ai outpainting com
1.0.0
https://www.ai-outpainting.com
Page d'accueil 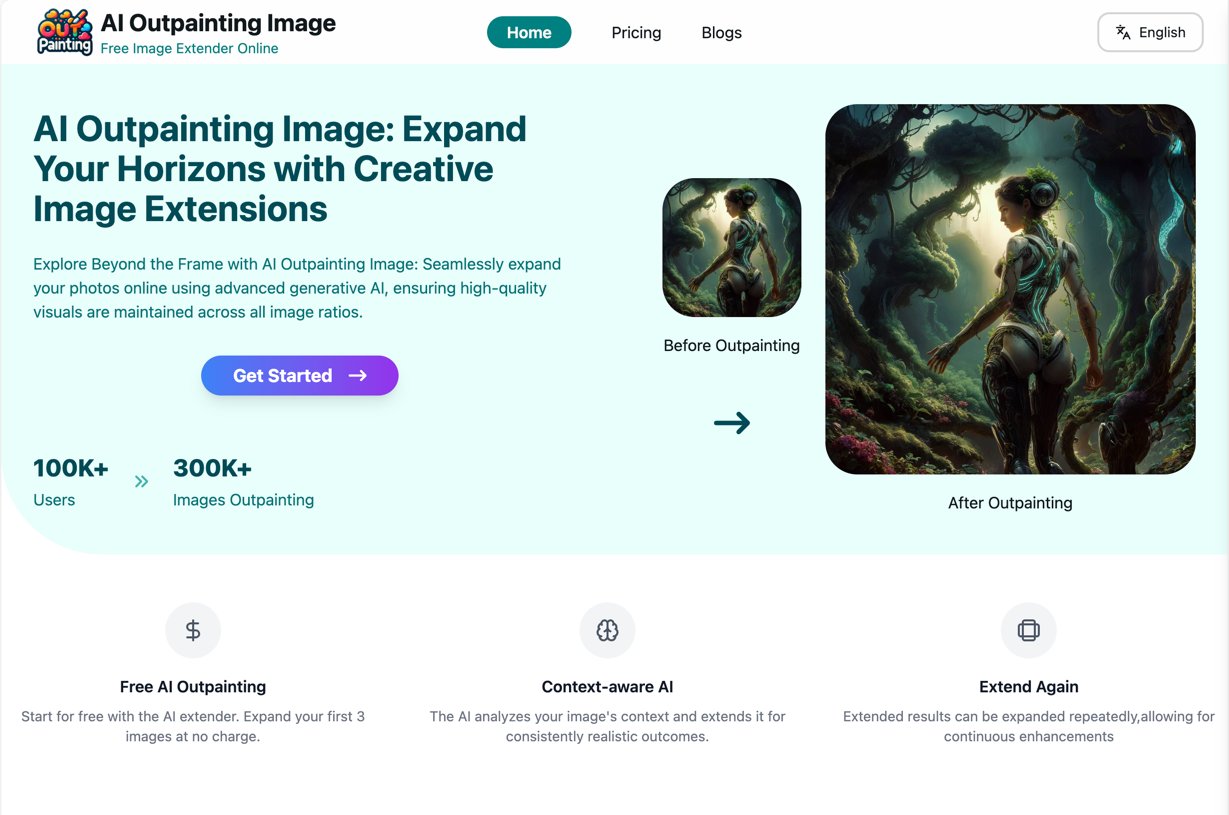
Page de prix 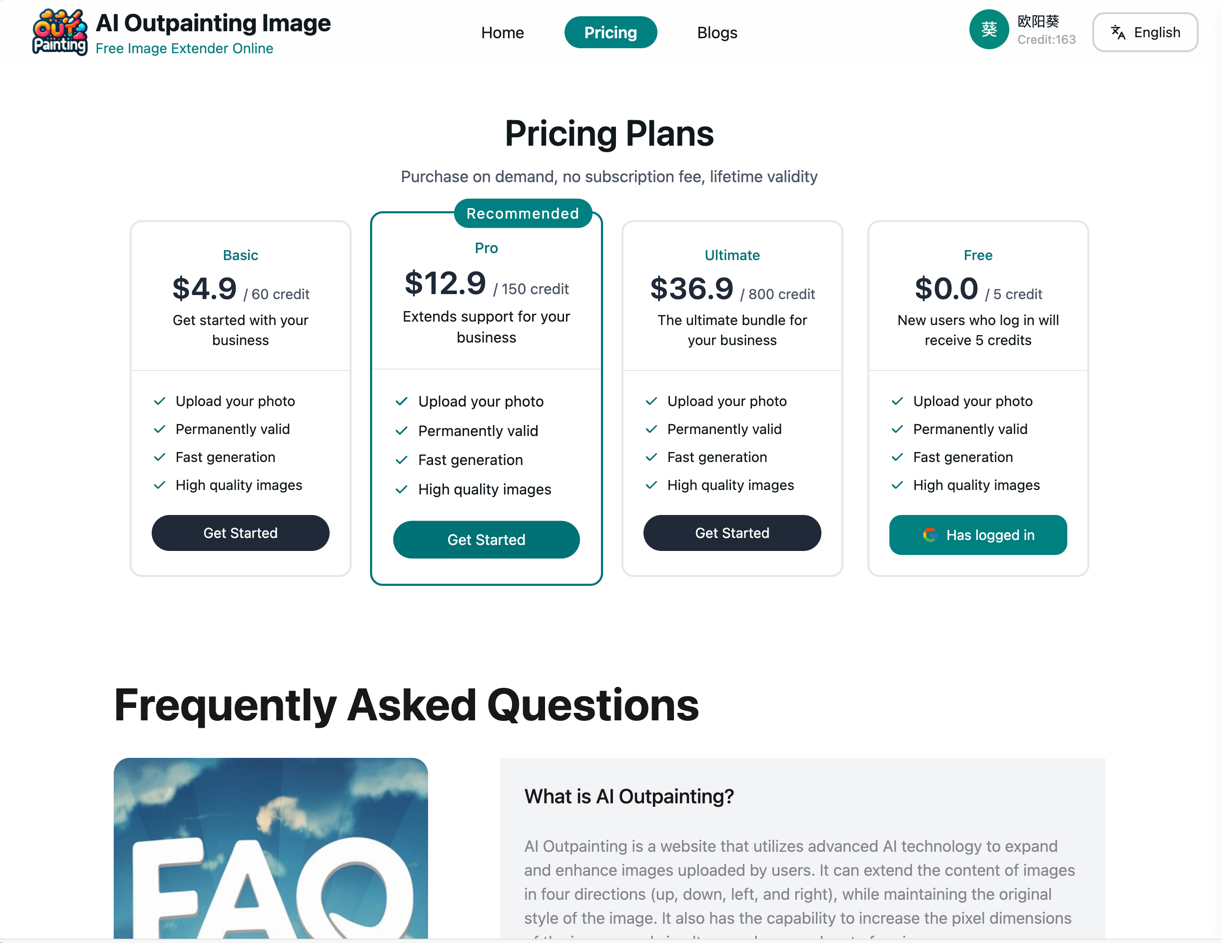
Liste des blogs 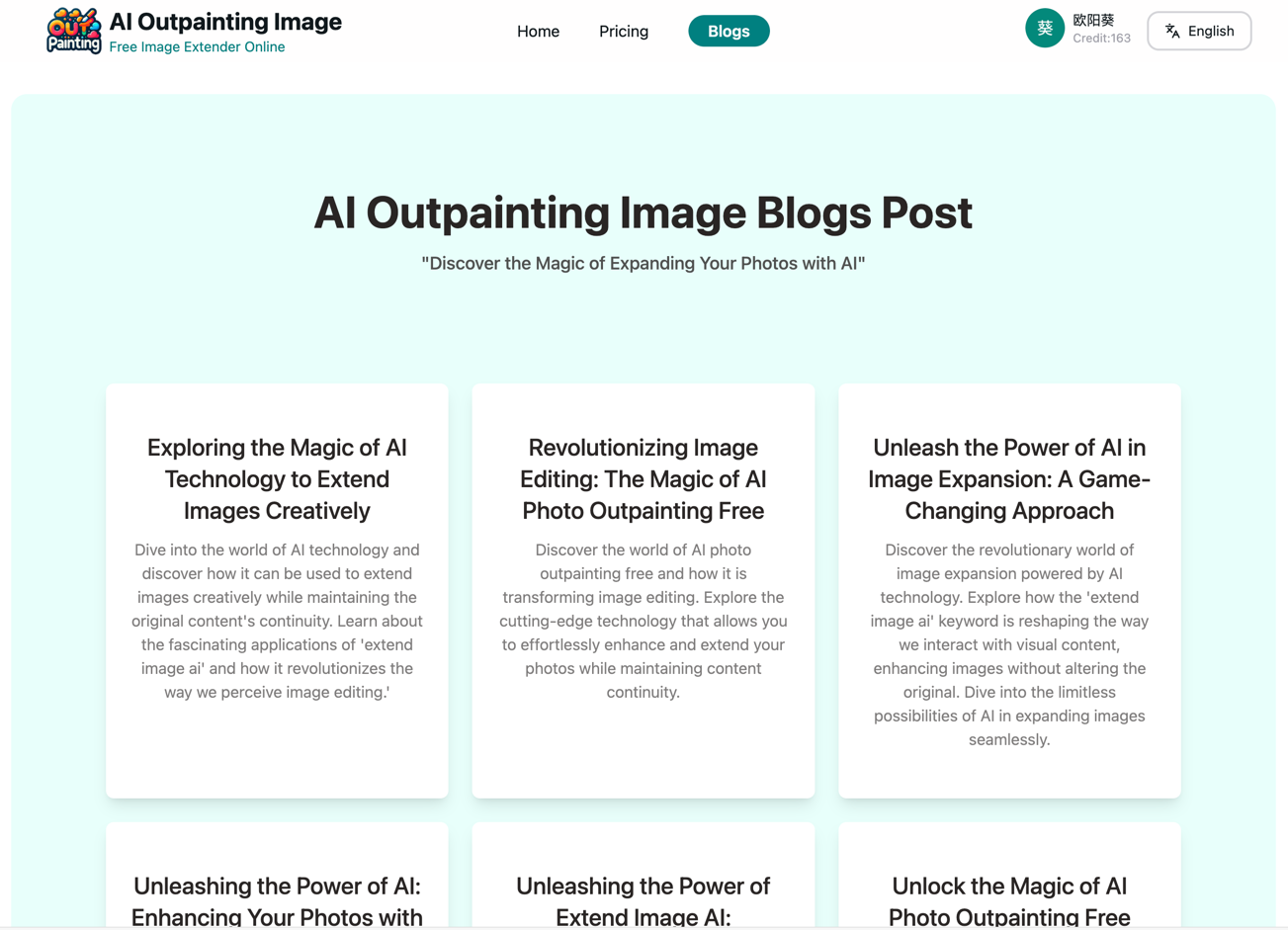
Retouche d'image 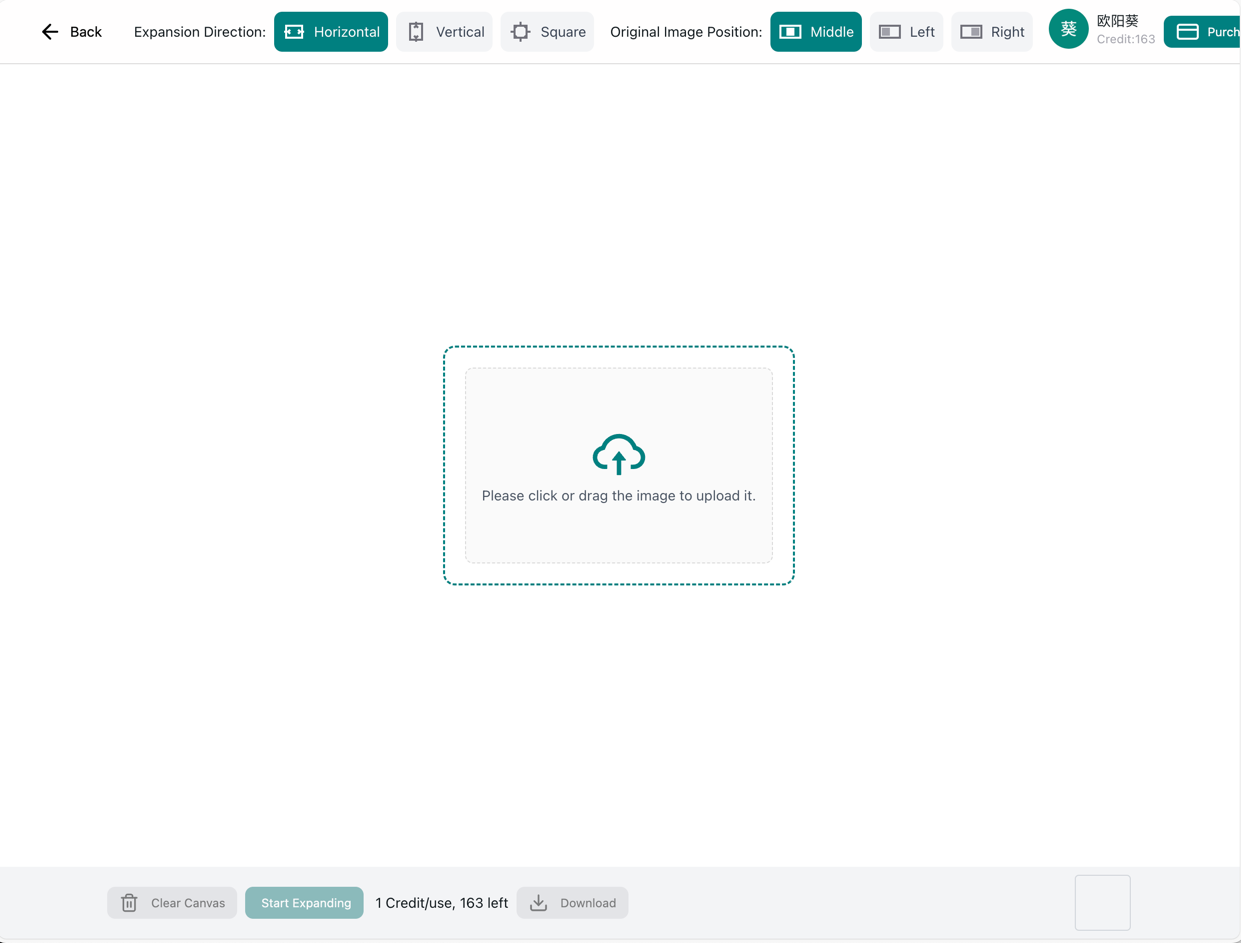
1. Site Web d'expansion d'image AI développé sur la base de nextjs 14 et tailwindcss3, adresse du site Web : https://www.ai-outpainting.com/
2. Le site Web doit être utilisé avec le modèle d’IA back-end. Le modèle back-end doit être construit par vous-même.
Adresse du modèle : https://huggingface.co/spaces/fffiloni/diffusers-image-outpaint
3. L'internationalisation est implémentée à l'aide de lingui. L'avantage par rapport à next-intl est qu'il n'est pas nécessaire de générer une clé pour chaque copie. Elle extraira la copie via des commandes pour générer des fichiers multilingues. Faites ensuite une traduction basée sur des fichiers multilingues
4. Le projet a écrit des scripts automatisés, tels que la traduction automatique du contenu international et la traduction automatique du contenu du blog. Ceux-ci doivent être exécutés manuellement si nécessaire
5. Le projet s'appuie sur la base de données, le stockage cloudfare r2, les paramètres requis pour la connexion Google et les paramètres de paiement Paypal. Ces paramètres sont configurés dans les fichiers .env et .env.production.
6. Utilisez next-auth pour intégrer la connexion Google. Si vous devez vous connecter avec Google lors du développement local, vous devez modifier certains codes sources, sinon une erreur sera signalée. Veuillez consulter la description ci-dessous pour des modifications spécifiques.
7. Paiement Paypal et Stripe intégré. L'environnement sandbox est utilisé pour le développement local. Pour l'environnement formel, les paramètres paypal formels doivent être configurés dans le fichier .env.production.
8. La façon dont le projet actuel appelle le modèle d'IA est à peu près la suivante :
Téléchargez les résultats du traitement sur le stockage cloudfare r2 et appelez l'adresse de rappel de mise à jour de l'état de la commande du site Web actuel.
Les résultats du traitement sont envoyés simultanément à la file d'attente MQ et sont transmis au serveur frontal par le service de gestion de files d'attente MQ. Une fois que le serveur frontal a reçu les résultats du traitement, ceux-ci sont affichés sur la page frontale.
Le frontal initie une demande de création d'une commande, porte le numéro de commande et l'adresse de rappel actuelle de la mise à jour de l'état de la commande du site Web, et appelle le service de gestion de files d'attente MQ (il s'agit d'un microservice développé en python, et je n'ai pas le temps de trier le code pour le moment)
Lancez une demande SSE vers le backend du service de gestion de files d'attente MQ, continuez d'attendre la fin du service de gestionnaire de files d'attente MQ et renvoyez le résultat.
Après avoir reçu la demande, le service de gestion de files d'attente MQ principal soumet directement les informations de commande à la file d'attente MQ.
Le serveur GPU écoute la file d'attente MQ et après avoir obtenu les informations de commande, il commence à appeler le modèle AI pour le traitement. Une fois le traitement terminé, il fera deux choses :
L'ensemble du processus n'implique pas de communication directe entre le site Web et le serveur GPU. Il est transmis via le service de gestion de files d'attente MQ et les fichiers sont transférés via le stockage R2. Cela résout le problème de couplage entre le serveur GPU et le site Web. le volume de commande est trop important, le GPU peut être ajouté à tout moment. Le serveur ne nécessite aucun ajustement du site Web.
9. Le schéma global de l'architecture est le suivant : 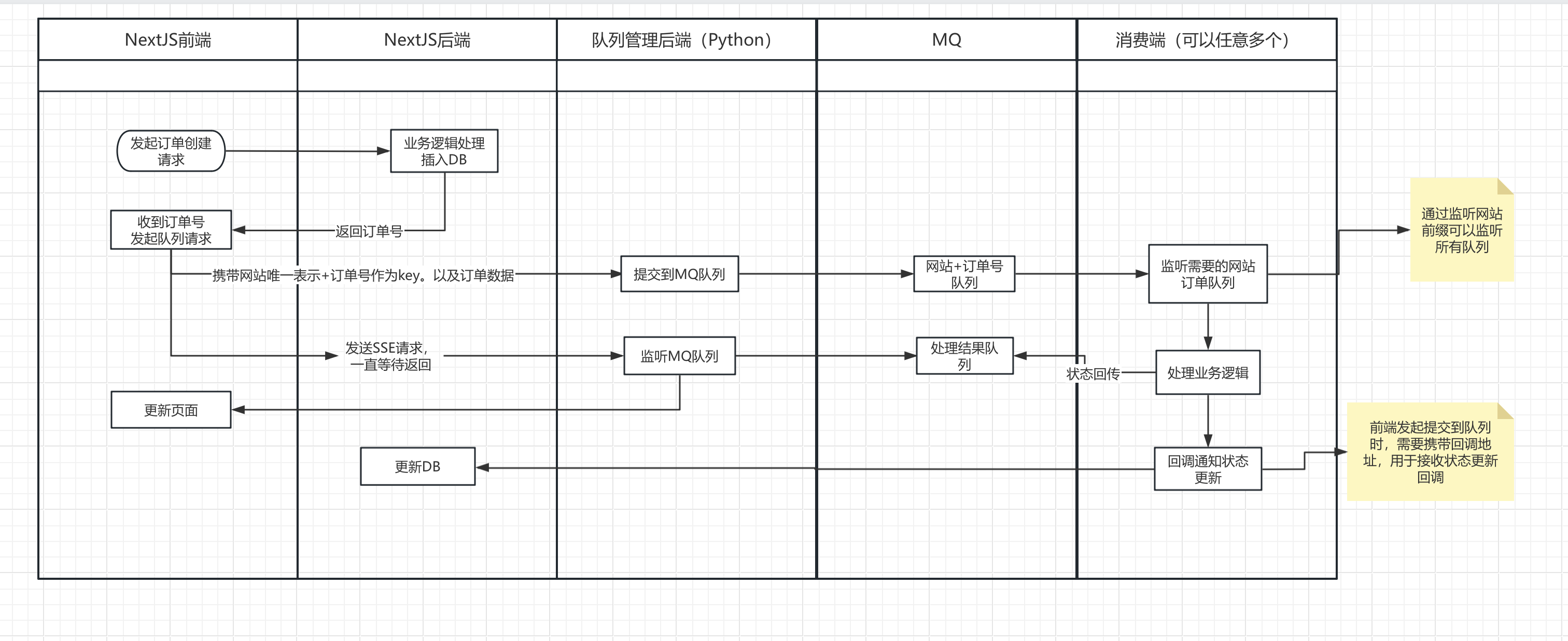
10.Une autre solution de mise en œuvre
Téléchargez les résultats du traitement sur le stockage cloudfare r2 et appelez l'adresse de rappel de mise à jour de l'état de la commande du site Web actuel pour mettre à jour l'état de la commande.
Une fois que le frontal a créé une commande, la page vérifie en permanence l'état de la commande via une interrogation jusqu'à ce que la commande soit terminée.
Il existe d'autres programmes sur le backend qui analysent régulièrement la base de données et obtiennent les commandes avec le statut de commande en attente. Après avoir obtenu les informations de commande, ils commencent à appeler le modèle IA pour le traitement. Une fois le traitement terminé, deux choses se produiront. fait:
11. Si vous disposez du budget, vous pouvez également envisager d'utiliser directement le service API de runpod. Vous n'avez pas besoin d'implémenter vous-même le serveur de gestion de files d'attente MQ, il vous suffit d'intégrer son SDK.
Code de référence
importer runpodSdk, { EndpointCompletedOutput, EndpointIncompleteOutput } à partir de la fonction async 'runpod-sdk' fetchProcessByRunPod(data: any): Promise<EndpointIncompleteOutput undefined> {
// const serverUrl = `${UE_PROCESS_API}/create_docker`
// https://docs.runpod.io/serverless/endpoints/job-operations
const runpod = runpodSdk("N5Jxxxxxxxxxxxxxxx");
const endpoint = runpod.endpoint("1zgk5xi3ew77pv");
console.log("démarrer l'appel du point de terminaison runpod,data:",data)
return endpoint?.run({"input": données,
})}Si vous devez utiliser pleinement la fonction d'expansion de l'image AI dans le code source du projet actuel, vous devez choisir une solution comme décrit ci-dessus et modifier la logique de création de commandes et de suivi de l'état des commandes dans l'application/[lang]/(éditeur )/editor/view.tsx ! ! !
Chaque fois que la page est modifiée pour contenir un nouveau contenu, vous devez exécuter la commande yarn extract pour extraire la nouvelle copie dans le fichier internationalisé, et exécuter la commande yarn translate pour traduire la copie dans la langue correspondante.
S'il y a de nouveaux articles de blog, vous devez exécuter la commande yarn translate pour traduire le nouveau contenu du blog dans la langue correspondante.
La traduction implique d'appeler l'API. Vous devez d'abord demander la clé API, puis modifier la clé API dans scripts/openai-chat.js.
Si vous devez ajouter ou réduire du contenu multilingue, vous devez modifier ces trois fichiers : framework/locale/locale.ts framework/locale/localeConfig.js framework/locale/messagesLoader.ts
Utilisez directement la commande node scripts/generator-website.js pour générer le contenu du site Web (cette commande générera une copie, un TDK et des titres de blog liés aux mots-clés spécifiés)
Vous devez d'abord modifier les mots-clés et la description, puis exécuter la commande
// Mot-clé du site Web const password = 'étendre l'image ai' // Le site Web doit être décrit const description = 'Utiliser la technologie d'IA pour agrandir l'image, tout en garantissant que l'image d'origine reste inchangée, étendre le contenu environnant et maintenir la continuité du contenu avec l'image d'origine
Modifier les informations de configuration dans config/site.ts
Placez votre propre logo favicon.ico dans le répertoire public/ et remplacez directement le fichier original
Modifier le nom de domaine dans public/sitemap.xml
Modifiez les informations de configuration dans .env et .env.production. Veuillez consulter les commentaires pour connaître les exigences de modification spécifiques.
Le projet actuel utilise prisma comme framework ORM. La structure de la table est déclarée dans le fichier schema.prisma. Pour l'utiliser pour la première fois, vous devez exécuter la commande suivante.
// Cette commande générera une table de base de données basée sur la déclaration de structure de table et initialisera les données de la table. S'il y a de nouvelles mises à jour de champs de table, vous devez exécuter la commande actuelle fil pg:migrate // Pour les autres commandes d'opération, il est recommandé de lire directement la documentation officielle de prisma.
Les informations de correspondance des couleurs du site Web sont stockées dans le fichier tailwind.config.ts. Si vous devez modifier la correspondance des couleurs, modifiez directement le contenu dans le fichier tailwind.config.ts.
Soumettez le code à github.com, puis utilisez vercel pour associer l'entrepôt de code pour le déploiement. Veuillez vous référer aux documents pertinents pour le processus spécifique.
【2024-10-19】 Résolvez le Error: ENOENT: no such file or directory xxx/.next/fallback-build-manifest.json en corrigeant "@lingui/swc-plugin": "4.0.8" , version résolue. Supprimez le répertoire node_modules local et réinstallez les dépendances pour résoudre le problème.
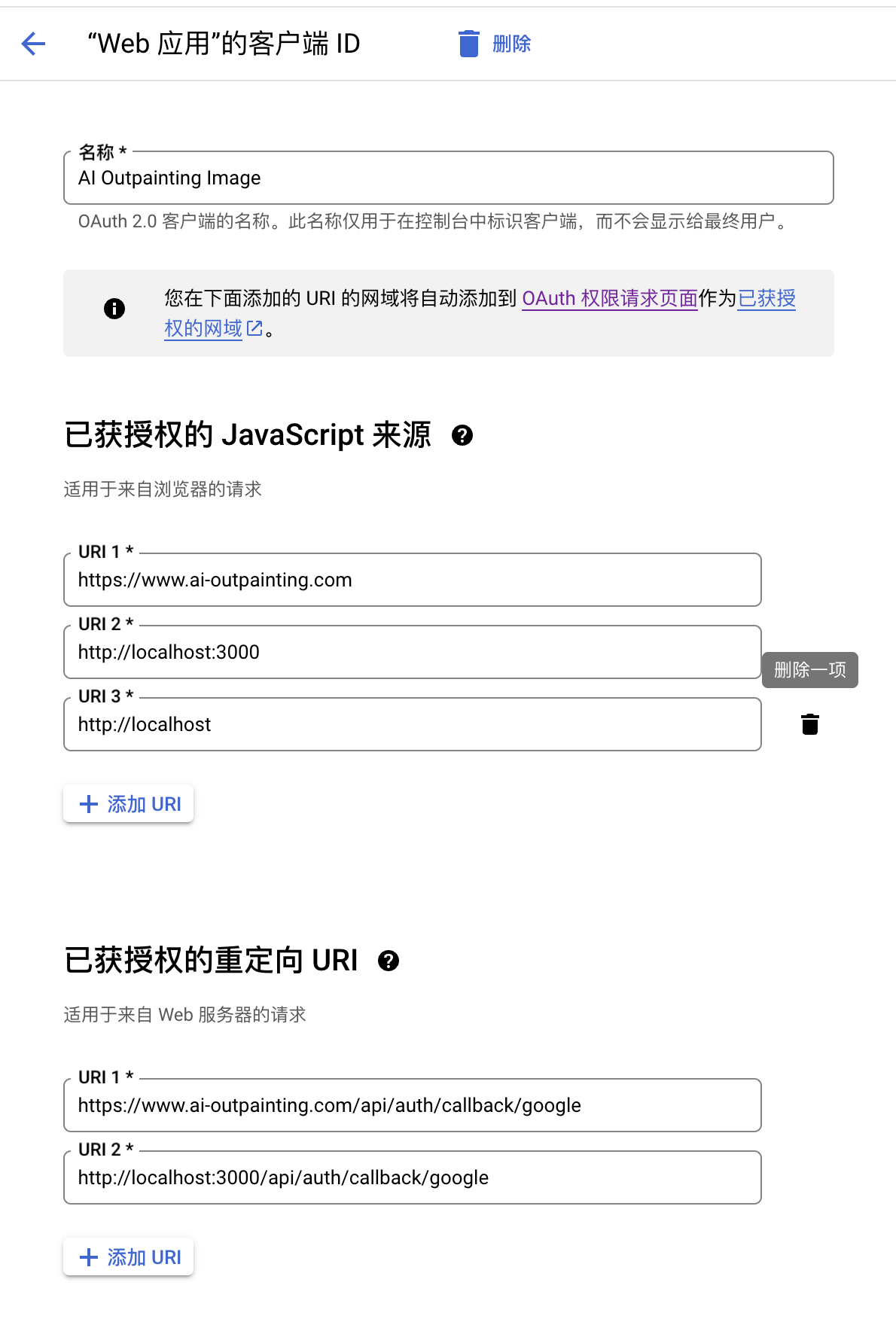
Ajouter une capture d'écran de référence de configuration de connexion Google
【20/10/2024] Résolvez le problème de Error: Cannot find module 'canvas' lors du démarrage en ajoutant le plugin webpack ignore. Optimisez la méthode de chargement des fichiers multilingues.
1. Site Web des composants de code Pure tailwindcss
Certains codes de composants prêts à l'emploi peuvent être copiés directement à partir du site Web et sont entièrement implémentés sur la base de deux
2. Framework d'interface utilisateur basé sur des composants-nextui.org
Fournit une utilisation directe basée sur des composants encapsulés
3.icon composant-react-icons
Fournit plusieurs ensembles d'icônes par défaut qui peuvent être utilisées directement
4.Génération de pages de tarification
Shipixen
5.Internationalisation
Générer dynamiquement des fichiers d'internationalisation
6.Blog MDX
Générer du contenu de blog basé sur MDX
7.Centre de configuration d'authentification Google
Configurer les paramètres requis pour la connexion Google
Dans l'environnement de développement de projet actuel, une adresse proxy personnalisée est utilisée pour résoudre le problème de l'impossibilité d'appeler google.com localement. Pour une configuration spécifique, voir le code config/auth-config.ts. L'environnement de production n'est pas affecté
https://www.prisma.io/docs/orm/more/help-and-troubleshooting/help-articles/vercel-caching-issue
Lorsque vous cliquez sur Google pour vous connecter, la page demande There is a problem with the server configuration. Le backend demande [auth][error] OperationProcessingError: "response" body "issuer" property does not match the expected value , modifiez-la comme suit.
Modifier le fichier node_modules/@auth/core/node_modules/oauth4webapi/build/index.js ou node_modules/oauth4webapi/dist/index.js
Après modification, vous devez supprimer manuellement le répertoire .next et recompiler.
Ligne 1034 ou 1003 ou 1237 (différentes versions peuvent être différentes), commentez l'exception levée. Certaines nouvelles versions ne se trouvent pas nécessairement sur cette ligne. Vous pouvez vous référer aux points suivants pour trouver le message d'erreur, puis le commenter.
function validateIssuer (attendu, résultat) {
if (result.claims.iss !== attendu) {// throw new OPE('valeur de revendication JWT "iss" (émetteur) inattendue');
}
renvoyer le résultat ;}Ligne 250 ou 238 (peut être différente selon les versions), commentez l'exception levée
if (nouvelle URL (json.issuer).href !== ExpectedIssuerIdentifier.href) {
// lance un nouvel OPE ('"le corps de la réponse" "émetteur" ne correspond pas à "expectedIssuer"');}Après modification, vous devez supprimer manuellement le répertoire .next et exécuter à nouveau run dev.
Modifiez le code de langue et les mots cibles pour ajuster la densité des mots dans scripts/add-word-locale.js
Exécutez la commande dans le répertoire cd scripts/ : bun run add-word-locale.js ou node add-word-locale.js
Ce projet adopte la licence open source MIT, veuillez respecter le contenu de l'accord
Si vous le souhaitez, veuillez laisser un lien vers mon site Web : https://www.ai-outpainting.com/ Merci beaucoup !
Si le projet vous est utile, merci de lui donner une étoile, merci beaucoup !
Si vous avez des questions techniques, veuillez ajouter WeChat pour communiquer : fafafa-ai
Petite publicité : Le site actuel d'ai-outpainting accepte la soumission payante de liens externes. Les amis dans le besoin peuvent me contacter.


