evidently
v0.4.40
Ein Open-Source-Framework zum Bewerten, Testen und Überwachen von ML- und LLM-basierten Systemen.

Dokumentation | Discord-Community | Blog | Twitter | Offensichtlich Cloud
Offensichtlich 0,4,25 . LLM-Evaluation -> Tutorial
Offensichtlich handelt es sich um eine Open-Source-Python-Bibliothek für die Evaluierung und Beobachtbarkeit von ML und LLM. Es hilft bei der Bewertung, Prüfung und Überwachung KI-gestützter Systeme und Datenpipelines vom Experiment bis zur Produktion.
Offensichtlich ist es sehr modular. Sie können mit einmaligen Auswertungen mithilfe von Reports oder Test Suites in Python beginnen oder einen Dashboard Dienst zur Echtzeitüberwachung erhalten.
Berichte berechnen verschiedene Daten-, ML- und LLM-Qualitätsmetriken. Sie können mit Voreinstellungen beginnen oder diese anpassen.
| Berichte |
|---|
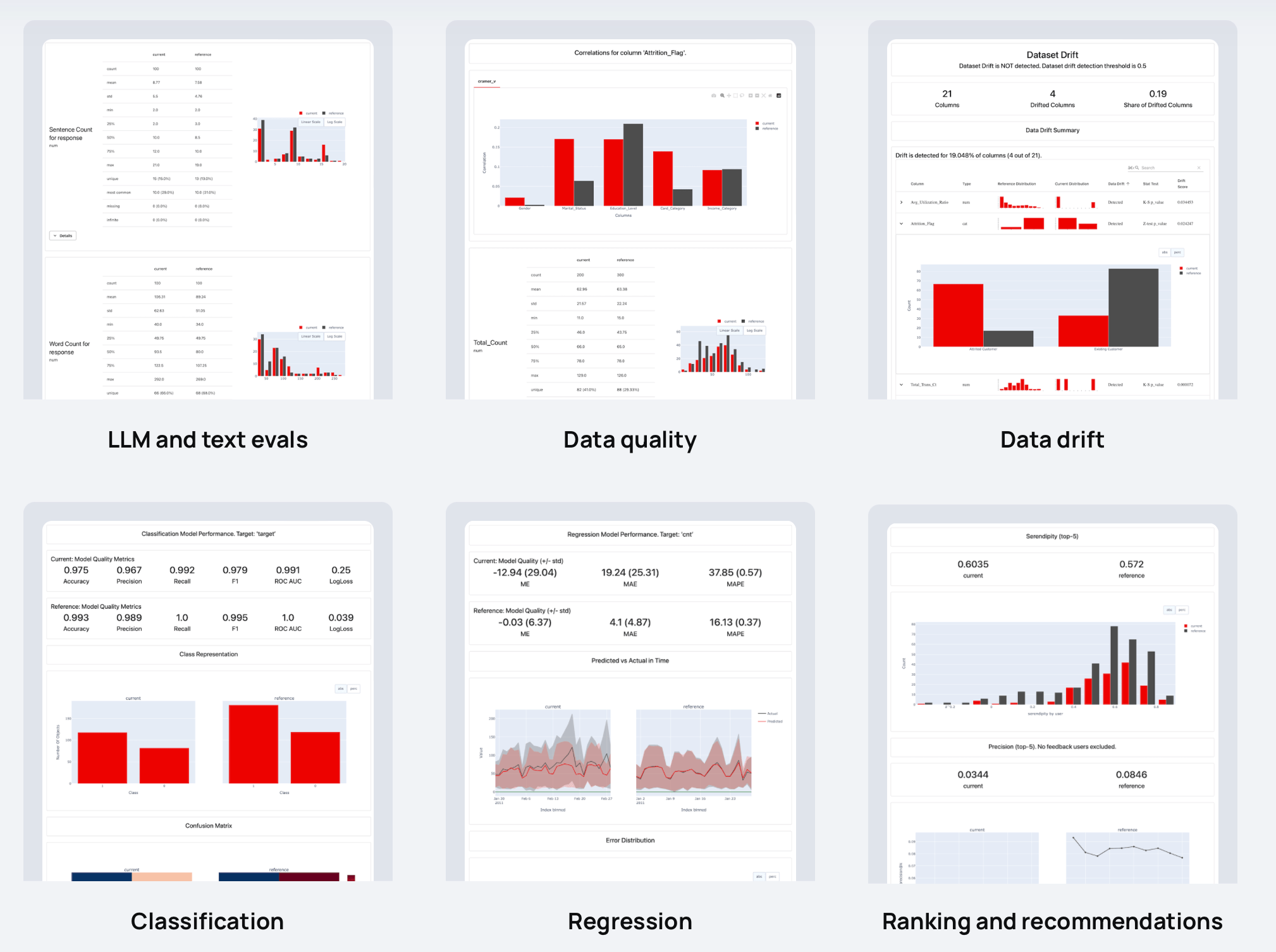 |
Testsuiten prüfen, ob definierte Bedingungen für Metrikwerte vorliegen, und geben ein „Bestanden“- oder „Nicht bestanden“-Ergebnis zurück.
gt (größer als), lt (kleiner als) usw.| Testsuite |
|---|
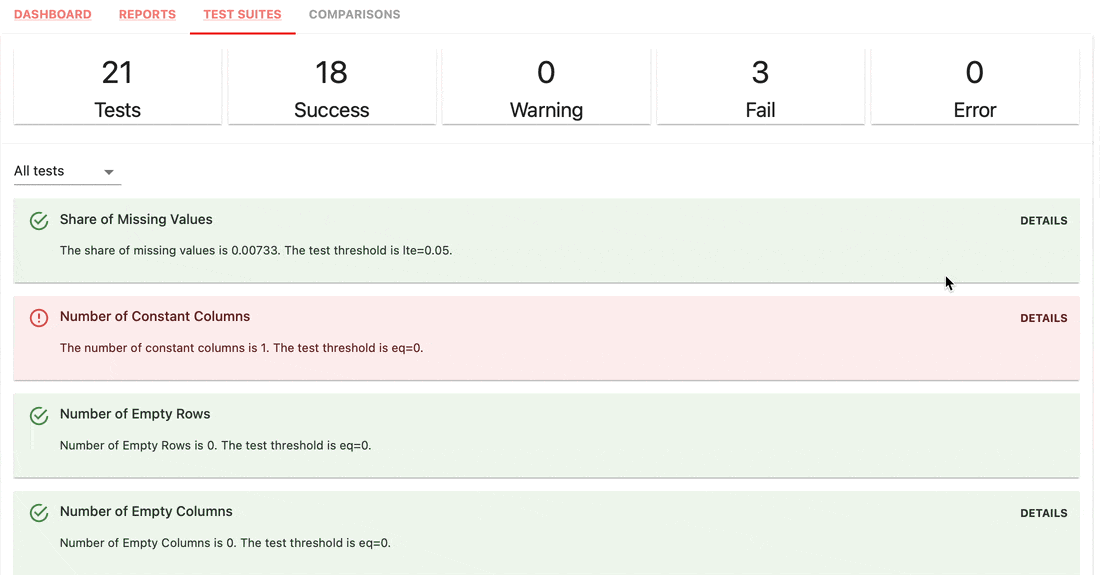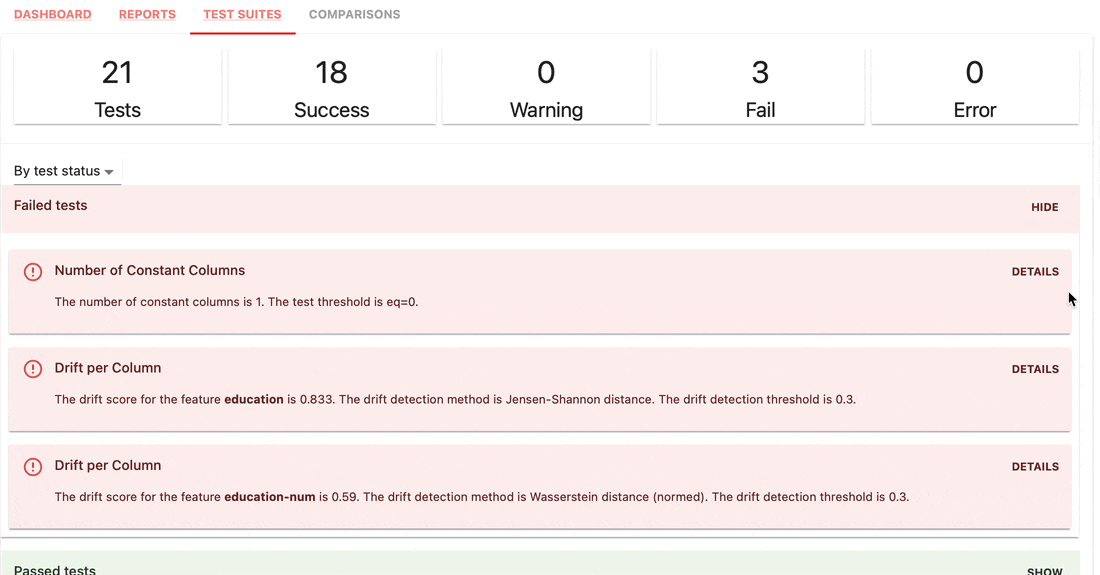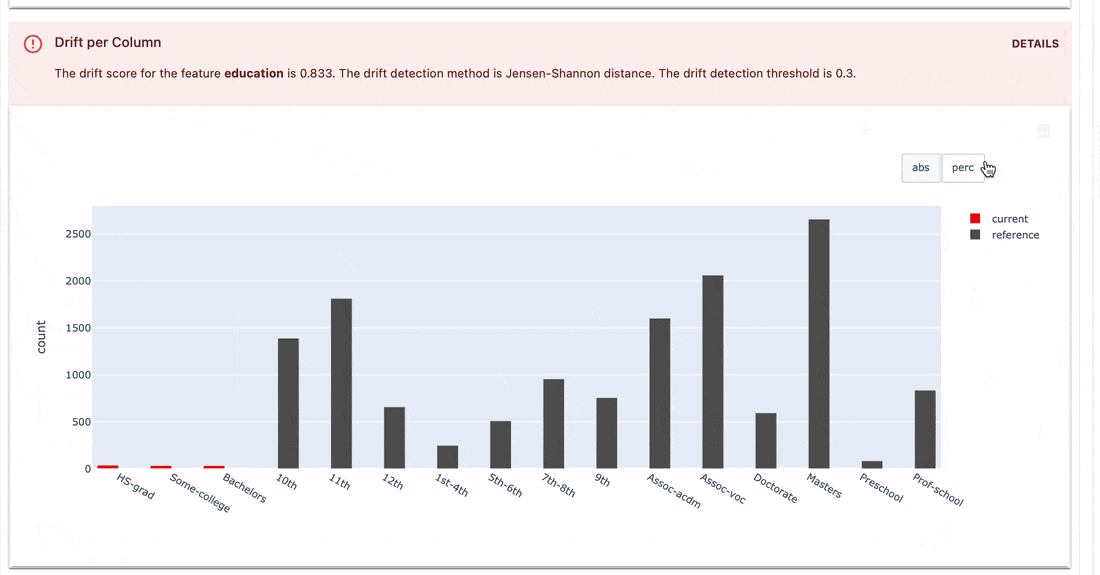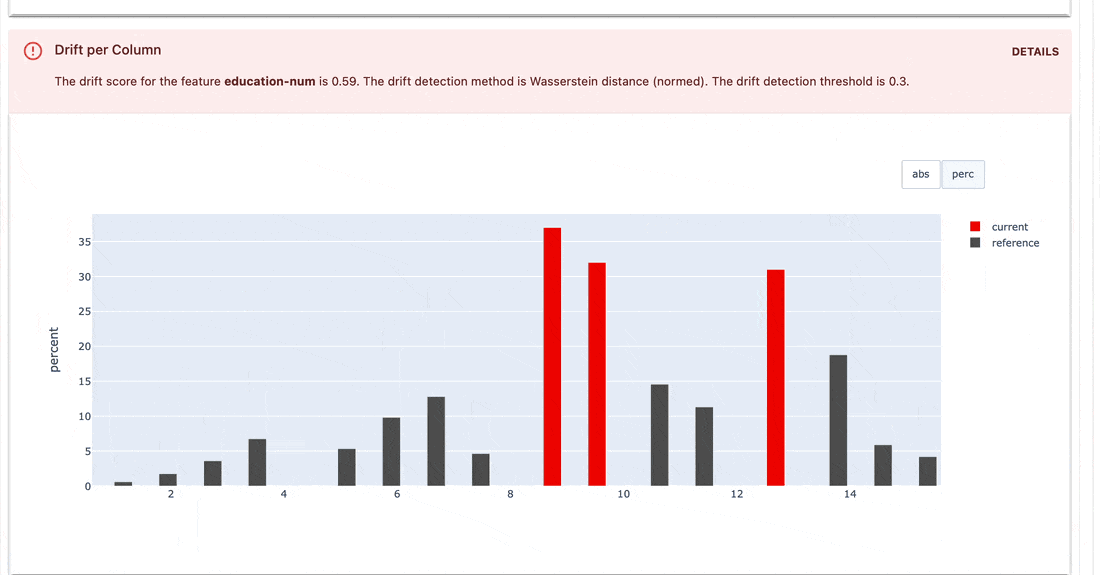 |
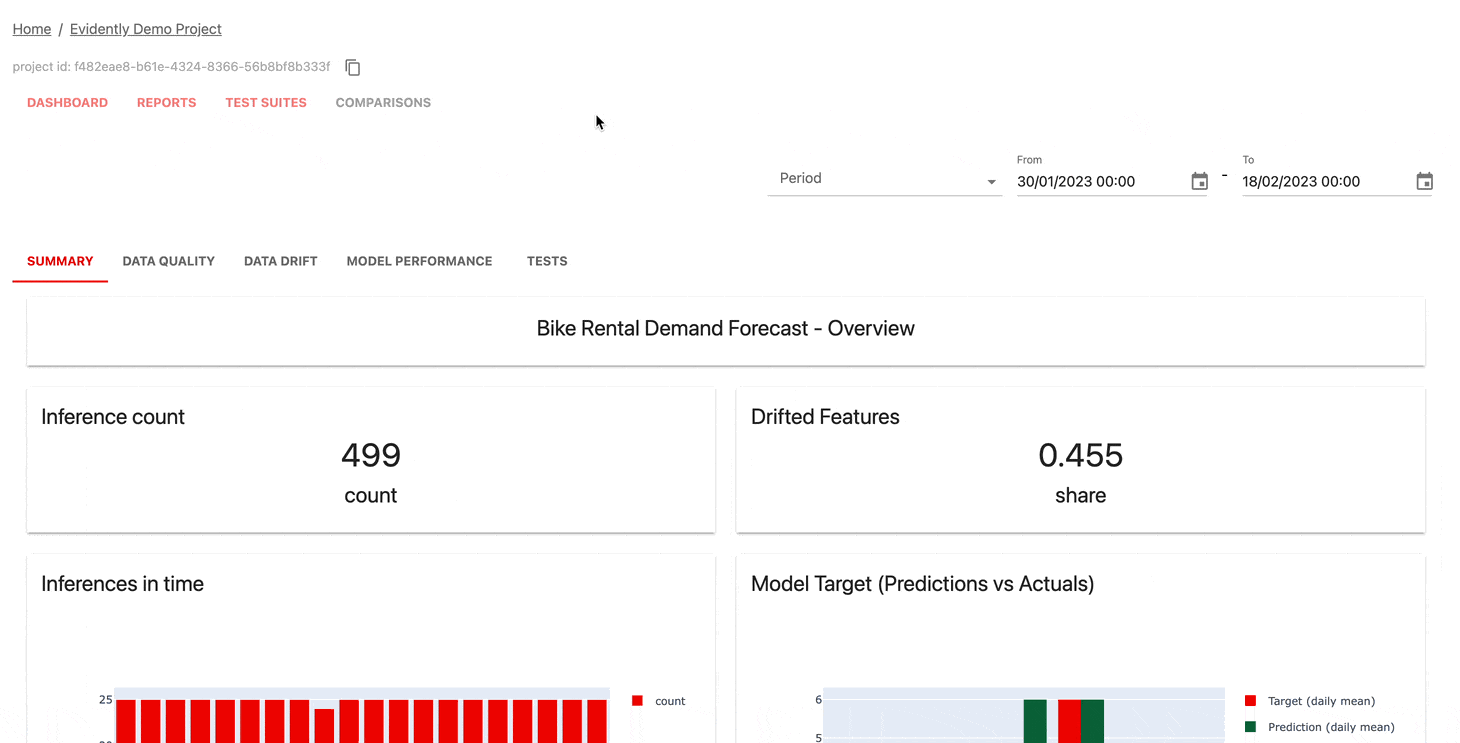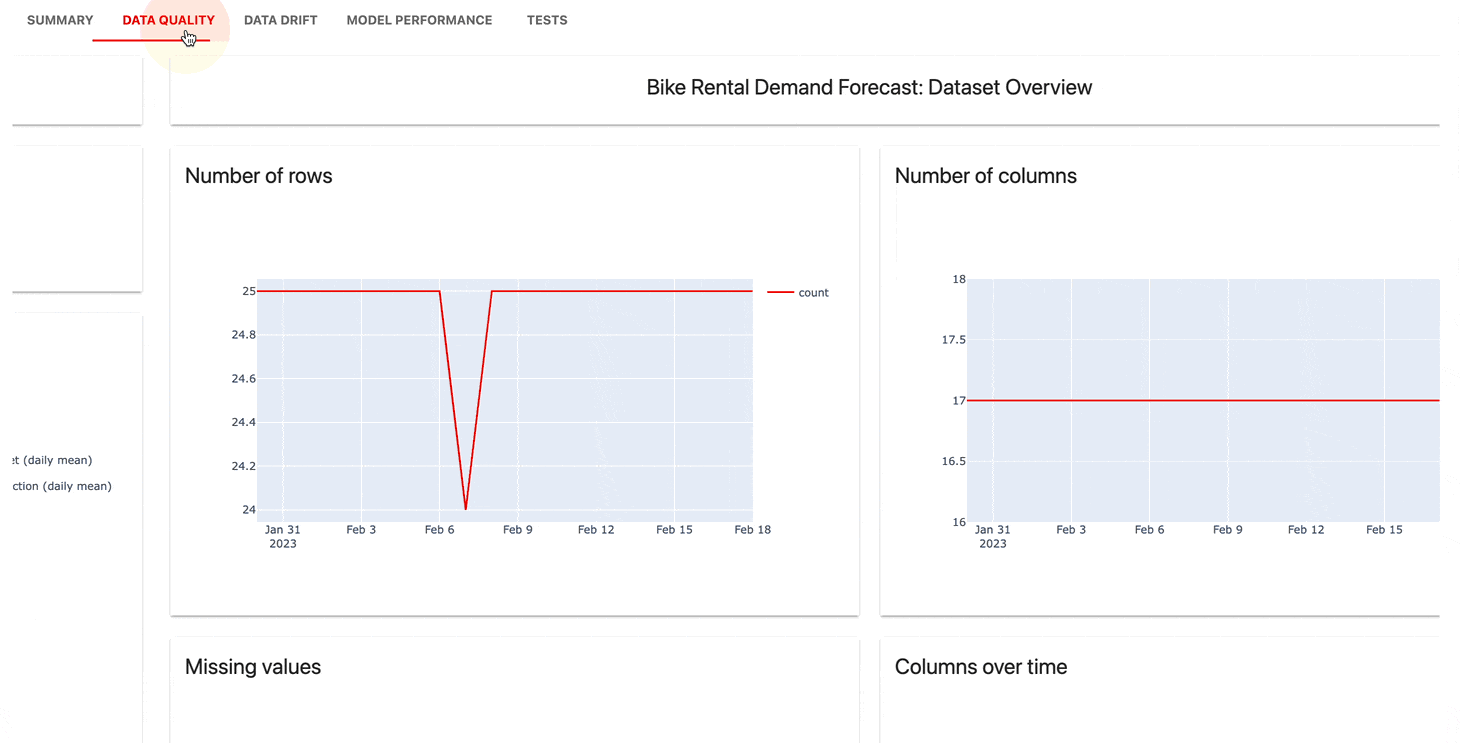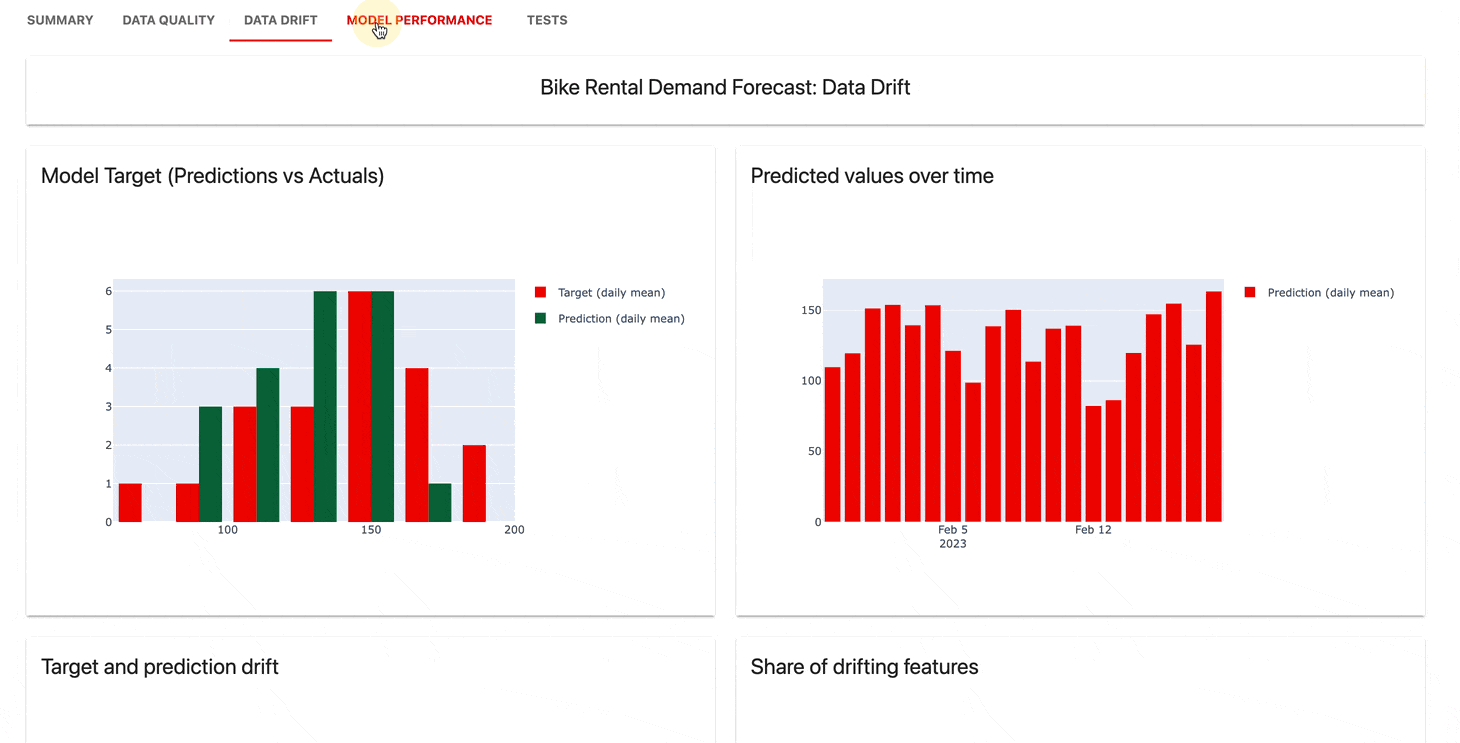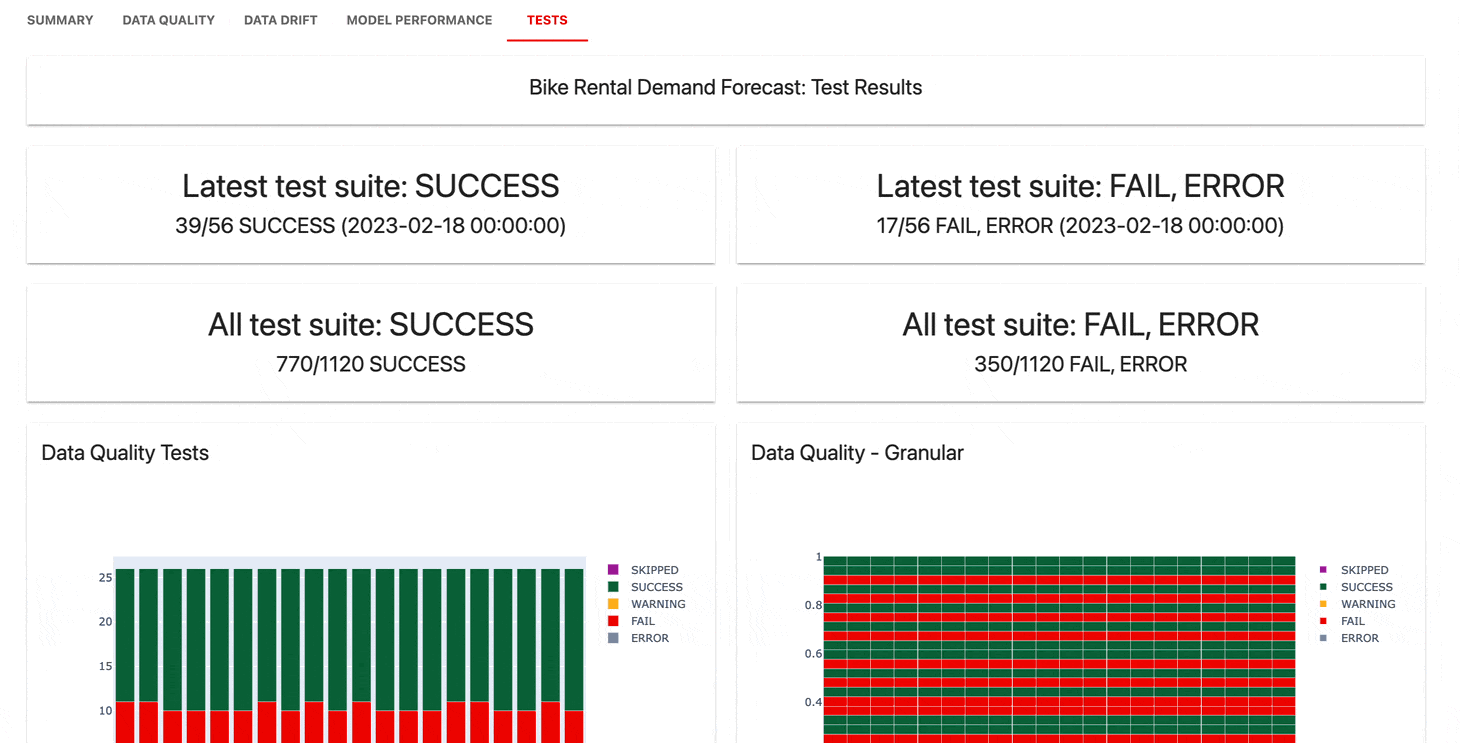
Der Überwachungs-UI- Dienst hilft bei der Visualisierung von Metriken und Testergebnissen im Zeitverlauf.
Sie können wählen:
Offensichtlich bietet Cloud ein großzügiges kostenloses Kontingent und zusätzliche Funktionen wie Benutzerverwaltung, Benachrichtigungen und No-Code-Bewertungen.
| Armaturenbrett |
|---|
 |
Offensichtlich ist es als PyPI-Paket verfügbar. Um es mit dem Pip-Paketmanager zu installieren, führen Sie Folgendes aus:
pip install evidentlyUm Evidently mit dem Conda-Installationsprogramm zu installieren, führen Sie Folgendes aus:
conda install -c conda-forge evidentlyDies ist eine einfache Hello World. Weitere Informationen finden Sie in den Tutorials: Tabellendaten oder LLM-Auswertung.
Importieren Sie die Testsuite , die Evaluierungsvoreinstellung und den tabellarischen Spielzeugdatensatz.
import pandas as pd
from sklearn import datasets
from evidently . test_suite import TestSuite
from evidently . test_preset import DataStabilityTestPreset
iris_data = datasets . load_iris ( as_frame = True )
iris_frame = iris_data . frame Teilen Sie den DataFrame in Referenz und aktuell auf. Führen Sie die Data Stability Test Suite aus, die automatisch Überprüfungen von Spaltenwertbereichen, fehlenden Werten usw. aus der Referenz generiert. Holen Sie sich die Ausgabe im Jupyter-Notebook:
data_stability = TestSuite ( tests = [
DataStabilityTestPreset (),
])
data_stability . run ( current_data = iris_frame . iloc [: 60 ], reference_data = iris_frame . iloc [ 60 :], column_mapping = None )
data_stabilitySie können auch eine HTML-Datei speichern. Sie müssen es im Zielordner öffnen.
data_stability . save_html ( "file.html" )Um die Ausgabe als JSON zu erhalten:
data_stability . json ()Sie können andere Voreinstellungen, einzelne Tests und festgelegte Bedingungen auswählen.
Importieren Sie den Bericht , die Bewertungsvorgabe und den tabellarischen Spielzeugdatensatz.
import pandas as pd
from sklearn import datasets
from evidently . report import Report
from evidently . metric_preset import DataDriftPreset
iris_data = datasets . load_iris ( as_frame = True )
iris_frame = iris_data . frame Führen Sie den Datendriftbericht aus, der die Spaltenverteilungen zwischen current und reference vergleicht:
data_drift_report = Report ( metrics = [
DataDriftPreset (),
])
data_drift_report . run ( current_data = iris_frame . iloc [: 60 ], reference_data = iris_frame . iloc [ 60 :], column_mapping = None )
data_drift_reportSpeichern Sie den Bericht als HTML. Sie müssen es später im Zielordner öffnen.
data_drift_report . save_html ( "file.html" )Um die Ausgabe als JSON zu erhalten:
data_drift_report . json ()Sie können weitere Voreinstellungen und individuelle Metriken auswählen, einschließlich LLM-Auswertungen für Textdaten.
Dadurch wird ein Demoprojekt in der Evidently-Benutzeroberfläche gestartet. Sehen Sie sich die Tutorials für Self-Hosting oder Evidently Cloud an.
Empfohlener Schritt: Erstellen Sie eine virtuelle Umgebung und aktivieren Sie diese.
pip install virtualenv
virtualenv venv
source venv/bin/activate
Führen Sie nach der Installation von Evidently ( pip install evidently ) die Evidently-Benutzeroberfläche mit den Demoprojekten aus:
evidently ui --demo-projects all
Greifen Sie in Ihrem Browser auf den Evidently UI-Dienst zu. Gehen Sie zu localhost:8000 .
Verfügt offensichtlich über mehr als 100 integrierte Auswertungen. Sie können auch benutzerdefinierte hinzufügen. Für jede Metrik gibt es eine optionale Visualisierung: Sie können sie in Reports , Test Suites oder in einem Dashboard grafisch darstellen.
Hier sind Beispiele für Dinge, die Sie überprüfen können:
| ? Textdeskriptoren | LLM-Ausgänge |
| Länge, Stimmung, Toxizität, Sprache, Sonderzeichen, Übereinstimmungen mit regulären Ausdrücken usw. | Semantische Ähnlichkeit, Retrieval-Relevanz, Zusammenfassungsqualität usw. mit modell- und LLM-basierten Auswertungen. |
| ? Datenqualität | Drift der Datenverteilung |
| Fehlende Werte, Duplikate, Min-Max-Bereiche, neue kategoriale Werte, Korrelationen usw. | Über 20 statistische Tests und Distanzmetriken zum Vergleich von Verschiebungen in der Datenverteilung. |
| Einstufung | ? Rückschritt |
| Genauigkeit, Präzision, Rückruf, ROC AUC, Verwirrungsmatrix, Bias usw. | MAE, ME, RMSE, Fehlerverteilung, Fehlernormalität, Fehlerverzerrung usw. |
| ? Ranking (inkl. RAG) | ? Empfehlungen |
| NDCG, MAP, MRR, Trefferquote usw. | Zufall, Neuheit, Vielfalt, Beliebtheitsbias usw. |
Wir freuen uns über Beiträge! Lesen Sie den Leitfaden, um mehr zu erfahren.
Weitere Informationen finden Sie in der vollständigen Dokumentation. Sie können mit den Tutorials beginnen:
Weitere Beispiele finden Sie in den Dokumenten.
Entdecken Sie die Anleitungen, um bestimmte Funktionen in Evidently zu verstehen.
Wenn Sie chatten und Kontakte knüpfen möchten, treten Sie unserer Discord-Community bei!


