WilmerAI
1.0.0
Dies ist ein persönliches Projekt, das sich in der intensiven Entwicklung befindet. Es könnte Fehler, unvollständigen Code oder andere unbeabsichtigte Probleme enthalten, was wahrscheinlich auch der Fall ist. Daher wird die Software so bereitgestellt, wie sie ist, ohne Gewährleistung jeglicher Art.
WilmerAI spiegelt die Arbeit eines einzelnen Entwicklers und den Einsatz seiner persönlichen Zeit und Ressourcen wider; Alle darin enthaltenen Ansichten, Methoden usw. sind seine eigenen und sollten sich nicht auf seinen Arbeitgeber auswirken.
WilmerAI ist ein hochentwickeltes Middleware-System, das eingehende Eingabeaufforderungen entgegennimmt und verschiedene Aufgaben auf ihnen ausführt, bevor es sie an LLM-APIs sendet. Diese Arbeit umfasst die Verwendung eines Large Language Model (LLM), um die Eingabeaufforderung zu kategorisieren und an den entsprechenden Workflow weiterzuleiten, oder die Verarbeitung eines großen Kontexts (mehr als 200.000 Token), um eine kleinere, besser verwaltbare Eingabeaufforderung zu generieren, die für die meisten lokalen Modelle geeignet ist.
WilmerAI steht für „What If Language Models Expertly Routed All Inference?“
Assistenten, die von mehreren LLMs im Tandem unterstützt werden : Eingehende Eingabeaufforderungen können an „Kategorien“ weitergeleitet werden, wobei jede Kategorie durch einen Workflow unterstützt wird. Jeder Workflow kann so viele Knoten haben, wie Sie möchten, wobei jeder Knoten von einem anderen LLM unterstützt wird. Wenn Sie beispielsweise Ihren Assistenten fragen: „Können Sie mir ein Snake-Spiel in Python schreiben?“, wird dies möglicherweise als CODING kategorisiert und in Ihren Codierungsworkflow übernommen. Der erste Knoten dieses Workflows fordert möglicherweise Codestral-22b (oder ChatGPT 4o, wenn Sie möchten) auf, die Frage zu beantworten. Der zweite Knoten könnte Deepseek V2 oder Claude Sonnet bitten, den Code zu überprüfen. Der nächste Knoten bittet Codestral möglicherweise, noch einmal zu antworten und Ihnen dann zu antworten. Ob Ihr Workflow nur aus einem einzelnen Modell besteht, das antwortet, weil es Ihr bester Programmierer ist, oder ob aus vielen Knoten verschiedener LLMs besteht, die zusammenarbeiten, um eine Antwort zu generieren – Sie haben die Wahl.
Unterstützung für die Offline-Wikipedia-API : WilmerAI verfügt über einen Knoten, der Aufrufe an die OfflineWikipediaTextApi tätigen kann. Das bedeutet, dass Sie eine Kategorie haben können, zum Beispiel „FACTUAL“, die Ihre eingehende Nachricht prüft, daraus eine Abfrage generiert, die Wikipedia-API nach einem verwandten Artikel abfragt und diesen Artikel als RAG-Kontextinjektion verwendet, um zu antworten.
Kontinuierlich generierte Chat-Zusammenfassungen zur Simulation einer „Erinnerung“ : Der Knoten „Chat-Zusammenfassung“ generiert „Erinnerungen“, indem er Ihre Nachrichten in Blöcke aufteilt, sie dann zusammenfasst und in einer Datei speichert. Anschließend werden diese zusammengefassten Teile verwendet und eine fortlaufende, ständig aktualisierte Zusammenfassung der gesamten Konversation erstellt, die innerhalb der Eingabeaufforderung an das LLM abgerufen und verwendet werden kann. Die Ergebnisse ermöglichen es Ihnen, über 200.000 Kontextgespräche zu führen und den relativen Überblick über das Gesagte zu behalten, selbst wenn Sie die Eingabeaufforderungen im LLM auf 5.000 Kontext oder weniger beschränken.
Verwenden Sie mehrere Computer, um Erinnerungen und Antworten parallel zu verarbeiten : Wenn Sie über zwei Computer verfügen, auf denen LLMs ausgeführt werden können, können Sie einen als „Responder“ und einen als Verantwortlichen für die Generierung von Erinnerungen/Zusammenfassungen festlegen. Mit dieser Art von Arbeitsablauf können Sie weiterhin mit Ihrem LLM kommunizieren, während die Erinnerungen/Zusammenfassungen aktualisiert werden, während Sie weiterhin die vorhandenen Erinnerungen verwenden. Das bedeutet, dass Sie nie auf die Aktualisierung der Zusammenfassung warten müssen, selbst wenn Sie ein großes und leistungsstarkes Modell damit beauftragen, diese Aufgabe zu erledigen, sodass Sie über qualitativ hochwertigere Erinnerungen verfügen. (Siehe Beispiel user convo-role-dual-model )
Multi-LLM-Gruppenchats in SillyTavern: Es ist möglich, Wilmer zu verwenden, um einen Gruppenchat in ST zu führen, in dem jeder Charakter ein anderer LLM ist, wenn Sie dies wünschen (der Autor macht dies persönlich). Es gibt Beispielcharaktere in DocsSillyTavern . in zwei Gruppen aufgeteilt. Diese Beispielzeichen/-gruppen sind Teilmengen größerer Gruppen, die der Autor verwendet.
Middleware-Funktionalität: WilmerAI sitzt zwischen der Schnittstelle, die Sie für die Kommunikation mit einem LLM (wie SillyTavern, OpenWebUI oder sogar dem Terminal eines Python-Programms) verwenden, und der Backend-API, die die LLMs bedient. Es kann mehrere Backend-LLMs gleichzeitig verarbeiten.
Mehrere LLMs gleichzeitig verwenden: Beispiel-Setup: SillyTavern -> WilmerAI -> mehrere Instanzen von KoboldCpp. Wilmer könnte beispielsweise mit Command-R 35b, Codestral 22b, Gemma-2-27b verbunden sein und alle diese in seinen Antworten an den Benutzer verwenden. Solange das LLM Ihrer Wahl über einen v1/Completion- oder Chat/Completion-Endpunkt oder den Generate-Endpunkt von KoboldCpp verfügbar gemacht wird, können Sie es verwenden.
Anpassbare Voreinstellungen : Voreinstellungen werden in einer JSON-Datei gespeichert, die Sie problemlos anpassen können. Fast alle Voreinstellungen können über JSON verwaltet werden, einschließlich der Parameternamen. Das bedeutet, dass Sie nicht auf ein Wilmer-Update warten müssen, um etwas Neues nutzen zu können. DRY erschien beispielsweise kürzlich auf KoboldCpp. Wenn das nicht im voreingestellten JSON für Wilmer enthalten war, sollten Sie es einfach hinzufügen und verwenden können.
API-Endpunkte: Es bietet OpenAI API-kompatible chat/Completions und v1/Completions Endpunkte, mit denen Sie über Ihr Front-End eine Verbindung herstellen können, und kann mit beiden Typen auf dem Back-End verbunden werden. Dies ermöglicht komplexe Konfigurationen, z. B. die Verbindung zu Wilmer als v1/Completion-API und die anschließende Verbindung von Wilmer mit Chat/Completion, v1/Completion KoboldCpp. Generieren Sie alle Endpunkte gleichzeitig.
Eingabeaufforderungsvorlagen: Unterstützt Eingabeaufforderungsvorlagen für v1/Completions -API-Endpunkte. WilmerAI verfügt außerdem über eine eigene Eingabeaufforderungsvorlage für Verbindungen von einem Frontend über v1/Completions . Die Vorlage befindet sich im Ordner „Docs“ und kann auf SillyTavern hochgeladen werden.
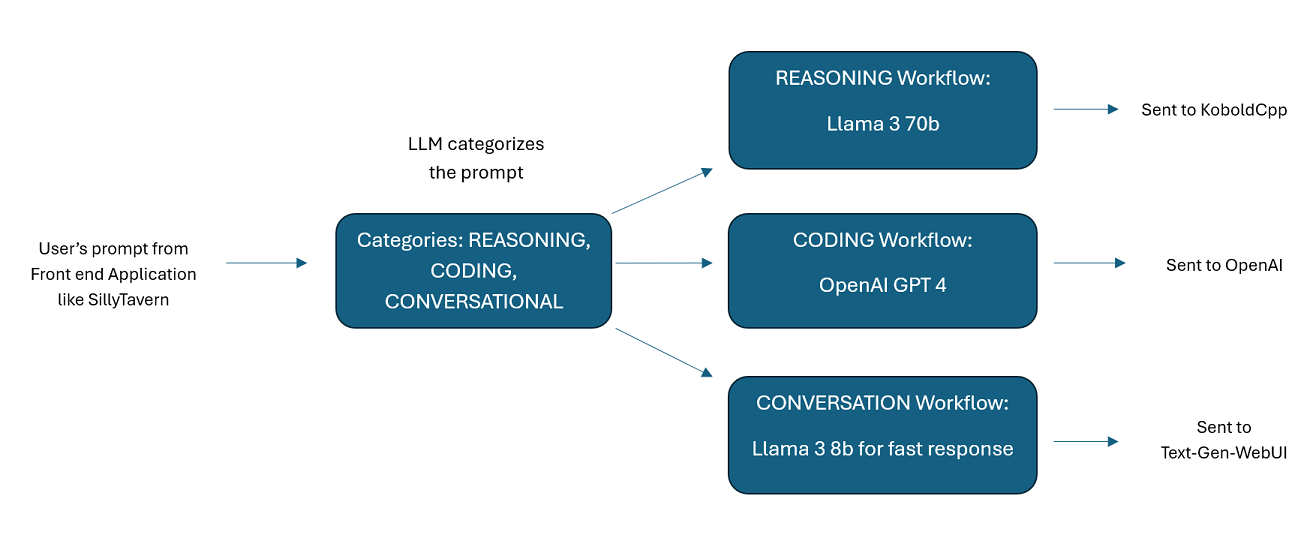
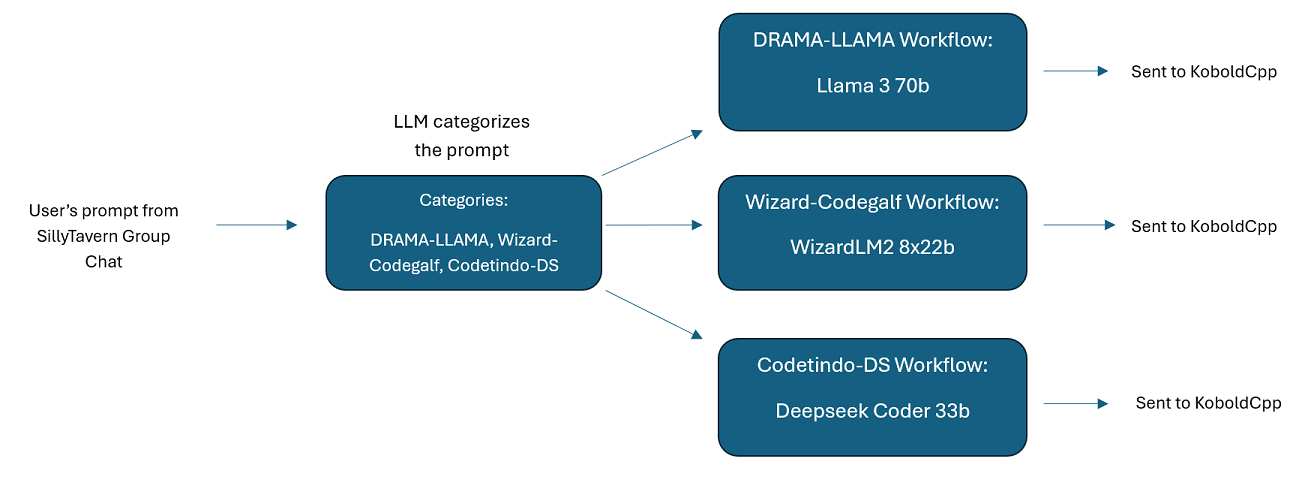
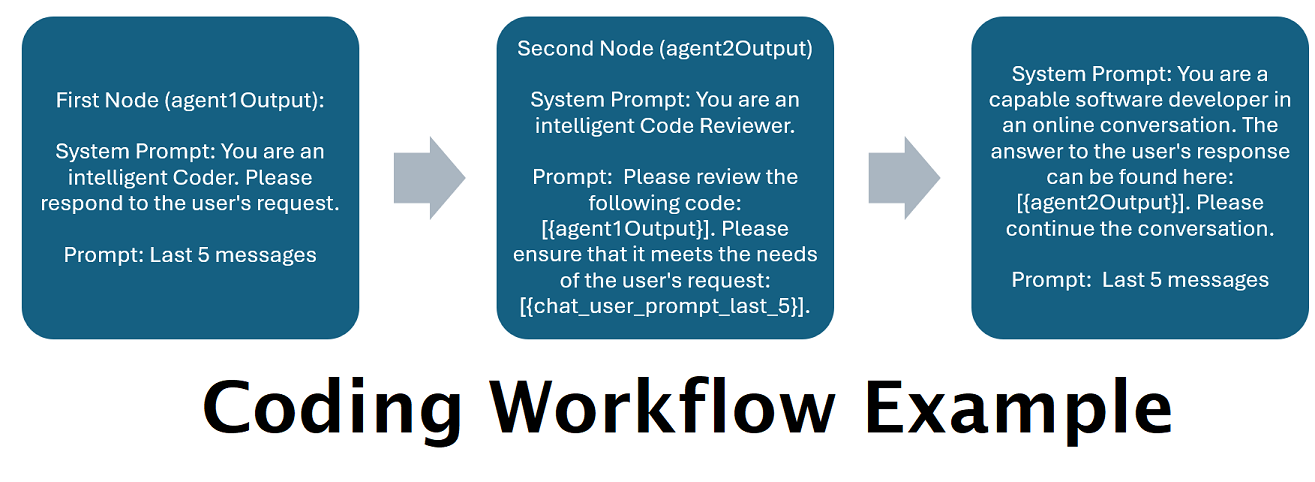
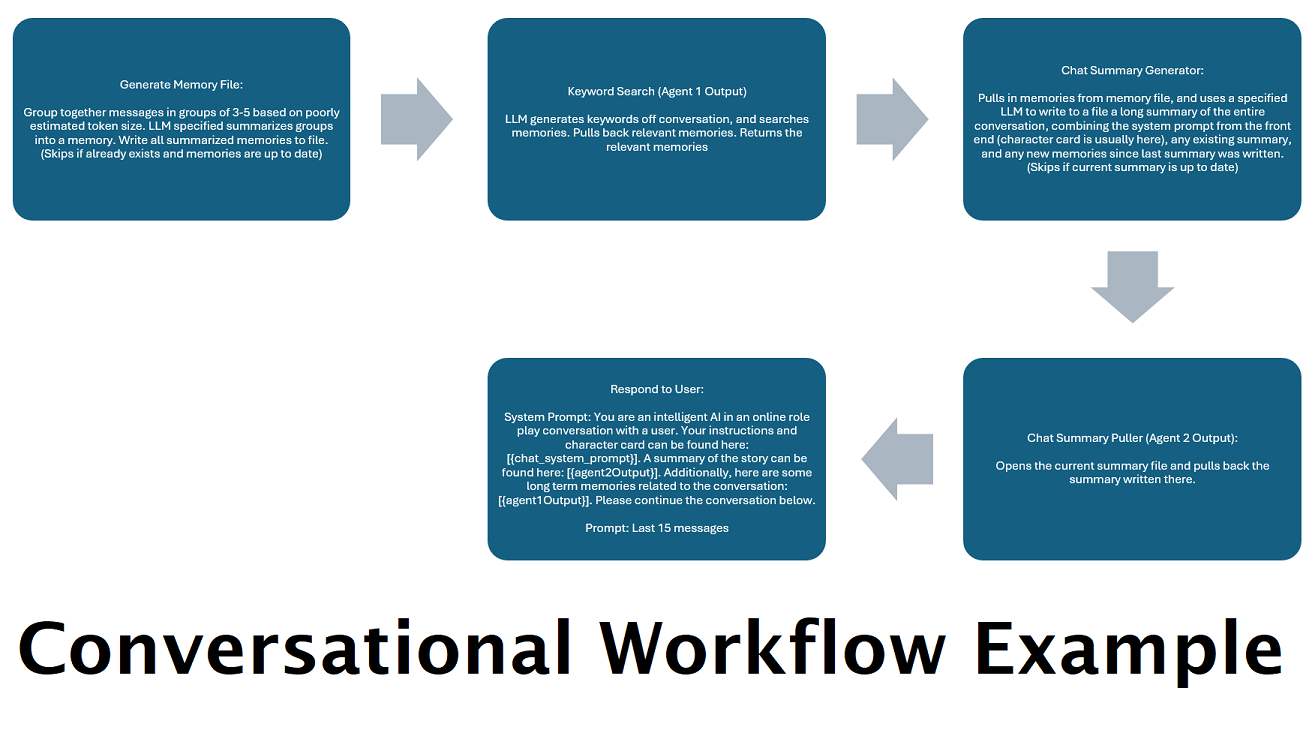

Bitte beachten Sie, dass Workflows naturgemäß viele Aufrufe an einen API-Endpunkt tätigen können, je nachdem, wie Sie sie einrichten. WilmerAI verfolgt die Token-Nutzung nicht, meldet über seine API keine genaue Token-Nutzung und bietet auch keine praktikable Möglichkeit zur Überwachung der Token-Nutzung. Wenn Ihnen die Verfolgung der Token-Nutzung aus Kostengründen wichtig ist, achten Sie bitte darauf, über jedes von Ihren LLM-APIs bereitgestellte Dashboard den Überblick darüber zu behalten, wie viele Token Sie verwenden, insbesondere zu Beginn, wenn Sie sich an diese Software gewöhnen.
Ihr LLM wirkt sich direkt auf die Qualität von WilmerAI aus. Hierbei handelt es sich um ein LLM-gesteuertes Projekt, bei dem die Abläufe und Ergebnisse fast vollständig von den verbundenen LLMs und ihren Reaktionen abhängen. Wenn Sie Wilmer mit einem Modell verbinden, das qualitativ minderwertige Ausgaben erzeugt, oder wenn Ihre Voreinstellungen oder Eingabeaufforderungsvorlagen Mängel aufweisen, ist auch die Gesamtqualität von Wilmer deutlich geringer. In dieser Hinsicht unterscheidet es sich nicht wesentlich von Agenten-Workflows.
Während der Autor sein Bestes tut, um etwas Nützliches und Qualitativ hochwertiges zu schaffen, ist dies ein ehrgeiziges Einzelprojekt, das zwangsläufig seine Probleme haben wird (vor allem, da der Autor kein nativer Python-Entwickler ist und sich stark auf KI verlassen hat, um dies zu erreichen). weit). Er findet es jedoch langsam heraus.
Wilmer stellt sowohl einen OpenAI v1/Completions- als auch einen Chat/Completions-Endpunkt zur Verfügung, wodurch er mit den meisten Frontends kompatibel ist. Obwohl ich dies hauptsächlich mit SillyTavern verwendet habe, funktioniert es möglicherweise auch mit Open-WebUI.
Um eine Verbindung als Textvervollständigung in SillyTavern herzustellen, befolgen Sie diese Schritte (der folgende Screenshot stammt von SillyTavern):
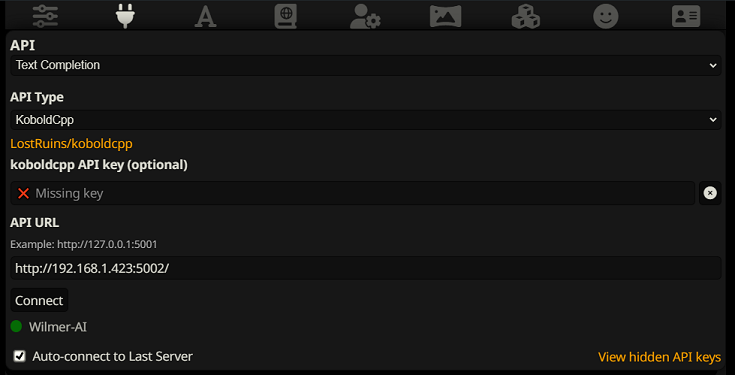
Wenn Sie Textvervollständigungen verwenden, müssen Sie ein WilmerAI-spezifisches Eingabeaufforderungsvorlagenformat verwenden. Eine importierbare ST-Datei finden Sie unter Docs/SillyTavern/InstructTemplate . Die Kontextvorlage ist ebenfalls enthalten, wenn Sie diese ebenfalls verwenden möchten.
Die Anleitungsvorlage sieht so aus:
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
Von SillyTavern:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
Es gibt keine erwarteten Zeilenumbrüche oder Zeichen zwischen den Tags.
Bitte stellen Sie sicher, dass die Kontextvorlage „Aktiviert“ ist (Kontrollkästchen über dem Dropdown-Menü).
Um eine Verbindung als Chat-Abschluss in SillyTavern herzustellen, befolgen Sie diese Schritte (der folgende Screenshot stammt von SillyTavern):
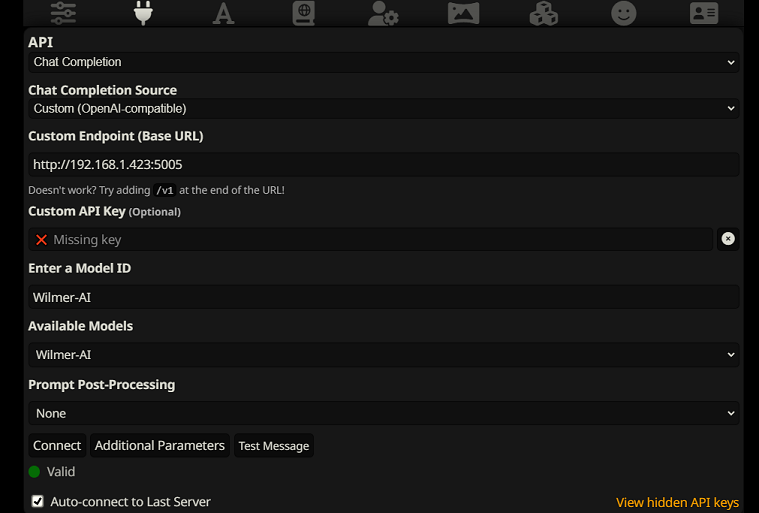
chatCompleteAddUserAssistant auf true. (Ich empfehle nicht, beide gleichzeitig auf „true“ zu setzen. Verwenden Sie entweder Charakternamen von SillyTavern ODER Benutzer/Assistenten von Wilmer. Die KI könnte sonst verwirrt werden.)Für beide Verbindungstypen empfehle ich, in SillyTavern auf das „A“-Symbol zu gehen und im Anweisungsmodus „Namen einbeziehen“ und „Gruppen und Personas erzwingen“ auszuwählen und dann zum Symbol ganz links (wo sich die Sampler befinden) zu gehen und „ Klicken Sie oben links auf „Stream“ und markieren Sie dann oben rechts unter „Kontext“ die Option „Entsperren“ und ziehen Sie den Eintrag auf „200.000+“. Lassen Sie Wilmer sich um den Kontext kümmern.
Wilmer verfügt derzeit über keine Benutzeroberfläche. Alles wird über JSON-Konfigurationsdateien gesteuert, die sich im Ordner „Public“ befinden. Dieser Ordner enthält alle wesentlichen Konfigurationen. Wenn Sie eine neue Kopie von WilmerAI aktualisieren oder herunterladen, sollten Sie einfach Ihren „Öffentlichen“ Ordner in die neue Installation kopieren, um Ihre Einstellungen beizubehalten.
Dieser Abschnitt führt Sie durch die Einrichtung von Wilmer. Ich habe die Abschnitte in Schritte unterteilt; Ich könnte empfehlen, jeden Schritt einzeln in ein LLM zu kopieren und es um Hilfe bei der Einrichtung des Abschnitts zu bitten. Das könnte die Sache viel einfacher machen.
WICHTIGE HINWEISE
Es ist wichtig, drei Dinge zum Wilmer-Setup zu beachten.
A) Voreingestellte Dateien sind zu 100 % anpassbar. Der Inhalt dieser Datei wird an die llm-API weitergeleitet. Dies liegt daran, dass Cloud-APIs einige der verschiedenen Voreinstellungen, die lokale LLM-APIs verarbeiten, nicht verarbeiten. Wenn Sie also die OpenAI-API oder andere Cloud-Dienste verwenden, werden die Aufrufe wahrscheinlich fehlschlagen, wenn Sie eine der regulären lokalen KI-Voreinstellungen verwenden. Ein Beispiel dafür, was openAI akzeptiert, finden Sie in der Voreinstellung „OpenAI-API“.
B) Ich habe kürzlich alle Aufforderungen in Wilmer ersetzt, um von der Verwendung der zweiten Person zur dritten Person überzugehen. Das hat für mich ziemlich gute Ergebnisse gebracht, und ich hoffe, dass es auch für Sie so sein wird.
C) Standardmäßig sind alle Benutzerdateien so eingestellt, dass Streaming-Antworten aktiviert sind. Sie müssen dies entweder in Ihrem Frontend aktivieren, das Wilmer aufruft, damit beide übereinstimmen, oder Sie müssen in Users/username.json gehen und Stream auf „false“ setzen. Wenn Sie eine Nichtübereinstimmung haben, bei der das Frontend Streaming erwartet/nicht erwartet und Ihr Wilmer das Gegenteil erwartet, wird auf dem Frontend wahrscheinlich nichts angezeigt.
Die Installation von Wilmer ist unkompliziert. Stellen Sie sicher, dass Python installiert ist. Der Autor hat das Programm mit Python 3.10 und 3.12 verwendet und beide funktionieren gut.
Option 1: Verwendung bereitgestellter Skripte
Der Einfachheit halber enthält Wilmer eine BAT-Datei für Windows und eine .sh-Datei für macOS. Diese Skripte erstellen eine virtuelle Umgebung, installieren die erforderlichen Pakete aus requirements.txt und führen dann Wilmer aus. Sie können diese Skripte verwenden, um Wilmer jedes Mal zu starten.
.bat Datei aus..sh Datei aus.WICHTIG: Führen Sie niemals eine BAT- oder SH-Datei aus, ohne sie vorher zu prüfen, da dies riskant sein kann. Wenn Sie sich über die Sicherheit einer solchen Datei nicht sicher sind, öffnen Sie sie in Notepad/TextEdit, kopieren Sie den Inhalt und bitten Sie dann Ihren LLM, sie auf mögliche Probleme zu überprüfen.
Option 2: Manuelle Installation
Alternativ können Sie die Abhängigkeiten manuell installieren und Wilmer mit den folgenden Schritten ausführen:
Installieren Sie die erforderlichen Pakete:
pip install -r requirements.txtStarten Sie das Programm:
python server.pyDie bereitgestellten Skripte sollen den Prozess durch die Einrichtung einer virtuellen Umgebung optimieren. Sie können sie jedoch getrost ignorieren, wenn Sie eine manuelle Installation bevorzugen.
HINWEIS : Wenn Sie entweder die bat-Datei, die sh-Datei oder die Python-Datei ausführen, akzeptieren alle drei jetzt die folgenden OPTIONAL-Argumente:
Betrachten Sie also beispielsweise die folgenden möglichen Läufe:
bash run_macos.sh (verwendet den in _current-user.json angegebenen Benutzer, Konfigurationen in „Public“, Protokolle in „logs“)bash run_macos.sh --User "single-model-assistant" (standardmäßig „public“ für Konfigurationen und „log“ für Protokolle)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" (wird nur die Standardeinstellung für "Protokolle" verwenden)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"Mit diesen optionalen Argumenten können Benutzer mehrere Instanzen von WilmerAI starten, wobei jede Instanz ein anderes Benutzerprofil verwendet, sich an einem anderen Ort anmeldet und bei Bedarf Konfigurationen an einem anderen Ort angibt.
Unter „Public/Configs“ finden Sie eine Reihe von Ordnern mit JSON-Dateien. Die beiden, die Sie am meisten interessieren, sind der Endpoints -Ordner und der Users -Ordner.
HINWEIS: Die Factual-Workflow-Knoten der Benutzer assistant-single-model , assistant-multi-model und group-chat-example werden versuchen, das OfflineWikipediaTextApi-Projekt zu nutzen, um vollständige Wikipedia-Artikel in RAG abzurufen. Wenn Sie diese API nicht haben, sollte der Workflow keine Probleme haben, aber ich persönlich verwende diese API, um die sachlichen Antworten, die ich erhalte, zu verbessern. Sie können die IP-Adresse Ihrer API im Benutzer-JSON Ihrer Wahl angeben.
Wählen Sie zunächst den Vorlagenbenutzer aus, den Sie verwenden möchten:
Assistant-Single-Model : Diese Vorlage ist für ein einzelnes kleines Modell gedacht, das auf allen Knoten verwendet wird. Dies verfügt auch über Routen für viele verschiedene Kategorietypen und verwendet entsprechende Voreinstellungen für jeden Knoten. Wenn Sie sich fragen, warum es Routen für verschiedene Kategorien gibt, wenn es nur ein Modell gibt: Dies geschieht, damit Sie jeder Kategorie ihre eigenen Voreinstellungen zuweisen und auch benutzerdefinierte Workflows für sie erstellen können. Vielleicht möchten Sie, dass der Programmierer mehrere Iterationen durchführt, um sich selbst zu überprüfen, oder dass die Argumentation die Dinge in mehreren Schritten durchdenkt.
Assistant-Multi-Model : Diese Vorlage dient zur gleichzeitigen Verwendung vieler Modelle. Wenn Sie sich die Endpunkte für diesen Benutzer ansehen, können Sie sehen, dass jede Kategorie ihren eigenen Endpunkt hat. Es gibt absolut nichts, was Sie davon abhält, dieselbe API für mehrere Kategorien wiederzuverwenden. Beispielsweise könnten Sie Llama 3.1 70b für Codierung, Mathematik und Argumentation und Command-R 35b 08-2024 für Kategorisierung, Konversation und Sachverhalt verwenden. Sie haben nicht das Gefühl, dass Sie 10 verschiedene Modelle BENÖTIGEN. Dies dient lediglich dazu, Ihnen die Möglichkeit zu geben, so viele mitzubringen, wenn Sie möchten. Dieser Benutzer verwendet für jeden Knoten in den Workflows entsprechende Voreinstellungen.
convo-roleplay-single-model : Dieser Benutzer verwendet ein einzelnes Modell mit einem benutzerdefinierten Workflow, der sich gut für Gespräche eignet und sich gut für Rollenspiele eignen sollte (er wartet auf Feedback, um es bei Bedarf anzupassen). Dadurch wird das gesamte Routing umgangen.
convo-roleplay-dual-model : Dieser Benutzer verwendet zwei Modelle mit einem benutzerdefinierten Workflow, der sich gut für Gespräche eignet und gut für Rollenspiele geeignet sein sollte (er wartet auf Feedback, um es bei Bedarf anzupassen). Dadurch wird das gesamte Routing umgangen. HINWEIS : Dieser Workflow funktioniert am besten, wenn Sie über zwei Computer verfügen, auf denen LLMs ausgeführt werden können. Wenn Sie mit der aktuellen Einrichtung für diesen Benutzer eine Nachricht an Wilmer senden, antwortet Ihnen das Responder-Modell (Computer 1). Dann wendet der Workflow an diesem Punkt eine „Workflow-Sperre“ an. Das Speicher-/Chat-Zusammenfassungsmodell (Computer 2) beginnt dann mit der Aktualisierung der Erinnerungen und der Zusammenfassung des bisherigen Gesprächs, die an den Antwortenden weitergegeben werden, damit dieser sich an Dinge erinnern kann. Wenn Sie während des Schreibens der Erinnerungen eine weitere Eingabeaufforderung senden, greift der Antwortende (Computer 1) auf die vorhandene Zusammenfassung und antwortet Ihnen. Die Workflow-Sperre verhindert, dass Sie den Abschnitt „Neue Erinnerungen“ erneut aufrufen. Das bedeutet, dass Sie weiterhin mit Ihrem Responder-Modell sprechen können, während neue Erinnerungen geschrieben werden. Das ist eine RIESIGE Leistungssteigerung. Ich habe es ausprobiert und die Reaktionszeiten waren für mich erstaunlich. Ohne dies erhalte ich drei- bis fünfmal innerhalb von 30 Sekunden Antworten und muss dann plötzlich zwei Minuten warten, um Erinnerungen zu generieren. Damit dauert jede Nachricht in Llama 3.1 70b auf meinem Mac Studio jedes Mal 30 Sekunden.
Gruppenchat-Beispiel : Dieser Benutzer ist ein Beispiel für meine persönlichen Gruppenchats. Die enthaltenen Charaktere und Gruppen sind tatsächliche Charaktere und tatsächliche Gruppen, die ich verwende. Sie finden die Beispielcharaktere im Ordner Docs/SillyTavern . Dabei handelt es sich um SillyTavern-kompatible Zeichen, die Sie direkt in dieses Programm oder jedes Programm importieren können, das .png-Zeichenimporttypen unterstützt. Die Charaktere des Entwicklerteams haben nur einen Knoten pro Workflow: Sie reagieren einfach auf Sie. Die Charaktere der Beratungsgruppe haben zwei Knoten pro Workflow: Der erste Knoten generiert eine Antwort und der zweite Knoten erzwingt die „Persona“ des Charakters (der dafür zuständige Endpunkt ist der businessgroup-speaker Endpunkt). Die Gruppenchat-Personas helfen sehr dabei, die Antworten, die Sie erhalten, zu variieren, selbst wenn Sie nur ein Modell verwenden. Mein Ziel ist es jedoch, für jeden Charakter unterschiedliche Modelle zu verwenden (jedoch Modelle zwischen Gruppen wiederzuverwenden; so habe ich beispielsweise in jeder Gruppe einen Llama 3.1 70b-Modellcharakter).
Nachdem Sie den Benutzer ausgewählt haben, den Sie verwenden möchten, müssen Sie einige Schritte ausführen:
Aktualisieren Sie die Endpunkte für Ihren Benutzer unter Public/Configs/Endpoints. Die Beispielzeichen sind jeweils in Ordner sortiert. Der Endpunktordner des Benutzers wird am Ende seiner user.json-Datei angegeben. Sie sollten jeden Endpunkt entsprechend den von Ihnen verwendeten LLMs ausfüllen. Einige Beispielendpunkte finden Sie im Ordner _example-endpoints .
Sie müssen Ihren aktuellen Benutzer festlegen. Sie können dies tun, wenn Sie die bat/sh/py-Datei ausführen, indem Sie das Argument --User verwenden, oder Sie können dies in Public/Configs/Users/_current-user.json tun. Geben Sie einfach den Namen des Benutzers als aktuellen Benutzer ein und speichern Sie.
Sie sollten Ihre Benutzer-JSON-Datei öffnen und einen Blick auf die Optionen werfen. Hier können Sie festlegen, ob Sie Streaming wünschen oder nicht, die IP-Adresse Ihrer Offline-Wiki-API festlegen (falls Sie diese verwenden), angeben, wohin Ihre Erinnerungen/Zusammenfassungsdateien während DiscussionId-Flows verschoben werden sollen, und auch angeben, wohin Sie möchten Ich möchte, dass die SQLite-Datenbank gelöscht wird, wenn Sie Workflow-Sperren verwenden.
Das ist es! Führen Sie Wilmer aus, stellen Sie eine Verbindung her, und schon kann es losgehen.
Zuerst richten wir die Endpunkte und Modelle ein. Im Ordner „Public/Configs“ sollten Sie die folgenden Unterordner sehen. Lassen Sie uns durchgehen, was Sie brauchen.
Diese Konfigurationsdateien stellen die LLM-API-Endpunkte dar, mit denen Sie verbunden sind. Beispielsweise definiert die folgende JSON-Datei, SmallModelEndpoint.json , einen Endpunkt:
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}Diese Konfigurationsdateien stellen die verschiedenen API-Typen dar, auf die Sie bei der Verwendung von Wilmer möglicherweise stoßen.
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
} Diese Dateien geben die Eingabeaufforderungsvorlage für ein Modell an. Betrachten Sie das folgende Beispiel, llama3.json :
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
} Diese Vorlagen werden auf alle v1/Completion-Endpunktaufrufe angewendet. Wenn Sie keine Vorlage verwenden möchten, gibt es eine Datei namens _chatonly.json , die Nachrichten nur mit Zeilenumbrüchen aufteilt.
Das Erstellen und Aktivieren eines Benutzers umfasst vier Hauptschritte. Befolgen Sie die nachstehenden Anweisungen, um einen neuen Benutzer einzurichten.
Erstellen Sie zunächst im Ordner Users eine JSON-Datei für den neuen Benutzer. Der einfachste Weg, dies zu tun, besteht darin, eine vorhandene JSON-Benutzerdatei zu kopieren, sie als Duplikat einzufügen und sie dann umzubenennen. Hier ist ein Beispiel einer Benutzer-JSON-Datei:
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0 , sodass es in Ihrem Netzwerk sichtbar ist, wenn es auf einem anderen Computer ausgeführt wird. Das Ausführen mehrerer Instanzen von Wilmer auf verschiedenen Ports wird unterstützt.true ist der Router deaktiviert und alle Eingabeaufforderungen gehen nur an den angegebenen Workflow, wodurch dieser zu einer einzelnen Workflow-Instanz von Wilmer wird.customWorkflowOverride true ist.Routing Ordner, ohne die Erweiterung .json .DiscussionId zu vermeiden.chatCompleteAddUserAssistant true ist.DataFinder Charakter der Beispielgruppe verwenden möchten. Aktualisieren Sie als Nächstes die Datei _current-user.json um anzugeben, welchen Benutzer Sie verwenden möchten. Passen Sie den Namen der neuen Benutzer-JSON-Datei ohne die Erweiterung .json an.
HINWEIS : Sie können dies ignorieren, wenn Sie stattdessen das Argument --User beim Ausführen von Wilmer verwenden möchten.
Erstellen Sie eine Routing-JSON-Datei im Routing Ordner. Diese Datei kann beliebig benannt werden. Aktualisieren Sie die Eigenschaft routingConfig in Ihrer Benutzer-JSON-Datei mit diesem Namen, abzüglich der Erweiterung .json . Hier ist ein Beispiel für eine Routing-Konfigurationsdatei:
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json , die ausgelöst wird, wenn die Kategorie ausgewählt wird. Erstellen Sie im Workflow Ordner einen neuen Ordner, der dem Benutzernamen aus dem Users entspricht. Der schnellste Weg, dies zu tun, besteht darin, den Ordner eines vorhandenen Benutzers zu kopieren, zu duplizieren und umzubenennen.
Wenn Sie keine weiteren Änderungen vornehmen möchten, müssen Sie die Arbeitsabläufe durchgehen und die Endpunkte aktualisieren, damit sie auf den gewünschten Endpunkt verweisen. Wenn Sie einen mit Wilmer hinzugefügten Beispielworkflow verwenden, sollten Sie hier bereits zufrieden sein.
Im Ordner „Öffentlich“ sollten Sie Folgendes haben:
Workflows in diesem Projekt werden im Ordner Public/Workflows innerhalb des spezifischen Workflows-Ordners Ihres Benutzers geändert und gesteuert. Wenn Ihr Benutzer beispielsweise socg heißt und Sie eine Datei socg.json im Ordner Users haben, sollten Sie innerhalb von Workflows einen Ordner Workflows/socg haben.
Hier ist ein Beispiel dafür, wie ein Workflow-JSON aussehen könnte:
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
]Der obige Workflow besteht aus Konversationsknoten. Beide Knoten tun eine einfache Sache: Sie senden eine Nachricht an den am Endpunkt angegebenen LLM.
title . Es ist hilfreich, diese mit „Eins“, „Zwei“ usw. zu benennen, um den Überblick über die Agentenausgabe zu behalten. Die Ausgabe des ersten Knotens wird in {agent1Output} gespeichert, die des zweiten in {agent2Output} und so weiter.Endpoints -Ordner ohne die Erweiterung .json übereinstimmen.Presets -Ordner ohne die Erweiterung .json übereinstimmen.false fest (siehe erster Beispielknoten oben). Wenn Sie eine Eingabeaufforderung senden, setzen Sie diese auf true (siehe zweiter Beispielknoten oben). NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
Sie können mehrere Variablen innerhalb dieser Eingabeaufforderungen verwenden. Diese werden zur Laufzeit angemessen ersetzt:
{chat_user_prompt_last_one} : Die letzte Nachricht in der Konversation, ohne dass die Eingabeaufforderung die Meldung umrundet.{templated_user_prompt_last_one} : Die letzte Nachricht in der Konversation, die in die entsprechenden Benutzer-/Assistenten -Eingabeaufforderung -Tags eingewickelt ist.{chat_system_prompt} : Die vom Frontend gesendete Systemaufforderung. Enthält oft Charakterkarte und andere wichtige Informationen.{templated_system_prompt} : Die Systemaufforderung vom vorderen Ende, eingewickelt in das entsprechende System -Eingabeaufforderung -T -Tag.{agent#Output} : # wird durch die gewünschte Nummer ersetzt. Jeder Knoten generiert eine Agentenausgabe. Der erste Knoten ist immer 1, und jeder nachfolgende Knoten erhöht sich um 1. Zum Beispiel {agent1Output} für den ersten Knoten, {agent2Output} für die zweite usw.{category_colon_descriptions} : Zieht die Kategorien und Beschreibungen aus Ihrer Routing -JSON -Datei.{categoriesSeparatedByOr} : Zieht die Kategoriennamen, getrennt durch "oder".[TextChunk] : Eine spezielle Variable, die für den parallelen Prozessor einzigartig ist, wahrscheinlich nicht häufig verwendet.Hinweis: Für ein tieferes Verständnis der Funktionsweise von Erinnerungen finden Sie im Abschnitt "Verständniserinnerungen"
Dieser Knoten zieht die Anzahl von Erinnerungen (oder die neuesten Nachrichten, wenn keine Diskussion vorhanden ist) und fügt einen benutzerdefinierten Trennzeichen hinzu. Wenn Sie also eine Speicherdatei mit 3 Erinnerungen haben und einen Trennzeichen von " n ---------- n" wählen, erhalten Sie möglicherweise Folgendes:
This is the first memory
---------
This is the second memory
---------
This is the third memory
Wenn Sie diesen Knoten mit der Chat -Zusammenfassung kombinieren Es. Wenn Sie beide zusammen mit den letzten 15-20 Nachrichten zusammen das Senden von diesen zusammenstellen, können Sie den Eindruck einer kontinuierlichen und anhaltenden Erinnerung an den gesamten Chat bis zu den neuesten Nachrichten erwecken. Besondere Vorsorge, um gute Aufforderungen für die Generierung der Erinnerungen zu erstellen, kann dazu beitragen, sicherzustellen, dass die Details, die Ihnen wichtig sind, erfasst werden, während weniger relevante Details ignoriert werden.
Dieser Knoten wird keine neuen Erinnerungen erzeugen; Dies ist so, dass Workflow-Schlösser respektiert werden können, wenn Sie sie auf einem Mehrkomputer-Setup verwenden. Derzeit ist der Fullchatsummary -Knoten der beste Weg, um Erinnerungen zu generieren.


