build your local ragstack chatbot
1.0.0
Bienvenido a este taller para construir e implementar su propio Enterprise Co-Pilot usando Retrieval Augmented Generation con DataStax Enterprise v7, un inferenciador local y Mistral, un modelo de lenguaje grande local y abierto.
¡Este repositorio se centra en la seguridad manteniendo sus datos confidenciales dentro del firewall!
¿Por qué?
Aprovecha DataStax RAGStack, que es una pila seleccionada del mejor software de código abierto para facilitar la implementación del patrón RAG en aplicaciones listas para producción que utilizan DataStax Enterprise, Astra Vector DB o Apache Cassandra como almacén de vectores.
Lo que aprenderás:
? Cómo aprovechar DataStax RAGStack para el uso listo para producción de los siguientes componentes:
? Cómo utilizar Ollama como motor de inferencia local
? Cómo utilizar Mistral como modelo de lenguaje grande (LLM) local y abierto para chatbots estilo preguntas y respuestas
? ¡Cómo usar Streamlit para implementar fácilmente tu increíble aplicación!
Las diapositivas de la presentación se pueden encontrar AQUÍ
Este taller asume que usted tiene acceso a:
En los próximos pasos prepararemos el repositorio, DataStax Enterprise, un Jupyter Notebook y Ollama Inference Engine con Ollama.
Lo primero que necesitaremos es clonar este repositorio en su computadora portátil de desarrollo local.
Abra el repositorio build-your-local-ragstack-chatbot
Haga clic en Use this template -> Ceate new repository de la siguiente manera:
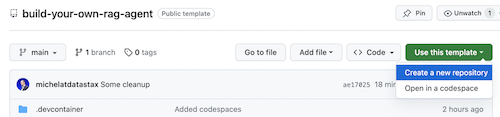
Ahora seleccione su cuenta de github y asigne un nombre al nuevo repositorio. Lo ideal es poner también la descripción. Haga clic en Create repository
¡Fresco! ¡Acabas de crear una copia en tu propia cuenta de Gihub!
cd a un directorio sensible (como /projects o algo así);git clone <url-to-your-repo>cd a su nuevo directorio!¡Y estás listo para rockear! ?
Es útil crear un entorno virtual . Utilice lo siguiente para configurarlo:
python3 -m venv myenv
Luego actívalo de la siguiente manera:
source myenv/bin/activate # on Linux/Mac
myenvScriptsactivate.bat # on Windows
Ahora puede comenzar a instalar los paquetes necesarios:
pip3 install -r requirements.txt
Ejecute DSE 7 de cualquiera de estas dos formas desde una ventana de terminal nueva:
docker-compose up
Esto utiliza el archivo docker-compose.yml en la raíz de este repositorio que también iniciará convenientemente el intérprete de Jupyter.
DataStax se ejecutará en http://localhost:9042 y se podrá acceder a Jupyter navegando a http://localhost:8888
Hay multitud de motores de inferencia. Puedes optar por LM Studio, que tiene una interfaz de usuario agradable. En este cuaderno usaremos Ollama.
ollama run mistral en una nueva ventana de terminalEn caso de que todo esto falle, debido a limitaciones de RAM, puedes optar por utilizar tinyllama como modelo.
Para comenzar este taller, primero probaremos los conceptos en el cuaderno suministrado. Suponemos que lo ejecutará desde un contenedor Jupyter Docker; en caso de que no sea así, cambie los nombres de host de host.docker.internal a localhost .
Este cuaderno muestra los pasos a seguir para utilizar DataStax Enterprise Vector Store como un medio para hacer que las interacciones LLM sean significativas y sin alucinaciones. El enfoque adoptado aquí es la generación aumentada de recuperación.
Aprenderás:
Vaya a http://localhost:8888 y abra el cuaderno que está disponible en la raíz llamado Build_Your_Own_RAG_Meetup.ipnb .
En este taller usaremos Streamlit, que es un marco increíblemente simple de usar para crear aplicaciones web front-end.
Para comenzar, creemos una aplicación de hola mundo de la siguiente manera:
import streamlit as st
# Draw a title and some markdown
st . markdown ( """# Your Enterprise Co-Pilot
Generative AI is considered to bring the next Industrial Revolution.
Why? Studies show a **37% efficiency boost** in day to day work activities!
### Security and safety
This Chatbot is safe to work with sensitive data. Why?
- First of all it makes use of [Ollama, a local inference engine](https://ollama.com);
- On top of the inference engine, we're running [Mistral, a local and open Large Language Model (LLM)](https://mistral.ai/);
- Also the LLM does not contain any sensitive or enterprise data, as there is no way to secure it in a LLM;
- Instead, your sensitive data is stored securely within the firewall inside [DataStax Enterprise v7 Vector Database](https://www.datastax.com/blog/get-started-with-the-datastax-enterprise-7-0-developer-vector-search-preview);
- And lastly, the chains are built on [RAGStack](https://www.datastax.com/products/ragstack), an enterprise version of Langchain and LLamaIndex, supported by [DataStax](https://www.datastax.com/).""" )
st . divider () El primer paso es importar el paquete streamlit. Luego llamamos st.markdown para escribir un título y, por último, escribimos contenido en la página web.
Para iniciar esta aplicación localmente, deberá instalar la dependencia streamlit de la siguiente manera (lo cual ya debería realizarse como parte de los requisitos previos):
pip install streamlitAhora ejecuta la aplicación:
streamlit run app_1.pyEsto iniciará el servidor de aplicaciones y lo llevará a la página web que acaba de crear.
Sencillo, ¿no? ?
En este paso, comenzaremos a preparar la aplicación para permitir la interacción del chatbot con un usuario. Usaremos los siguientes componentes de Streamlit: 1. 2. st.chat_input para que un usuario pueda ingresar una pregunta 2. st.chat_message('human') para dibujar la entrada del usuario 3. st.chat_message('assistant') para dibujar la respuesta del chatbot
Esto da como resultado el siguiente código:
# Draw the chat input box
if question := st . chat_input ( "What's up?" ):
# Draw the user's question
with st . chat_message ( 'human' ):
st . markdown ( question )
# Generate the answer
answer = f"""You asked: { question } """
# Draw the bot's answer
with st . chat_message ( 'assistant' ):
st . markdown ( answer ) Pruébelo usando app_2.py y comience de la siguiente manera.
Si su aplicación anterior aún se está ejecutando, simplemente elimínela presionando ctrl-c de antemano.
streamlit run app_2.pyAhora escriba una pregunta y vuelva a escribir otra. Verás que sólo se mantiene la última pregunta.
¿¿¿Por qué???
Esto se debe a que Streamlit volverá a dibujar toda la pantalla una y otra vez según la última entrada. Como no recordamos las preguntas, solo se muestra la última.
En este paso nos aseguraremos de realizar un seguimiento de las preguntas y respuestas para que con cada redibujo se muestre el historial.
Para ello seguiremos los siguientes pasos:
st.session_state llamado messagesst.session_state llamado messagesfor message in st.session_state.messages Este enfoque funciona porque session_state tiene estado en todas las ejecuciones de Streamlit.
Consulte el código completo en app_3.py.
Como verá, utilizamos un diccionario para almacenar tanto el role (que puede ser Humano o IA) como la question o answer . Es importante realizar un seguimiento del rol, ya que dibujará la imagen correcta en el navegador.
Ejecútelo con:
streamlit run app_3.pyAhora agregue varias preguntas y verá que se vuelven a dibujar en la pantalla cada vez que se vuelve a ejecutar Streamlit. ?
Aquí vincularemos el trabajo que hicimos usando Jupyter Notebook e integraremos la pregunta con una llamada al modelo de chat Mistral.
¿Recuerda que Streamlit vuelve a ejecutar el código cada vez que un usuario interactúa? Debido a esto, utilizaremos el almacenamiento en caché de datos y recursos en Streamlit para que la conexión solo se configure una vez. Usaremos @st.cache_data() y @st.cache_resource() para definir el almacenamiento en caché. cache_data se utiliza normalmente para estructuras de datos. cache_resource se utiliza principalmente para recursos como bases de datos.
Esto da como resultado el siguiente código para configurar el modelo de aviso y chat:
# Cache prompt for future runs
@ st . cache_data ()
def load_prompt ():
template = """You're a helpful AI assistent tasked to answer the user's questions.
You're friendly and you answer extensively with multiple sentences. You prefer to use bulletpoints to summarize.
QUESTION:
{question}
YOUR ANSWER:"""
return ChatPromptTemplate . from_messages ([( "system" , template )])
prompt = load_prompt ()
# Cache Mistral Chat Model for future runs
@ st . cache_resource ()
def load_chat_model ():
# parameters for ollama see: https://api.python.langchain.com/en/latest/chat_models/langchain_community.chat_models.ollama.ChatOllama.html
# num_ctx is the context window size
return ChatOllama (
model = "mistral:latest" ,
num_ctx = 18192 ,
base_url = st . secrets [ 'OLLAMA_ENDPOINT' ]
)
chat_model = load_chat_model ()En lugar de la respuesta estática que usamos en los ejemplos anteriores, ahora pasaremos a llamar a la Cadena:
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'question' : lambda x : x [ 'question' ]
})
chain = inputs | prompt | chat_model
response = chain . invoke ({ 'question' : question })
answer = response . contentConsulte el código completo en app_4.py.
Antes de continuar, debemos proporcionar OLLAMA_ENDPOINT en ./streamlit/secrets.toml . Hay un ejemplo proporcionado en secrets.toml.example :
# Ollama/Mistral Endpoint
OLLAMA_ENDPOINT = " http://localhost:11434 "Para iniciar esta aplicación localmente, necesitará instalar RAGStack, que contiene una versión estable de LangChain y todas las dependencias (lo cual ya debería realizarse como parte de los requisitos previos):
pip install ragstackAhora ejecuta la aplicación:
streamlit run app_4.pyAhora puede iniciar su interacción de preguntas y respuestas con el Chatbot. Por supuesto, como no existe integración con DataStax Enterprise Vector Store, no habrá respuestas contextualizadas. Como todavía no hay transmisión integrada, dale al agente un poco de tiempo para que dé la respuesta completa de inmediato.
Empecemos con la pregunta:
What does Daniel Radcliffe get when he turns 18?
Como verá, recibirá una respuesta muy genérica sin la información disponible en los datos de CNN.
¡Ahora las cosas se vuelven realmente interesantes! En este paso, integraremos DataStax Enterprise Vector Store para proporcionar contexto en tiempo real para el modelo de chat. Pasos tomados para implementar la Generación Aumentada de Recuperación:
Reutilizaremos los datos de CNN que insertamos gracias al cuaderno.
Para habilitar esto, primero debemos configurar una conexión a DataStax Enterprise Vector Store:
# Cache the DataStax Enterprise Vector Store for future runs
@ st . cache_resource ( show_spinner = 'Connecting to Datastax Enterprise v7 with Vector Support' )
def load_vector_store ():
# Connect to DSE
cluster = Cluster (
[ st . secrets [ 'DSE_ENDPOINT' ]]
)
session = cluster . connect ()
# Connect to the Vector Store
vector_store = Cassandra (
session = session ,
embedding = HuggingFaceEmbeddings (),
keyspace = st . secrets [ 'DSE_KEYSPACE' ],
table_name = st . secrets [ 'DSE_TABLE' ]
)
return vector_store
vector_store = load_vector_store ()
# Cache the Retriever for future runs
@ st . cache_resource ( show_spinner = 'Getting retriever' )
def load_retriever ():
# Get the retriever for the Chat Model
retriever = vector_store . as_retriever (
search_kwargs = { "k" : 5 }
)
return retriever
retriever = load_retriever ()Lo único que debemos hacer es modificar la Cadena para incluir una llamada a Vector Store:
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'context' : lambda x : retriever . get_relevant_documents ( x [ 'question' ]),
'question' : lambda x : x [ 'question' ]
})Consulte el código completo en app_5.py.
Antes de continuar, debemos proporcionar DSE_ENDPOINT , DSE_KEYSPACE y DSE_TABLE en ./streamlit/secrets.toml . Hay un ejemplo proporcionado en secrets.toml.example :
# DataStax Enterprise Endpoint
DSE_ENDPOINT = " localhost "
DSE_KEYSPACE = " default_keyspace "
DSE_TABLE = " dse_vector_table "Y ejecuta la aplicación:
streamlit run app_5.pyHagamos nuevamente la pregunta:
What does Daniel Radcliffe get when he turns 18?
Como verá, ahora recibirá una respuesta muy contextual ya que Vector Store proporciona datos CNN relevantes para el modelo de chat.
¡Qué genial sería ver la respuesta aparecer en la pantalla a medida que se genera! Bueno, eso es fácil.
En primer lugar, crearemos un controlador de devolución de llamada de transmisión que se invoca en cada nueva generación de token de la siguiente manera:
# Streaming call back handler for responses
class StreamHandler ( BaseCallbackHandler ):
def __init__ ( self , container , initial_text = "" ):
self . container = container
self . text = initial_text
def on_llm_new_token ( self , token : str , ** kwargs ):
self . text += token
self . container . markdown ( self . text + "▌" )A continuación explicamos el Modelo de Chat para hacer usuario del StreamHandler:
response = chain . invoke ({ 'question' : question }, config = { 'callbacks' : [ StreamHandler ( response_placeholder )]}) response_placeholer en el código anterior define el lugar donde se deben escribir los tokens. Podemos crear ese espacio llamando st.empty() de la siguiente manera:
# UI placeholder to start filling with agent response
with st . chat_message ( 'assistant' ):
response_placeholder = st . empty ()Consulte el código completo en app_6.py.
Y ejecuta la aplicación:
streamlit run app_6.pyAhora verá que la respuesta se escribirá en tiempo real en la ventana del navegador.
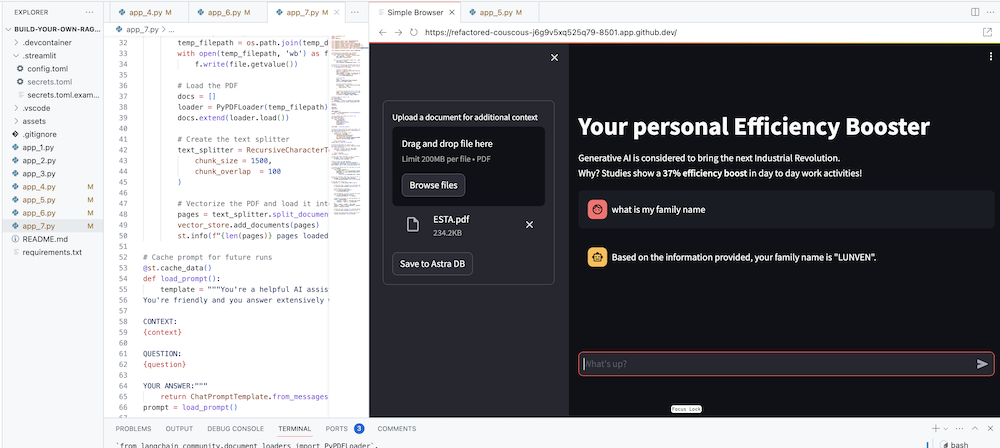
Por supuesto, el objetivo final es agregar el contexto de su propia empresa al agente. Para hacer esto, agregaremos un cuadro de carga que le permitirá cargar archivos PDF que luego se utilizarán para brindar una respuesta significativa y contextual.
Primero necesitamos un formulario de carga que sea sencillo de crear con Streamlit:
# Include the upload form for new data to be Vectorized
with st . sidebar :
with st . form ( 'upload' ):
uploaded_file = st . file_uploader ( 'Upload a document for additional context' , type = [ 'pdf' ])
submitted = st . form_submit_button ( 'Save to DataStax Enterprise' )
if submitted :
vectorize_text ( uploaded_file )Ahora necesitamos una función para cargar el PDF e ingerirlo en DataStax Enterprise mientras vectorizamos el contenido.
# Function for Vectorizing uploaded data into DataStax Enterprise
def vectorize_text ( uploaded_file , vector_store ):
if uploaded_file is not None :
# Write to temporary file
temp_dir = tempfile . TemporaryDirectory ()
file = uploaded_file
temp_filepath = os . path . join ( temp_dir . name , file . name )
with open ( temp_filepath , 'wb' ) as f :
f . write ( file . getvalue ())
# Load the PDF
docs = []
loader = PyPDFLoader ( temp_filepath )
docs . extend ( loader . load ())
# Create the text splitter
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1500 ,
chunk_overlap = 100
)
# Vectorize the PDF and load it into the DataStax Enterprise Vector Store
pages = text_splitter . split_documents ( docs )
vector_store . add_documents ( pages )
st . info ( f" { len ( pages ) } pages loaded." )Consulte el código completo en app_7.py.
Para iniciar esta aplicación localmente, necesitarás instalar la dependencia de PyPDF de la siguiente manera (lo cual ya debería hacerse como parte de los requisitos previos):
pip install pypdfY ejecuta la aplicación:
streamlit run app_7.pyAhora cargue un documento PDF (cuanto más, mejor) que sea relevante para usted y comience a hacer preguntas al respecto. ¡Verás que las respuestas serán relevantes, significativas y contextuales! ? ¡Mira cómo sucede la magia!