gen ai document sumarization
1.0.0
Este proyecto explora el potencial de los modelos de IA generativa de código abierto, particularmente aquellos basados en la arquitectura Transformer, para automatizar el resumen del contenido de los documentos. El objetivo es evaluar y aplicar modelos de IA generativa existentes para analizar, comprender el contexto y generar resúmenes de documentos no estructurados.
Para lograr esto, he perfeccionado dos modelos destacados: t5-small y facebook/bart-base, centrándome en mejorar su rendimiento de resumen.
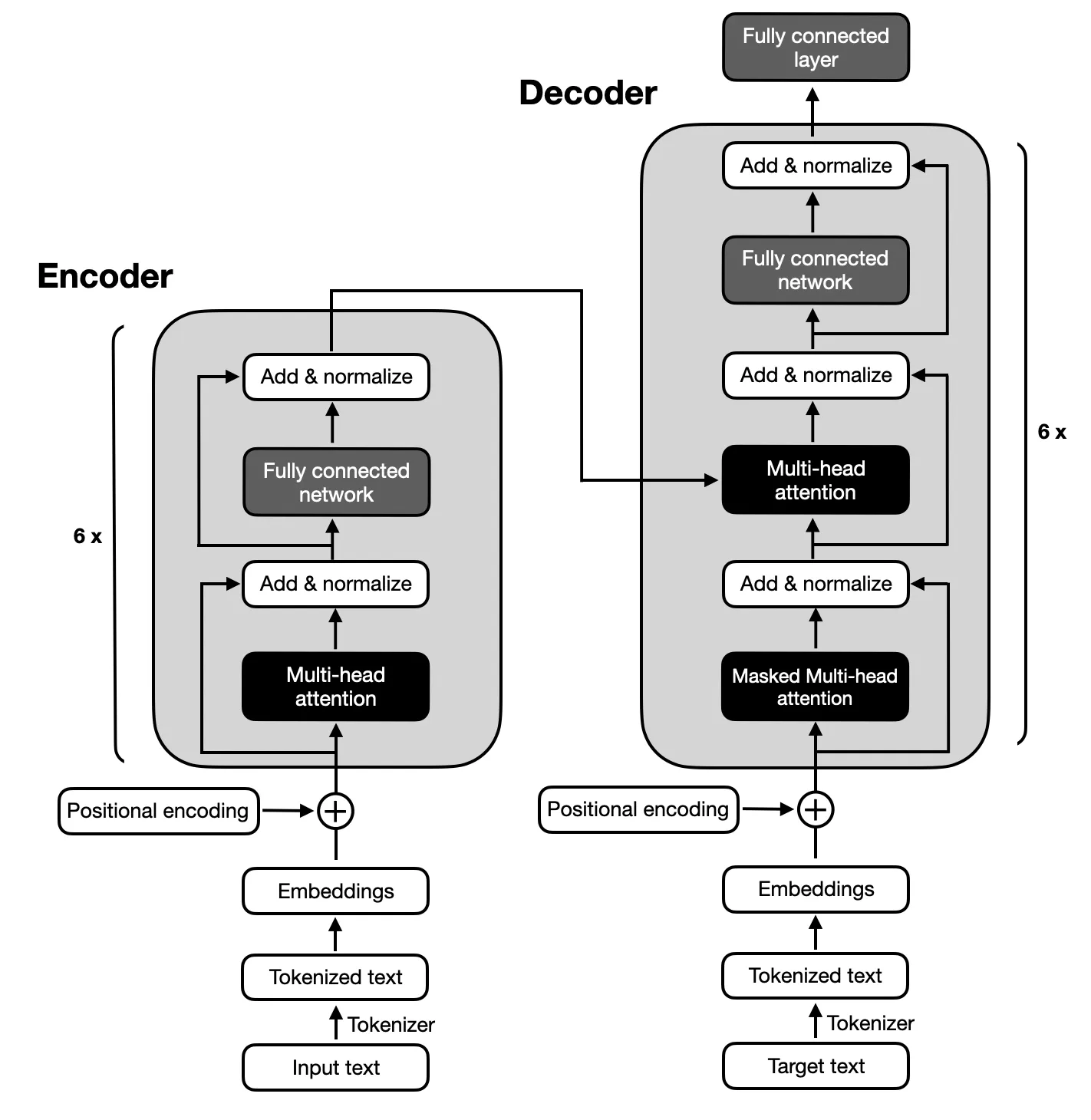
La atención se centra en los modelos de codificador-decodificador que siguen la arquitectura propuesta por los Transformers originales debido al mapeo complejo entre las secuencias de entrada y salida requeridas para el resumen de texto. Los modelos codificador-decodificador son expertos en capturar relaciones dentro de estas secuencias, lo que los hace adecuados para esta tarea.
Asegúrese de que Python 3.x esté instalado en su sistema. Luego, siga los pasos a continuación para configurar su entorno:
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.pyEl proyecto consta de seis fases principales:
El conjunto de datos utilizado para ajustar los modelos T5 y BART fue el Big Patent Dataset, que se compone de 1,3 millones de documentos de patentes estadounidenses junto con sus resúmenes abstractivos escritos por humanos. Cada documento de este conjunto de datos está clasificado según un código de Clasificación Cooperativa de Patentes (CPC), que cubre una amplia gama de temas, desde las necesidades humanas hasta la física y la electricidad. Esta diversidad garantiza que los modelos encuentren una amplia variedad de usos lingüísticos y jerga técnica, lo cual es crucial para desarrollar una capacidad de resumen sólida.
Se eligió el Big Patent Dataset debido a su relevancia para el objetivo del proyecto de resumir documentos complejos. Las patentes son inherentemente detalladas y técnicas, lo que las convierte en un desafío ideal para probar la capacidad de los modelos para condensar información preservando al mismo tiempo el contenido y el contexto central. El formato estructurado del conjunto de datos y la presencia de resúmenes de alta calidad proporcionan una base sólida para entrenar y evaluar el rendimiento de los modelos a la hora de generar resúmenes precisos y coherentes.
El rendimiento de los modelos se evaluó utilizando la métrica ROUGE, enfatizando su capacidad para generar resúmenes estrechamente alineados con los resúmenes escritos por humanos. Tanto el modelo BART como el T5 se perfeccionaron utilizando el Big Patent Dataset, centrándose en lograr resúmenes abstractos de alta calidad.
| Métrico | Valor |
|---|---|
| Pérdida de evaluación (pérdida de evaluación) | 1.9244 |
| rojo-1 | 0.5007 |
| rojo-2 | 0.2704 |
| Rouge-L | 0.3627 |
| Rouge-Lsum | 0.3636 |
| Duración promedio de la generación (Gen Len) | 122.1489 |
| Tiempo de ejecución (segundos) | 1459.3826 |
| Muestras por segundo | 1.312 |
| Pasos por segundo | 0.164 |
| Métrico | Valor |
|---|---|
| Pérdida de evaluación (pérdida de evaluación) | 1.9984 |
| rojo-1 | 0.503 |
| rojo-2 | 0.286 |
| Rouge-L | 0.3813 |
| Rouge-Lsum | 0.3813 |
| Duración promedio de la generación (Gen Len) | 151.918 |
| Tiempo de ejecución (segundos) | 714.4344 |
| Muestras por segundo | 2.679 |
| Pasos por segundo | 0.336 |


