SadTalker
v0.0.2 rc Release Note


TL;DR: einzelnes Porträtbild ?♂️ + Audio ? = Talking-Head-Video ?.
Die Lizenz wurde auf Apache 2.0 aktualisiert und wir haben die nichtkommerzielle Einschränkung entfernt
SadTalker wurde nun offiziell in Discord integriert, wo Sie es kostenlos durch das Senden von Dateien nutzen können. Sie können auch hochwertige Videos aus Textaufforderungen erstellen. Verbinden:
Wir haben eine Stable-Diffusion-Webui-Erweiterung veröffentlicht. Weitere Details finden Sie hier. Demo-Video
Der Vollbildmodus ist jetzt verfügbar! Weitere Details...
| Still+Enhancer in v0.0.1 | Still + Enhancer in v0.0.2 | Eingabebild @bagbag1815 |
|---|---|---|
still_e_n.mp4 | full_body_2.bus_chinese_enhanced.mp4 |  |
Mehrere neue Modi (Standbild-, Referenz- und Größenänderungsmodus) sind jetzt verfügbar!
Wir freuen uns, weitere Community-Demos auf bilibili, YouTube und X (#sadtalker) zu sehen.
Das bisherige Changelog finden Sie hier.
[12.06.2023] : Weitere neue Funktionen in der WebUI-Erweiterung hinzugefügt, siehe Diskussion hier.
[05.06.2023] : Veröffentlichung eines neuen 512x512px (Beta)-Gesichtsmodells. Einige Fehler behoben und die Leistung verbessert.
[15.04.2023] : Ein WebUI Colab-Notizbuch von @camenduru hinzugefügt:
[12.04.2023] : Ein detaillierteres WebUI-Installationsdokument hinzugefügt und ein Problem bei der Neuinstallation behoben.
[12.04.2023] : Die WebUI-Sicherheitsprobleme aufgrund von Paketen von Drittanbietern wurden behoben und der Ausgabepfad in sd-webui-extension optimiert.
[08.04.2023] : In v0.0.2 haben wir dem generierten Video ein Logo-Wasserzeichen hinzugefügt, um Missbrauch zu verhindern. Dieses Wasserzeichen wurde inzwischen in einer späteren Version entfernt.
[08.04.2023] : In v0.0.2 haben wir Funktionen für die vollständige Bildanimation und einen Link zum Herunterladen von Checkpoints von Baidu hinzugefügt. Wir haben auch die Enhancer-Logik optimiert.
Wir verfolgen neue Updates in Ausgabe Nr. 280.
Wenn Sie Probleme haben, lesen Sie bitte unsere FAQs, bevor Sie ein Problem eröffnen.
Community-Tutorials: 中文Windows教程 (Chinesisches Windows-Tutorial) | 日本語コース (Japanisches Tutorial).
Installieren Sie Anaconda, Python und git .
Erstellen Sie die Umgebung und installieren Sie die Anforderungen.
git clone https://github.com/OpenTalker/SadTalker.git
cd SadTalker
conda create -n sadtalker python=3.8
conda activate sadtalker
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements.txt
# ## Coqui TTS is optional for gradio demo.
# ## pip install TTS
Ein Video-Tutorial auf Chinesisch finden Sie hier. Sie können auch die folgenden Anweisungen befolgen:
scoop install git .ffmpeg , indem Sie diesem Tutorial folgen oder scoop verwenden: scoop install ffmpeg .git clone https://github.com/Winfredy/SadTalker.git ausführen.start.bat im Windows Explorer als normaler Benutzer ohne Administratorrechte aus und eine Gradio-basierte WebUI-Demo wird gestartet.Eine Anleitung zur Installation von SadTalker unter macOS finden Sie hier.
Weitere Tutorials finden Sie hier.
Sie können das folgende Skript unter Linux/macOS ausführen, um alle Modelle automatisch herunterzuladen:
bash scripts/download_models.sh Wir stellen auch einen Offline-Patch ( gfpgan/ ) zur Verfügung, sodass beim Generieren kein Modell heruntergeladen wird.
sadt )sadt )Modell erklärt:
| Modell | Beschreibung |
|---|---|
| checkpoints/mapping_00229-model.pth.tar | Vorab trainiertes MappingNet in Sadtalker. |
| checkpoints/mapping_00109-model.pth.tar | Vorab trainiertes MappingNet in Sadtalker. |
| checkpoints/SadTalker_V0.0.2_256.safetensors | verpackte Sadtalker-Checkpoints der alten Version, 256-Face-Rendering). |
| checkpoints/SadTalker_V0.0.2_512.safetensors | verpackte Sadtalker-Kontrollpunkte der alten Version, 512-Gesichtsrendering). |
| gfpgan/weights | Gesichtserkennung und erweiterte Modelle, die in facexlib und gfpgan verwendet werden. |
| Modell | Beschreibung |
|---|---|
| checkpoints/auido2exp_00300-model.pth | Vorab trainiertes ExpNet in Sadtalker. |
| checkpoints/auido2pose_00140-model.pth | Vorab trainiertes PoseVAE in Sadtalker. |
| checkpoints/mapping_00229-model.pth.tar | Vorab trainiertes MappingNet in Sadtalker. |
| checkpoints/mapping_00109-model.pth.tar | Vorab trainiertes MappingNet in Sadtalker. |
| checkpoints/facevid2vid_00189-model.pth.tar | Vorab trainiertes Face-Vid2vid-Modell aus dem Wiederauftauchen von Face-Vid2vid. |
| checkpoints/epoch_20.pth | Vortrainierter 3DMM-Extraktor in Deep3DFaceReconstruction. |
| checkpoints/wav2lip.pth | Hochpräzises Lippensynchronisationsmodell in Wav2lip. |
| checkpoints/shape_predictor_68_face_landmarks.dat | Gesichts-Wahrzeichenmodell, das in Dilb verwendet wird. |
| Kontrollpunkte/BFM | 3DMM-Bibliotheksdatei. |
| Kontrollpunkte/Hub | Gesichtserkennungsmodelle, die bei der Gesichtsausrichtung verwendet werden. |
| gfpgan/weights | Gesichtserkennung und erweiterte Modelle, die in facexlib und gfpgan verwendet werden. |
Der endgültige Ordner wird wie folgt angezeigt:
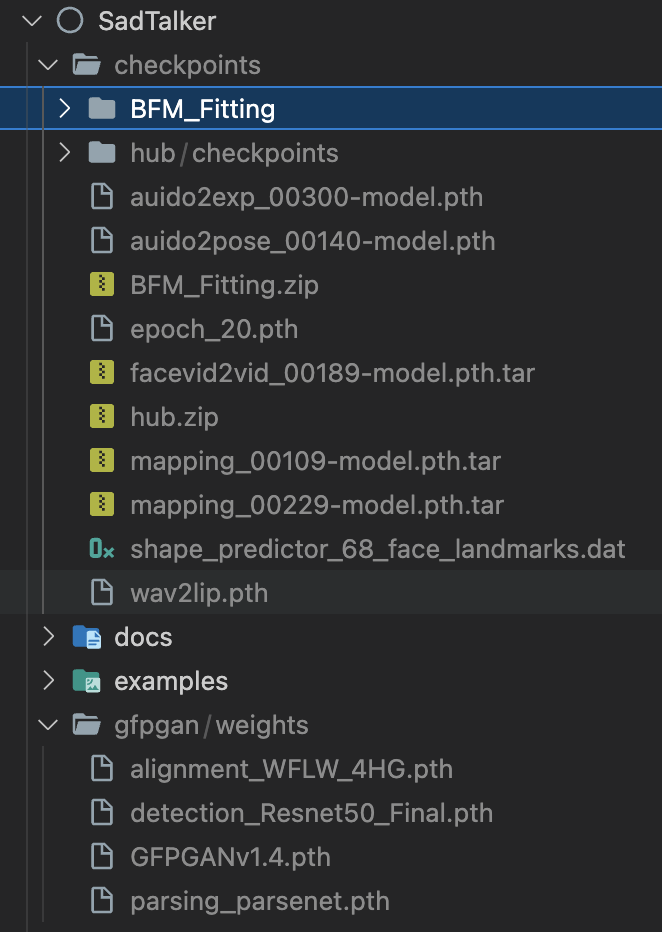
Bitte lesen Sie unser Dokument mit Best Practices und Konfigurationstipps
Online-Demo : HuggingFace | SDWebUI-Colab | Colab
Lokale WebUI-Erweiterung : Bitte beachten Sie die WebUI-Dokumente.
Lokale Gradio-Demo (empfohlen) : Eine Gradio-Instanz ähnlich unserer Hugging Face-Demo kann lokal ausgeführt werden:
# # you need manually install TTS(https://github.com/coqui-ai/TTS) via `pip install tts` in advanced.
python app_sadtalker.pySie können es auch einfacher starten:
webui.bat . Die Anforderungen werden automatisch installiert.bash webui.sh aus, um die Webui zu starten.python inference.py --driven_audio < audio.wav >
--source_image < video.mp4 or picture.png >
--enhancer gfpgan Die Ergebnisse werden in results/$SOME_TIMESTAMP/*.mp4 gespeichert.
Verwenden von --still , um ein natürliches Ganzkörpervideo zu erstellen. Sie können enhancer hinzufügen, um die Qualität des generierten Videos zu verbessern.
python inference.py --driven_audio < audio.wav >
--source_image < video.mp4 or picture.png >
--result_dir < a file to store results >
--still
--preprocess full
--enhancer gfpgan Weitere Beispiele sowie Konfigurations- und Tipps finden Sie in den >>>Best-Practice-Dokumenten<<<.
Wenn Sie unsere Arbeit für Ihre Forschung nützlich finden, denken Sie bitte darüber nach, Folgendes zu zitieren:
@article { zhang2022sadtalker ,
title = { SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation } ,
author = { Zhang, Wenxuan and Cun, Xiaodong and Wang, Xuan and Zhang, Yong and Shen, Xi and Guo, Yu and Shan, Ying and Wang, Fei } ,
journal = { arXiv preprint arXiv:2211.12194 } ,
year = { 2022 }
}Der Facerender-Code lehnt sich stark an Zhanglonghaos Reproduktion von face-vid2vid und PIRender an. Wir danken den Autoren für die Weitergabe ihres wunderbaren Codes. Im Trainingsprozess verwendeten wir auch das Modell von Deep3DFaceReconstruction und Wav2lip. Wir danken für ihre wunderbare Arbeit.
Wir verwenden außerdem die folgenden Bibliotheken von Drittanbietern:
Dies ist kein offizielles Produkt von Tencent.
1. Please carefully read and comply with the open-source license applicable to this code before using it.
2. Please carefully read and comply with the intellectual property declaration applicable to this code before using it.
3. This open-source code runs completely offline and does not collect any personal information or other data. If you use this code to provide services to end-users and collect related data, please take necessary compliance measures according to applicable laws and regulations (such as publishing privacy policies, adopting necessary data security strategies, etc.). If the collected data involves personal information, user consent must be obtained (if applicable). Any legal liabilities arising from this are unrelated to Tencent.
4. Without Tencent's written permission, you are not authorized to use the names or logos legally owned by Tencent, such as "Tencent." Otherwise, you may be liable for legal responsibilities.
5. This open-source code does not have the ability to directly provide services to end-users. If you need to use this code for further model training or demos, as part of your product to provide services to end-users, or for similar use, please comply with applicable laws and regulations for your product or service. Any legal liabilities arising from this are unrelated to Tencent.
6. It is prohibited to use this open-source code for activities that harm the legitimate rights and interests of others (including but not limited to fraud, deception, infringement of others' portrait rights, reputation rights, etc.), or other behaviors that violate applicable laws and regulations or go against social ethics and good customs (including providing incorrect or false information, spreading pornographic, terrorist, and violent information, etc.). Otherwise, you may be liable for legal responsibilities.
LOGO: Farb- und Schriftartvorschlag: ChatGPT, Logo-Schriftart: Montserrat Alternates.
Alle Urheberrechte an den Demobildern und Audiodateien liegen bei Community-Benutzern oder der Generation von Stable Diffusion. Wenn Sie diese entfernen möchten, können Sie sich gerne an uns wenden.


