoint-Namen aus den verfügbaren Optionen aus (Joytag und Moondream werden beim ersten Mal automatisch heruntergeladen).gpu_layers : Geben Sie die Anzahl der zu verwendenden GPU-Ebenen an (Standard: 27).n_threads : Geben Sie die Anzahl der Threads für die Textgenerierung an (Standard: 8).max_ctx : Geben Sie die maximale Kontextlänge für die Textgenerierung an (Standard: 2048). Der Knoten gibt eine Instanz der Llama-Bibliothek (MODEL) und den Pfad zum geladenen Prüfpunkt (STRING) zurück.
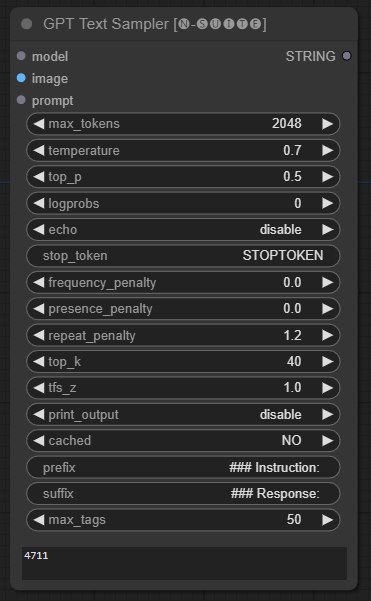
Der GPTSampler Knoten erleichtert die Textgenerierung mithilfe von GPT-Modellen basierend auf der Eingabeaufforderung und verschiedenen Generierungsparametern. Damit können Sie Aspekte wie Temperatur, Top-P-Probenahme, Strafen und mehr steuern.
prompt : Geben Sie die Eingabeaufforderung für die Textgenerierung ein.image : Bildeingabe für Joytag-, Moondream- und Llava-Modelle.model : Wählen Sie das GPT-Modell aus, das für die Textgenerierung verwendet werden soll.max_tokens : Legen Sie die maximale Anzahl von Token im generierten Text fest (Standard: 128).temperature : Stellen Sie den Temperaturparameter auf Zufälligkeit ein (Standard: 0,7).top_p : Legen Sie die Top-p-Wahrscheinlichkeit für die Kernprobenahme fest (Standard: 0,5).logprobs : Geben Sie die Anzahl der auszugebenden Protokollwahrscheinlichkeiten an (Standard: 0).echo : Aktivieren oder deaktivieren Sie das Drucken der Eingabeaufforderung neben dem generierten Text.stop_token : Geben Sie das Token an, bei dem die Textgenerierung stoppt.frequency_penalty , presence_penalty , repeat_penalty : Strafen für die Steuerwortgenerierung.top_k : Legen Sie die Top-k-Token fest, die bei der Generierung berücksichtigt werden sollen (Standard: 40).tfs_z : Legen Sie den Temperaturskalierungsfaktor für die häufigsten Proben fest (Standard: 1,0).print_output : Aktivieren oder deaktivieren Sie das Drucken des generierten Texts auf der Konsole.cached : Wählen Sie aus, ob die zwischengespeicherte Generierung verwendet werden soll (Standard: NEIN).prefix , suffix : Geben Sie Text an, der der Eingabeaufforderung vorangestellt und angehängt werden soll.max_tags : Dies wirkt sich nur auf die maximale Anzahl der von joydag generierten Tags aus. Der Knoten gibt den generierten Text zusammen mit einer UI-freundlichen Darstellung zurück.
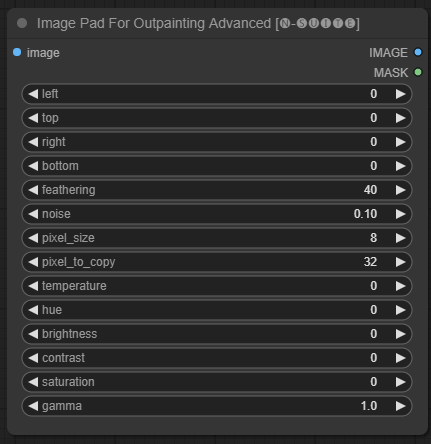
Der ImagePadForOutpaintingAdvanced -Knoten ist eine Alternative zum ImagePadForOutpainting Knoten, der die in diesem Video gezeigte Technik unter der Outpainting-Maske anwendet. Der Farbkorrekturteil wurde von diesem benutzerdefinierten Knoten von Sipherxyz übernommen
image : Bildeingabe.left : Pixel, das von links erweitert werden soll,top : Pixel, das von oben erweitert werden soll,right : Pixel, das von rechts erweitert werden soll,bottom : Pixel, das von unten erweitert werden soll.feathering : Federungsstärkenoise : Mischstärke aus Rauschen und kopiertem Randpixel_size : Wie groß wird das Pixel im Pixeleffekt sein?pixel_to_copy : wie viele Pixel kopiert werden sollen (von jeder Seite)temperature : Farbkorrektureinstellung, die nur auf den Maskenteil angewendet wird.hue : Farbkorrektureinstellung, die nur auf den Maskenteil angewendet wird.brightness : Farbkorrektureinstellung, die nur auf den Maskenteil angewendet wird.contrast : Farbkorrektureinstellung, die nur auf den Maskenteil angewendet wird.saturation : Farbkorrektureinstellung, die nur auf den Maskenteil angewendet wird.gamma : Farbkorrektureinstellung, die nur auf den Maskenteil angewendet wird. Der Knoten gibt das verarbeitete Bild und die Maske zurück.

Der DynamicPrompt Knoten generiert Eingabeaufforderungen, indem er eine feste Eingabeaufforderung mit einer zufälligen Auswahl von Tags aus einer variablen Eingabeaufforderung kombiniert. Dies ermöglicht eine flexible und dynamische Eingabeaufforderungsgenerierung für verschiedene Anwendungsfälle.
variable_prompt : Geben Sie den Variablen-Prompt für die Tag-Auswahl ein.cached : Wählen Sie aus, ob die generierte Eingabeaufforderung zwischengespeichert werden soll (Standard: NEIN).number_of_random_tag : Wählen Sie zwischen „Fest“ und „Zufällig“ für die Anzahl der einzuschließenden Zufalls-Tags.fixed_number_of_random_tag : Wenn number_of_random_tag wenn „Fixed“ Geben Sie die Anzahl der einzubeziehenden Zufalls-Tags an (Standard: 1).fixed_prompt (Optional): Geben Sie die feste Eingabeaufforderung zum Generieren der endgültigen Eingabeaufforderung ein. Der Knoten gibt die generierte Eingabeaufforderung zurück, die eine Kombination aus der festen Eingabeaufforderung und ausgewählten Zufalls-Tags ist.
variable_prompt mit durch Kommas getrennten Tags aus, fixed_prompt ist optional 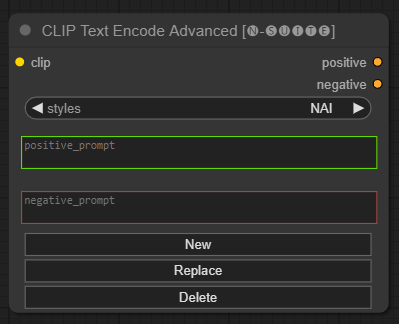
Der CLIP Text Encode Advanced Knoten ist eine Alternative zum standardmäßigen CLIP Text Encode Knoten. Es bietet Unterstützung für die Stile „Hinzufügen/Ersetzen/Löschen“ und ermöglicht die Einbeziehung sowohl positiver als auch negativer Eingabeaufforderungen in einen einzigen Knoten.
Die Basisstildatei heißt n-styles.csv und befindet sich im Ordner ComfyUIstyles . Die Stildatei hat dasselbe Format wie die aktuelle Datei styles.csv die in A1111 (zum Zeitpunkt des Schreibens) verwendet wurde.
HINWEIS: Dieser Hinweis ist experimentell und weist noch viele Fehler auf
clip : Clip-Eingangstyle : Die positiven und negativen Eingabeaufforderungen werden automatisch basierend auf dem ausgewählten Stil ausgefüllt positive : positive Bedingungennegative : negative Bedingungen Fühlen Sie sich frei, zu diesem Projekt beizutragen, indem Sie Probleme melden oder Verbesserungen vorschlagen. Öffnen Sie ein Problem oder senden Sie eine Pull-Anfrage im GitHub-Repository.
Dieses Projekt ist unter der MIT-Lizenz lizenziert. Einzelheiten finden Sie in der LICENSE-Datei.


