CoPilot
v0.9.0
21/08/2024 : CoPilot est désormais disponible en v0.9 (v0.9.0). Veuillez consulter les notes de version pour plus de détails. Remarque : sur TigerGraph Cloud, seul CoPilot v0.5 est disponible.
30/04/2024 : CoPilot est désormais disponible en version bêta (v0.5.0). Une toute nouvelle fonction est ajoutée à CoPilot : vous pouvez désormais créer des chatbots avec une IA augmentée par graphiques sur vos propres documents. CoPilot crée un graphique de connaissances à partir du matériel source et applique le graphique de connaissances RAG (Retrieval Augmented Generation) pour améliorer la pertinence contextuelle et l'exactitude des réponses à leurs questions en langage naturel. Nous serions ravis d’entendre vos commentaires pour continuer à l’améliorer afin qu’il puisse vous apporter plus de valeur. Il serait utile que vous remplissiez ce court sondage après avoir joué avec CoPilot. Merci pour votre intérêt et votre soutien !
18/03/2024 : CoPilot est désormais disponible en version Alpha (v0.0.1). Il utilise un Large Language Model (LLM) pour convertir votre question en un appel de fonction, qui est ensuite exécuté sur le graphique dans TigerGraph. Nous serions ravis d’entendre vos commentaires pour continuer à l’améliorer afin qu’il puisse vous apporter plus de valeur. Si vous l'essayez, il serait utile que vous remplissiez ce formulaire d'inscription afin que nous puissions en assurer le suivi (pas de spam, promis). Et si vous souhaitez simplement nous faire part de vos commentaires, n'hésitez pas à répondre à ce court sondage. Merci pour votre intérêt et votre soutien !
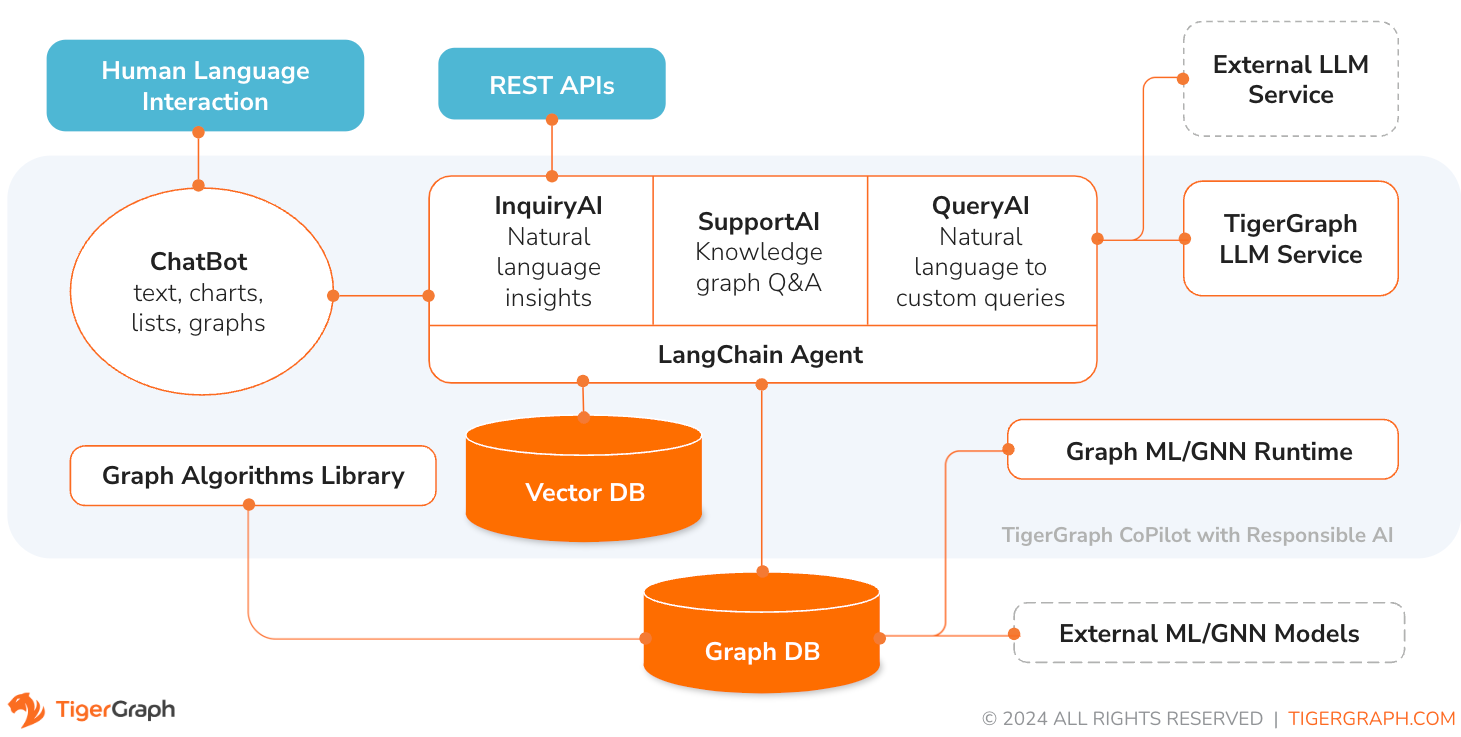
TigerGraph CoPilot est un assistant d'IA méticuleusement conçu pour combiner les puissances des bases de données graphiques et de l'IA générative afin de tirer le meilleur parti des données et d'améliorer la productivité dans diverses fonctions commerciales, notamment les tâches d'analyse, de développement et d'administration. Il s'agit d'un assistant IA avec trois services de composants principaux :
Vous pouvez interagir avec CoPilot via une interface de discussion sur TigerGraph Cloud, une interface de discussion intégrée et des API. Pour l'instant, vos propres services LLM (d'OpenAI, Azure, GCP, AWS Bedrock, Ollama, Hugging Face et Groq.) sont requis pour utiliser CoPilot, mais dans les versions futures, vous pourrez utiliser les LLM de TigerGraph.
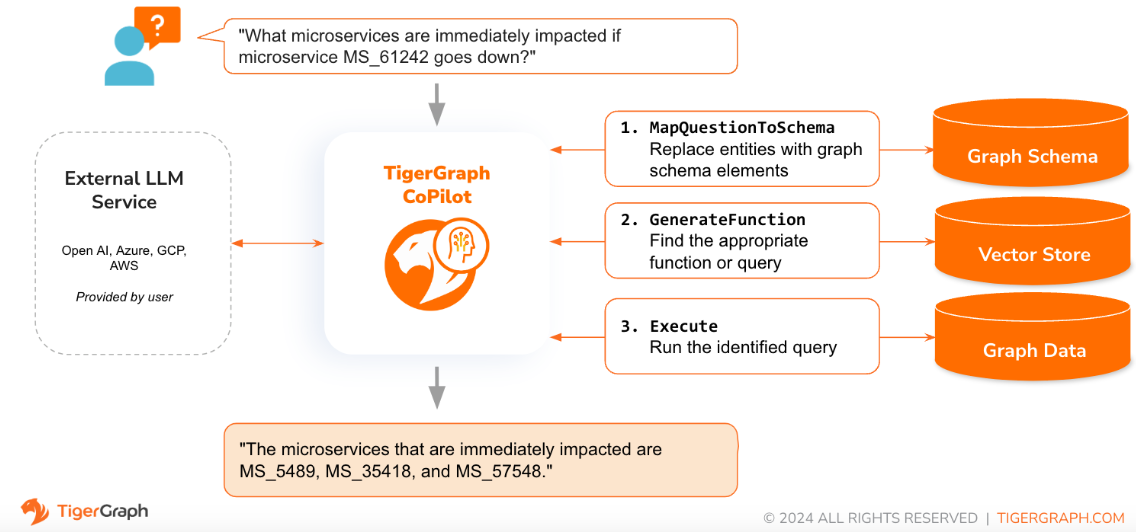
Lorsqu'une question est posée en langage naturel, CoPilot (InquiryAI) utilise une nouvelle interaction en trois phases avec à la fois la base de données TigerGraph et un LLM au choix de l'utilisateur, pour obtenir des réponses précises et pertinentes.
La première phase aligne la question sur les données particulières disponibles dans la base de données. CoPilot utilise le LLM pour comparer la question avec le schéma du graphique et remplacer les entités de la question par des éléments du graphique. Par exemple, s'il existe un type de sommet « BareMetalNode » et que l'utilisateur demande « Combien y a-t-il de serveurs ? », la question sera traduite par « Combien y a-t-il de sommets BareMetalNode ? Dans la deuxième phase, CoPilot utilise le LLM pour comparer la question transformée avec un ensemble de requêtes et de fonctions de base de données organisées afin de sélectionner la meilleure correspondance. Dans la troisième phase, CoPilot exécute la requête identifiée et renvoie le résultat en langage naturel ainsi que le raisonnement derrière les actions.
L'utilisation de requêtes pré-approuvées offre de nombreux avantages. Avant tout, cela réduit le risque d’hallucinations, car la signification et le comportement de chaque requête ont été validés. Deuxièmement, le système a le potentiel de prédire les ressources d’exécution nécessaires pour répondre à la question.
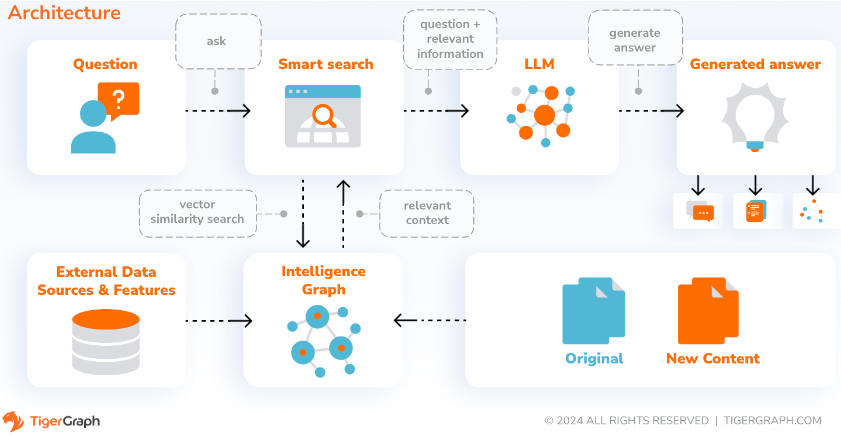
Avec SupportAI, CoPilot crée des chatbots avec une IA augmentée par graphiques sur les propres documents ou données texte d'un utilisateur. Il construit un graphe de connaissances à partir du matériel source et applique sa variante unique de RAG (Retrieval Augmented Generation) basé sur un graphe de connaissances pour améliorer la pertinence contextuelle et l'exactitude des réponses aux questions en langage naturel.
CoPilot identifiera également les concepts et construira une ontologie, pour ajouter de la sémantique et du raisonnement au graphe de connaissances, ou les utilisateurs pourront fournir leur propre ontologie de concepts. Ensuite, avec ce graphe de connaissances complet, CoPilot effectue des récupérations hybrides, combinant la recherche vectorielle traditionnelle et les parcours de graphiques, pour collecter des informations plus pertinentes et un contexte plus riche pour répondre aux questions de connaissances des utilisateurs.
L'organisation des données sous forme de graphique de connaissances permet à un chatbot d'accéder rapidement et efficacement à des informations précises et factuelles, réduisant ainsi le recours à la génération de réponses à partir de modèles appris au cours de la formation, qui peuvent parfois être incorrects ou obsolètes.
QueryAI est le troisième composant de TigerGraph CoPilot. Il est conçu pour être utilisé comme outil de développement permettant de générer des requêtes graphiques dans GSQL à partir d'une description en anglais. Il peut également être utilisé pour générer des schémas, des mappages de données et même des tableaux de bord. Cela permettra aux développeurs d’écrire des requêtes GSQL plus rapidement et avec plus de précision, et sera particulièrement utile pour ceux qui découvrent GSQL. Actuellement, une génération expérimentale d’openCypher est disponible.
CoPilot est disponible en tant que service complémentaire à votre espace de travail sur TigerGraph Cloud. Il est désactivé par défaut. Veuillez contacter [email protected] pour activer TigerGraph CoPilot en option sur le marché.
TigerGraph CoPilot est un projet open source sur GitHub qui peut être déployé sur votre propre infrastructure.
Si vous n'avez pas besoin d'étendre le code source de CoPilot, le moyen le plus rapide consiste à déployer son image Docker avec le fichier Docker Compose dans le référentiel. Pour emprunter cette voie, vous aurez besoin des prérequis suivants.
Étape 1 : Obtenir le fichier docker-compose
git clone https://github.com/tigergraph/CoPilot Le fichier Docker Compose contient toutes les dépendances de CoPilot, y compris une base de données Milvus. Si vous n'avez pas besoin d'un service particulier, vous faites modifier le fichier Compose pour le supprimer ou définissez son échelle à 0 lors de l'exécution du fichier Compose (détails plus tard). De plus, CoPilot est livré avec une page de documentation de l'API Swagger lors de son déploiement. Si vous souhaitez le désactiver, vous pouvez définir la variable d'environnement PRODUCTION sur true pour le service CoPilot dans le fichier Compose.
Étape 2 : Configurer les configurations
Ensuite, dans le même répertoire que celui où se trouve le fichier Docker Compose, créez et remplissez les fichiers de configuration suivants :
Étape 3 (Facultatif) : Configurer la journalisation
touch configs/log_config.json . Les détails de la configuration sont disponibles ici.
Étape 4 : Démarrez tous les services
Maintenant, exécutez simplement docker compose up -d et attendez que tous les services démarrent. Si vous ne souhaitez pas utiliser la base de données Milvus incluse, vous pouvez définir son échelle sur 0 pour ne pas la démarrer : docker compose up -d --scale milvus-standalone=0 --scale etcd=0 --scale minio=0 .
Étape 5 : Installer les UDF
Cette étape n'est pas nécessaire pour les bases de données TigerGraph version 4.x. Pour TigerGraph 3.x, nous devons installer quelques fonctions définies par l'utilisateur (UDF) pour que CoPilot fonctionne.
sudo su - tigergraph . Si TigerGraph s'exécute sur un cluster, vous pouvez le faire sur n'importe laquelle des machines. gadmin config set GSQL.UDF.EnablePutTgExpr true
gadmin config set GSQL.UDF.Policy.Enable false
gadmin config apply
gadmin restart GSQL
PUT tg_ExprFunctions FROM "./tg_ExprFunctions.hpp"
PUT tg_ExprUtil FROM "./tg_ExprUtil.hpp"
gadmin config set GSQL.UDF.EnablePutTgExpr false
gadmin config set GSQL.UDF.Policy.Enable true
gadmin config apply
gadmin restart GSQL
Dans le fichier configs/llm_config.json , copiez le modèle de configuration JSON ci-dessous pour votre fournisseur LLM et remplissez les champs appropriés. Un seul fournisseur est nécessaire.
OpenAI
En plus de OPENAI_API_KEY , llm_model et model_name peuvent être modifiés pour correspondre à vos détails de configuration spécifiques.
{
"model_name" : " GPT-4 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " YOUR_OPENAI_API_KEY_HERE "
}
},
"completion_service" : {
"llm_service" : " openai " ,
"llm_model" : " gpt-4-0613 " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " YOUR_OPENAI_API_KEY_HERE "
},
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}GCP
Suivez les informations d'authentification GCP trouvées ici : https://cloud.google.com/docs/authentication/application-default-credentials#GAC et créez un compte de service avec les informations d'identification VertexAI. Ajoutez ensuite ce qui suit à la commande docker run :
-v $( pwd ) /configs/SERVICE_ACCOUNT_CREDS.json:/SERVICE_ACCOUNT_CREDS.json -e GOOGLE_APPLICATION_CREDENTIALS=/SERVICE_ACCOUNT_CREDS.jsonEt votre configuration JSON devrait suivre comme suit :
{
"model_name" : " GCP-text-bison " ,
"embedding_service" : {
"embedding_model_service" : " vertexai " ,
"authentication_configuration" : {}
},
"completion_service" : {
"llm_service" : " vertexai " ,
"llm_model" : " text-bison " ,
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/gcp_vertexai_palm/ "
}
}Azuré
En plus de AZURE_OPENAI_ENDPOINT , AZURE_OPENAI_API_KEY et azure_deployment , llm_model et model_name peuvent être modifiés pour correspondre à vos détails de configuration spécifiques.
{
"model_name" : " GPT35Turbo " ,
"embedding_service" : {
"embedding_model_service" : " azure " ,
"azure_deployment" : " YOUR_EMBEDDING_DEPLOYMENT_HERE " ,
"authentication_configuration" : {
"OPENAI_API_TYPE" : " azure " ,
"OPENAI_API_VERSION" : " 2022-12-01 " ,
"AZURE_OPENAI_ENDPOINT" : " YOUR_AZURE_ENDPOINT_HERE " ,
"AZURE_OPENAI_API_KEY" : " YOUR_AZURE_API_KEY_HERE "
}
},
"completion_service" : {
"llm_service" : " azure " ,
"azure_deployment" : " YOUR_COMPLETION_DEPLOYMENT_HERE " ,
"openai_api_version" : " 2023-07-01-preview " ,
"llm_model" : " gpt-35-turbo-instruct " ,
"authentication_configuration" : {
"OPENAI_API_TYPE" : " azure " ,
"AZURE_OPENAI_ENDPOINT" : " YOUR_AZURE_ENDPOINT_HERE " ,
"AZURE_OPENAI_API_KEY" : " YOUR_AZURE_API_KEY_HERE "
},
"model_kwargs" : {
"temperature" : 0
},
"prompt_path" : " ./app/prompts/azure_open_ai_gpt35_turbo_instruct/ "
}
}Socle AWS
{
"model_name" : " Claude-3-haiku " ,
"embedding_service" : {
"embedding_model_service" : " bedrock " ,
"embedding_model" : " amazon.titan-embed-text-v1 " ,
"authentication_configuration" : {
"AWS_ACCESS_KEY_ID" : " ACCESS_KEY " ,
"AWS_SECRET_ACCESS_KEY" : " SECRET "
}
},
"completion_service" : {
"llm_service" : " bedrock " ,
"llm_model" : " anthropic.claude-3-haiku-20240307-v1:0 " ,
"authentication_configuration" : {
"AWS_ACCESS_KEY_ID" : " ACCESS_KEY " ,
"AWS_SECRET_ACCESS_KEY" : " SECRET "
},
"model_kwargs" : {
"temperature" : 0 ,
},
"prompt_path" : " ./app/prompts/aws_bedrock_claude3haiku/ "
}
}Ollama
{
"model_name" : " GPT-4 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " ollama " ,
"llm_model" : " calebfahlgren/natural-functions " ,
"model_kwargs" : {
"temperature" : 0.0000001
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}Visage câlin
Un exemple de configuration pour un modèle sur Hugging Face avec un point de terminaison dédié est présenté ci-dessous. Veuillez préciser vos détails de configuration :
{
"model_name" : " llama3-8b " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " huggingface " ,
"llm_model" : " hermes-2-pro-llama-3-8b-lpt " ,
"endpoint_url" : " https:endpoints.huggingface.cloud " ,
"authentication_configuration" : {
"HUGGINGFACEHUB_API_TOKEN" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
}Un exemple de configuration pour un modèle sur Hugging Face avec un point de terminaison sans serveur est présenté ci-dessous. Veuillez préciser vos détails de configuration :
{
"model_name" : " Llama3-70b " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " huggingface " ,
"llm_model" : " meta-llama/Meta-Llama-3-70B-Instruct " ,
"authentication_configuration" : {
"HUGGINGFACEHUB_API_TOKEN" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/llama_70b/ "
}
}Groq
{
"model_name" : " mixtral-8x7b-32768 " ,
"embedding_service" : {
"embedding_model_service" : " openai " ,
"authentication_configuration" : {
"OPENAI_API_KEY" : " "
}
},
"completion_service" : {
"llm_service" : " groq " ,
"llm_model" : " mixtral-8x7b-32768 " ,
"authentication_configuration" : {
"GROQ_API_KEY" : " "
},
"model_kwargs" : {
"temperature" : 0.1
},
"prompt_path" : " ./app/prompts/openai_gpt4/ "
}
} Copiez ce qui suit dans configs/db_config.json et modifiez les champs hostname et getToken pour qu'ils correspondent à la configuration de votre base de données. Si l'authentification par jeton est activée dans TigerGraph, définissez getToken sur true . Définissez les paramètres de délai d'attente, de seuil de mémoire et de limite de thread comme vous le souhaitez pour contrôler la quantité de ressources de la base de données consommée lors de la réponse à une question.
« ecc » et « chat_history_api » sont les adresses des composants internes de CoPilot. Si vous utilisez le fichier Docker Compose tel quel, vous n'avez pas besoin de les modifier.
{
"hostname" : " http://tigergraph " ,
"restppPort" : " 9000 " ,
"gsPort" : " 14240 " ,
"getToken" : false ,
"default_timeout" : 300 ,
"default_mem_threshold" : 5000 ,
"default_thread_limit" : 8 ,
"ecc" : " http://eventual-consistency-service:8001 " ,
"chat_history_api" : " http://chat-history:8002 "
} Copiez ce qui suit dans configs/milvus_config.json et modifiez les champs host et port pour qu'ils correspondent à votre configuration Milvus (en gardant à l'esprit la configuration du docker). username et password peuvent également être configurés ci-dessous si votre configuration Milvus l'exige. enabled doit toujours être défini sur "true" pour l'instant car Milvus n'est que le magasin d'intégration pris en charge.
{
"host" : " milvus-standalone " ,
"port" : 19530 ,
"username" : " " ,
"password" : " " ,
"enabled" : " true " ,
"sync_interval_seconds" : 60
} Copiez le code ci-dessous dans configs/chat_config.json . Vous ne devriez pas avoir besoin de modifier quoi que ce soit, sauf si vous modifiez le port du service d'historique des discussions dans le fichier Docker Compose.
{
"apiPort" : " 8002 " ,
"dbPath" : " chats.db " ,
"dbLogPath" : " db.log " ,
"logPath" : " requestLogs.jsonl " ,
"conversationAccessRoles": ["superuser", "globaldesigner"]
} Si vous souhaitez activer la génération de requêtes openCypher dans InquiryAI, vous pouvez définir la variable d'environnement USE_CYPHER sur "true" dans le service CoPilot dans le fichier de composition Docker. Par défaut, la valeur est "false" . Remarque : la génération de requêtes openCypher est toujours en version bêta et peut ne pas fonctionner comme prévu, et augmente également le potentiel de réponses hallucinées en raison d'une mauvaise génération de code. À utiliser avec prudence et uniquement dans des environnements hors production.
CoPilot est convivial pour les utilisateurs techniques et non techniques. Il existe une interface de discussion graphique ainsi qu'un accès API à CoPilot. Sur le plan fonctionnel, CoPilot peut répondre à vos questions en appelant des requêtes existantes dans la base de données (InquiryAI), créer un graphique de connaissances à partir de vos documents (SupportAI) et répondre à des questions de connaissances basées sur vos documents (SupportAI).
Veuillez vous référer à notre documentation officielle pour savoir comment utiliser CoPilot.
TigerGraph CoPilot est conçu pour être facilement extensible. Le service peut être configuré pour utiliser différents fournisseurs LLM, différents schémas graphiques et différents outils LangChain. Le service peut également être étendu pour utiliser différents services d'intégration, différents services de génération LLM et différents outils LangChain. Pour plus d'informations sur la façon d'étendre le service, consultez le Guide du développeur.
Une famille de tests est incluse dans le répertoire tests . Si vous souhaitez ajouter plus de tests, veuillez vous référer au guide ici. Un script shell run_tests.sh est également inclus dans le dossier qui est le pilote pour exécuter les tests. Le moyen le plus simple d'utiliser ce script consiste à l'exécuter dans le conteneur Docker à des fins de test.
Vous pouvez exécuter des tests pour chaque service en accédant au niveau supérieur du répertoire du service et en exécutant python -m pytest
par exemple (du niveau supérieur)
cd copilot
python -m pytest
cd ..Tout d’abord, assurez-vous que tous les fichiers de configuration de votre fournisseur de services LLM fonctionnent correctement. Les configurations seront montées pour que le conteneur puisse y accéder. Assurez-vous également que toutes les dépendances telles que la base de données et Milvus sont prêtes. Sinon, vous pouvez exécuter le fichier Docker Compose inclus pour créer ces services.
docker compose up -d --buildSi vous souhaitez utiliser les poids et les biais pour enregistrer les résultats des tests, votre clé API WandB doit être définie dans une variable d'environnement sur la machine hôte.
export WANDB_API_KEY=KEY HERE Ensuite, vous pouvez créer le conteneur Docker à partir du fichier Dockerfile.tests et exécuter le script de test dans le conteneur.
docker build -f Dockerfile.tests -t copilot-tests:0.1 .
docker run -d -v $( pwd ) /configs/:/ -e GOOGLE_APPLICATION_CREDENTIALS=/GOOGLE_SERVICE_ACCOUNT_CREDS.json -e WANDB_API_KEY= $WANDB_API_KEY -it --name copilot-tests copilot-tests:0.1
docker exec copilot-tests bash -c " conda run --no-capture-output -n py39 ./run_tests.sh all all " Pour modifier les tests exécutés, on peut passer des arguments au script ./run_tests.sh . Actuellement, on peut configurer le service LLM à utiliser (par défaut pour tous), les schémas sur lesquels tester (par défaut pour tous) et s'il faut ou non utiliser les poids et les biais pour la journalisation (par défaut sur true). Les instructions des options se trouvent ci-dessous :
Le premier paramètre de run_tests.sh correspond aux LLM sur lesquels tester. La valeur par défaut est all . Les options sont :
all - exécuter des tests sur tous les LLMazure_gpt35 - exécute des tests sur GPT-3.5 hébergé sur Azureopenai_gpt35 - exécuter des tests sur GPT-3.5 hébergé sur OpenAIopenai_gpt4 - exécuter des tests sur GPT-4 hébergé sur OpenAIgcp_textbison - exécuter des tests sur text-bison hébergé sur GCP Le deuxième paramètre de run_tests.sh correspond aux graphiques sur lesquels tester. La valeur par défaut est all . Les options sont :
all - exécute des tests sur tous les graphiques disponiblesOGB_MAG - L'ensemble de données d'articles universitaires fourni par : https://ogb.stanford.edu/docs/nodeprop/#ogbn-mag.DigtialInfra - Ensemble de données sur les jumeaux numériques d'infrastructure numériqueSynthea - Ensemble de données synthétiques sur la santé Si vous souhaitez enregistrer les résultats des tests dans Weights and Biases (et disposer des informations d'identification correctes ci-dessus), le paramètre final de run_tests.sh est automatiquement défini par défaut sur true. Si vous souhaitez désactiver la journalisation des poids et des biais, utilisez false .
Si vous souhaitez contribuer à TigerGraph CoPilot, veuillez lire la documentation ici.


