datablations
1.0.0
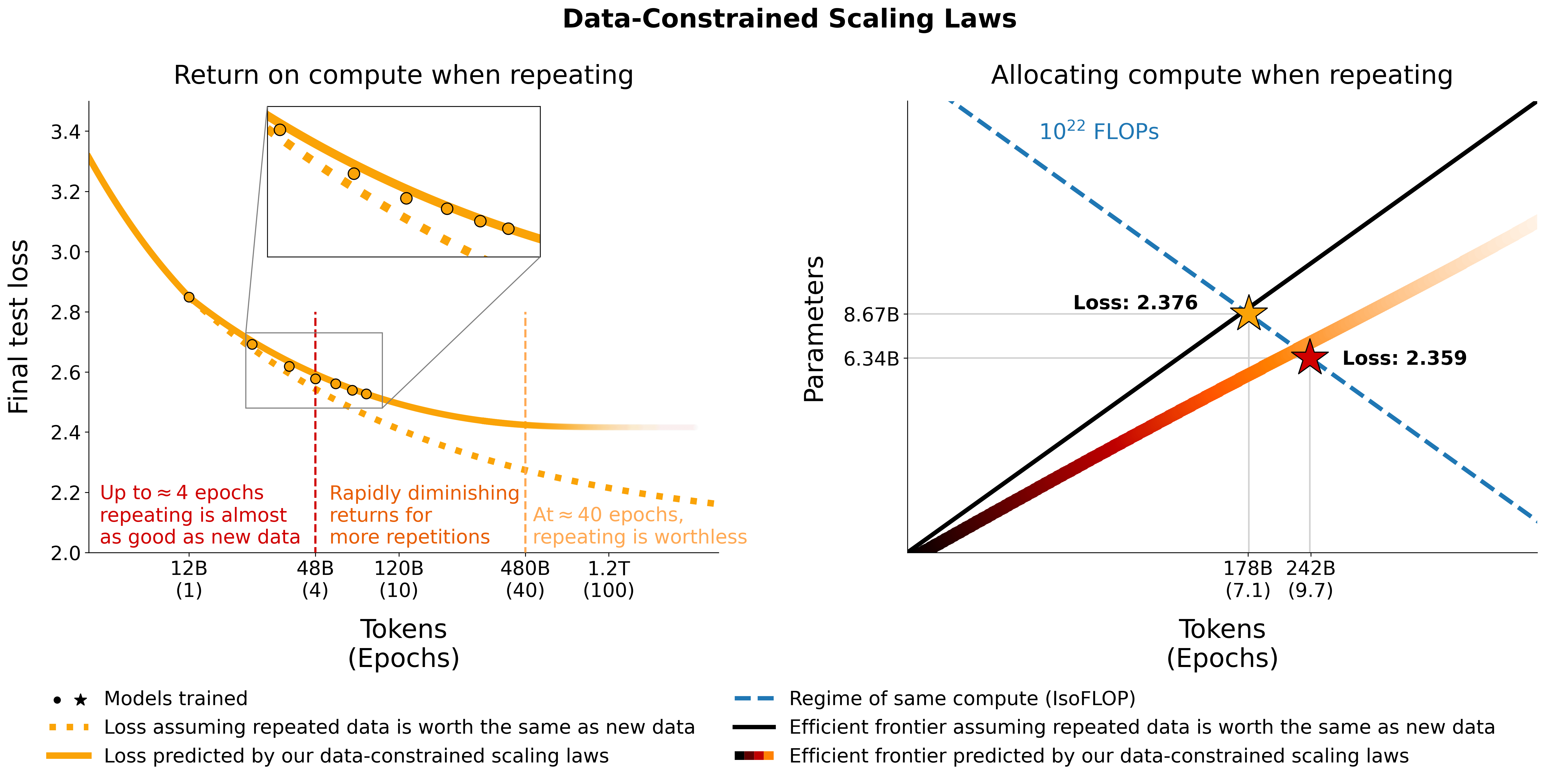
Ce référentiel fournit un aperçu de tous les composants du document Scaling Data-Constrained Language Models. Discussions sur papier :
Nous étudions la mise à l'échelle des modèles de langage dans des régimes contraints par les données. Nous menons un large éventail d'expériences faisant varier l'étendue de la répétition des données et le budget de calcul, allant jusqu'à 900 milliards de jetons de formation et 9 milliards de modèles de paramètres. Sur la base de nos exécutions, nous proposons et validons empiriquement une loi d'échelle pour l'optimalité du calcul qui prend en compte la valeur décroissante des jetons répétés et des paramètres excédentaires. Nous expérimentons également des approches atténuant la rareté des données, notamment l'augmentation de l'ensemble de données de formation avec des données de code, le filtrage de perplexité et la déduplication. Les modèles et ensembles de données de nos 400 sessions de formation sont disponibles via ce référentiel.
Nous expérimentons la répétition des données sur C4 et la division anglaise non dédupliquée d'OSCAR. Pour chaque ensemble de données, nous téléchargeons les données et les transformons en un seul fichier jsonl, respectivement c4.jsonl et oscar_en.jsonl .
Ensuite, nous décidons de la quantité de jetons uniques et du nombre respectif d'échantillons dont nous avons besoin dans l'ensemble de données. Notez que C4 a 478.625834583 jetons par échantillon et OSCAR en a 1312.0951072 avec le GPT2Tokenizer. Cela a été calculé en tokenisant l'ensemble de données et en divisant le nombre de jetons par le nombre d'échantillons. Nous utilisons ces chiffres pour calculer les échantillons nécessaires.
Par exemple, pour 1,9 B de jetons uniques, nous avons besoin 1.9B / 478.625834583 = 3969697.96178 échantillons pour C4 et 1.9B / 1312.0951072 = 1448065.76107 échantillons pour OSCAR. Pour tokeniser les données, nous devons d'abord cloner le référentiel Megatron-DeepSpeed et suivre son guide de configuration. Nous sélectionnons ensuite ces échantillons et les tokenisons comme suit :
C4 :
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64OSCAR:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64 où gpt2 pointe vers un dossier contenant tous les fichiers de https://huggingface.co/gpt2/tree/main. En utilisant head nous nous assurons que les différents sous-ensembles auront des échantillons qui se chevauchent pour réduire le caractère aléatoire.
Pour l'évaluation pendant la formation et l'évaluation finale, nous utilisons l'ensemble de validation pour C4 :
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2 Pour OSCAR qui n'a pas d'ensemble de validation officiel, nous prenons une partie de l'ensemble de formation en faisant tail -364608 oscar_en.jsonl > oscarvalidation.jsonl puis le tokenisons comme suit :
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2Nous avons téléchargé plusieurs sous-ensembles prétraités à utiliser avec Megatron :
Certains fichiers bin étaient trop volumineux pour git et donc divisés en utilisant par exemple split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin. et split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. . Pour les utiliser pour la formation, vous devez les regrouper à nouveau en utilisant cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin et cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin .
Nous expérimentons le mélange du code avec les données en langage naturel en utilisant la séparation Python de the-stack-dedup. Nous téléchargeons les données, les transformons en un seul fichier jsonl et les prétraitons en utilisant la même approche que celle décrite ci-dessus.
Nous avons téléchargé la version prétraitée pour une utilisation avec Megatron ici : https://huggingface.co/datasets/datablations/python-megatron. Nous avons divisé le fichier bin en utilisant split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. , vous devez donc les rassembler à nouveau en utilisant cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin pour la formation.
Nous créons des versions de C4 et OSCAR avec des métadonnées de filtrage liées à la perplexité et à la déduplication :
Pour recréer ces ensembles de données de métadonnées, il existe des instructions sur filtering/README.md .
Nous fournissons les versions tokenisées qui peuvent être utilisées pour la formation avec Megatron à l'adresse :
Les fichiers .bin ont été divisés en utilisant quelque chose comme split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. , vous devez donc les concaténer ensemble via cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin .
Pour recréer les versions tokenisées en fonction de l'ensemble de données de métadonnées,
filtering/deduplication/filter_oscar_jsonl.pyPour créer les centiles de perplexité, suivez les instructions ci-dessous.
C4 :
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )OSCAR:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )Vous pouvez ensuite tokeniser les fichiers jsonl résultants pour l'entraînement avec Megatron comme décrit dans la section Répétition.
C4 : Pour C4, il vous suffit de supprimer tous les échantillons dont le champ repetitions est renseigné, via par exemple
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR : pour OSCAR, nous fournissons un script sur filtering/filter_oscar_jsonl.py pour créer l'ensemble de données dédupliqué à partir de l'ensemble de données avec des métadonnées de filtrage.
Vous pouvez ensuite tokeniser les fichiers jsonl résultants pour l'entraînement avec Megatron comme décrit dans la section Répétition.
Tous les modèles peuvent être téléchargés sur https://huggingface.co/datablations.
Les modèles sont généralement nommés comme suit : lm1-{parameters}-{tokens}-{unique_tokens} , plus précisément les modèles individuels dans les dossiers sont nommés comme suit : {parameters}{tokens}{unique_tokens}{optional specifier} , par exemple 1b12b8100m serait 1,1 milliard de paramètres, 2,8 milliards de jetons, 100 millions de jetons uniques. La convention xby ( 1b1 , 2b8 etc.) introduit une certaine ambiguïté quant à savoir si les nombres appartiennent à des paramètres ou à des jetons, mais vous pouvez toujours vérifier le script sbatch dans le dossier correspondant pour voir les paramètres/jetons/jetons uniques exacts. Si vous souhaitez convertir des modèles qui n'ont pas encore été convertis en huggingface/transformers , vous pouvez suivre les instructions dans Formation.
La manière la plus simple de télécharger un seul modèle est par exemple :
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553 Si cela prend trop de temps, vous pouvez également utiliser wget pour télécharger directement des fichiers individuels depuis le dossier, par exemple :
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.ptPour les modèles correspondant aux expériences décrites dans l'article, consultez les référentiels suivants :
lm1-misc/*dedup* pour la comparaison de déduplication sur 100 millions de jetons uniques en annexeAutres modèles non analysés dans l’article :
Nous entraînons des modèles avec notre fork de Megatron-DeepSpeed qui fonctionne avec les GPU AMD (via ROCm) : https://github.com/TurkuNLP/Megatron-DeepSpeed Si vous souhaitez utiliser des GPU NVIDIA (via cuda), vous pouvez utiliser le bibliothèque originale : https://github.com/bigscience-workshop/Megatron-DeepSpeed
Vous devez suivre les instructions de configuration de l'un ou l'autre référentiel pour créer votre environnement (notre configuration spécifique à LUMI est détaillée dans training/megdssetup.md ).
Chaque dossier modèle contient un script sbatch qui a été utilisé pour entraîner le modèle. Vous pouvez les utiliser comme référence pour entraîner vos propres modèles en adaptant les variables d'environnement nécessaires. Les scripts sbatch font référence à des fichiers supplémentaires :
*txt qui spécifient les chemins de données. Vous pouvez les trouver sur utils/datapaths/* , cependant, vous devrez probablement adapter le chemin pour pointer vers votre ensemble de données.model_params.sh , qui se trouve sur utils/model_params.sh et contient des préréglages d'architecture.launch.sh que vous pouvez trouver sur training/launch.sh . Il contient des commandes spécifiques à notre configuration, que vous souhaiterez peut-être supprimer. Après la formation, vous pouvez convertir votre modèle en transformateurs avec par exemple python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1 .
Pour les modèles répétés, nous téléchargeons également leurs tensorboards après la formation en utilisant par exemple tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar" , ce qui les rend faciles à utiliser pour la visualisation dans le document.
Pour l'ablation muP dans l'annexe, nous utilisons le script à l' training_scripts/mup.py . Il contient des instructions de configuration.
Vous pouvez utiliser notre formule pour calculer la perte attendue en fonction des paramètres, des données et des jetons uniques comme suit :
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867Notez qu'il est peu probable que la valeur réelle de la perte soit utile, mais plutôt la tendance de la perte, par exemple lorsque le nombre de paramètres augmente ou pour comparer deux modèles comme dans l'exemple ci-dessus. Pour calculer l'allocation optimale, vous pouvez utiliser une simple recherche par grille :
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test Si vous dérivez une expression de forme fermée pour l'allocation optimale au lieu de la recherche de grille ci-dessus, veuillez nous le faire savoir :) Nous ajustons les lois de mise à l'échelle contraintes par les données et les coefficients de mise à l'échelle C4 en utilisant le code utils/parametric_fit.ipynb équivalent à ce colab .
Training > Regular models pour configurer un environnement de formation.pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git . Nous avons utilisé la version 0.2.0, mais les versions plus récentes devraient également fonctionner.sbatch utils/eval_rank.sh en modifiant d'abord les variables nécessaires dans le scriptpython Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.jsonaddtasks du harnais d'évaluation : git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13 c'est-à-dire toutes les exigences sauf promptsource, qui est installé à partir d'un fork avec les invites correctessbatch utils/eval_generative.sh en modifiant d'abord les variables nécessaires dans le scriptpython utils/merge_generative.py , puis les convertissons en csv avec python utils/csv_generative.py merged.jsonbabi du harnais d'évaluation : git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (Notez que cette branche n'est pas compatible avec la branche addtasks pour les tâches génératives car elle est issue de EleutherAI/lm-evaluation-harness , tandis que addtasks est basé sur bigscience/lm-evaluation-harness )cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh en modifiant d'abord les variables nécessaires dans le script plotstables/return_alloc.pdf , plotstables/return_alloc.ipynb , colabplotstables/dataset_setup.pdf , plotstables/dataset_setup.ipynb , colabplotstables/contours.pdf , plotstables/contours.ipynb , colabplotstables/isoflops_training.pdf , plotstables/isoflops_training.ipynb , colabplotstables/return.pdf , plotstables/return.ipynb , colabplotstables/strategies.pdf , plotstables/strategies.drawioplotstables/beyond.pdf , plotstables/beyond.ipynb , colabplotstables/cartoon.pdf , plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf et même collaboration que la figure 3plotstables/mup.pdf , plotstables/dd.pdf , plotstables/dedup.pdf , plotstables/mup_dd_dd.ipynb , colabplotstables/isoloss_alphabeta_100m.pdf et même collaboration que la figure 3plotstables/galactica.pdf , plotstables/galactica.ipynb , colabtraining_c4.pdf , validation_c4oscar.pdf , training_oscar.pdf , validation_epochs_c4oscar.pdf et même collaboration que la figure 4plotstables/perplexity_histogram.pdf , plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf , plotstables/training_validation_filter.pdf , plotstables/beyond_losses.ipynb & colabutils/parametric_fit.ipynb équivalent à ce colab.plotstables/repetition.ipynb & colabplotstables/python.ipynb & colabplotstables/filtering.ipynb & colabTous les modèles et codes sont sous licence Apache 2.0. Les ensembles de données filtrés sont publiés avec la même licence que les ensembles de données dont ils sont issus.
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

