KoGPT2
1.0.0
GPT-2 is a language model learned to well predict the next word in a given text and is optimized for sentence generation. KoGPT2 is a Korean decoder language model learned with over 40GB of text to overcome insufficient Korean language performance.
 |
Trained with Character BPE tokenizer from the tokenizers package.
The dictionary size is 51,200, and the recognition ability of the tokens has been increased by adding emoticons and emojis, such as those frequently used in conversations, as shown below.
?, ?, ?, ?, ?, .. ,
:-),:),-),(-:...
In addition, unused tokens such as <unused0> to <unused99> were defined so that they could be freely defined and used depending on the required task.
> from transformers import PreTrainedTokenizerFast
> tokenizer = PreTrainedTokenizerFast . from_pretrained ( "skt/ KoGPT2 -base-v2" ,
bos_token = '</s>' , eos_token = '</s>' , unk_token = '<unk>' ,
pad_token = '<pad>' , mask_token = '<mask>' )
> tokenizer . tokenize ( "안녕하세요. 한국어 GPT-2 입니다.?:)l^o" )
[ '▁안녕' , '하' , '세' , '요.' , '▁한국어' , '▁G' , 'P' , 'T' , '-2' , '▁입' , '니다.' , '?' , ':)' , 'l^o' ]| Model | # of params | Type | # of layers | # of heads | ffn_dim | hidden_dims |
|---|---|---|---|---|---|---|
KoGPT2 -base-v2 | 125M | Decoder | 12 | 12 | 3072 | 768 |
> import torch
> from transformers import GPT2LMHeadModel
> model = GPT2LMHeadModel . from_pretrained ( 'skt/ KoGPT2 -base-v2' )
> text = '근육이 커지기 위해서는'
> input_ids = tokenizer . encode ( text , return_tensors = 'pt' )
> gen_ids = model . generate ( input_ids ,
max_length = 128 ,
repetition_penalty = 2.0 ,
pad_token_id = tokenizer . pad_token_id ,
eos_token_id = tokenizer . eos_token_id ,
bos_token_id = tokenizer . bos_token_id ,
use_cache = True )
> generated = tokenizer . decode ( gen_ids [ 0 ])
> print ( generated )
근육이 커지기 위해서는 무엇보다 규칙적인 생활습관이 중요하다 .
특히 , 아침식사는 단백질과 비타민이 풍부한 과일과 채소를 많이 섭취하는 것이 좋다 .
또한 하루 30 분 이상 충분한 수면을 취하는 것도 도움이 된다 .
아침 식사를 거르지 않고 규칙적으로 운동을 하면 혈액순환에 도움을 줄 뿐만 아니라 신진대사를 촉진해 체내 노폐물을 배출하고 혈압을 낮춰준다 .
운동은 하루에 10 분 정도만 하는 게 좋으며 운동 후에는 반드시 스트레칭을 통해 근육량을 늘리고 유연성을 높여야 한다 .
운동 후 바로 잠자리에 드는 것은 피해야 하며 특히 아침에 일어나면 몸이 피곤해지기 때문에 무리하게 움직이면 오히려 역효과가 날 수도 있다 ...| NSMC(acc) | KorSTS(spearman) | |
|---|---|---|
| KoGPT2 2.0 | 89.1 | 77.8 |
In addition to the Korean Wikipedia, various data such as news and everyone's corpus v1.0 were used to train the model.
demo link
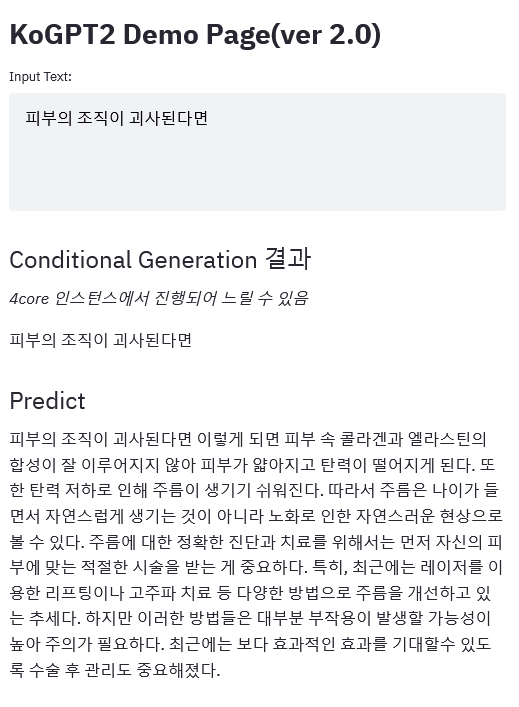 |
Please post issues related to KoGPT2 here.
KoGPT2 is released under the CC-BY-NC-SA 4.0 license. Please comply with the license terms when using models and codes. The full license can be found in the LICENSE file.


