alfresco ai framework
1.0.0
Alfresco AI Framework est un framework robuste conçu pour intégrer les capacités d'IA dans Alfresco, en tirant parti de Java et Spring AI. Il fournit une suite d'outils et de services pour traiter, analyser et améliorer le contenu des documents dans Alfresco à l'aide de modèles d'IA et d'apprentissage automatique.
Remarque : Ce projet utilise la version Spring AI SNAPSHOT, car une VERSION finale n'est pas encore disponible.
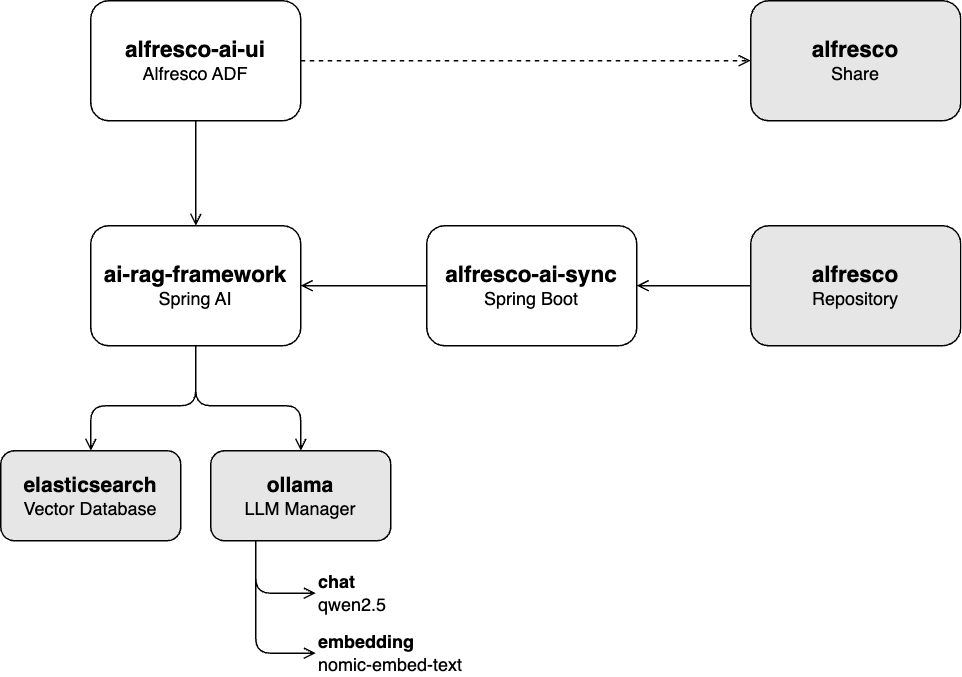
ai-rag-framework :
Une API REST construite sur Spring AI pour ingérer des documents dans un modèle d'IA générative (GenAI) et fournir un service de discussion de génération augmentée de récupération (RAG).
alfresco-ai-sync :
Un service construit sur le SDK Alfresco Java qui récupère les documents du référentiel Alfresco et les ingère dans la base de données vectorielles via l'API ai-rag-framework .
ai-rag-framework en plein air-ai-ui :
Une interface utilisateur construite sur Alfresco ADF pour interagir avec le service de discussion RAG fourni par ai-rag-framework .
ai-rag-framework doit être en cours d'exécutionalfresco-docker : Déploiement Alfresco Community 23.3 orienté conteneur
Cette série de didacticiels vous guidera à travers les fonctionnalités clés du projet, notamment l'ingestion de données, l'intégration du chat et le fonctionnement global du système.
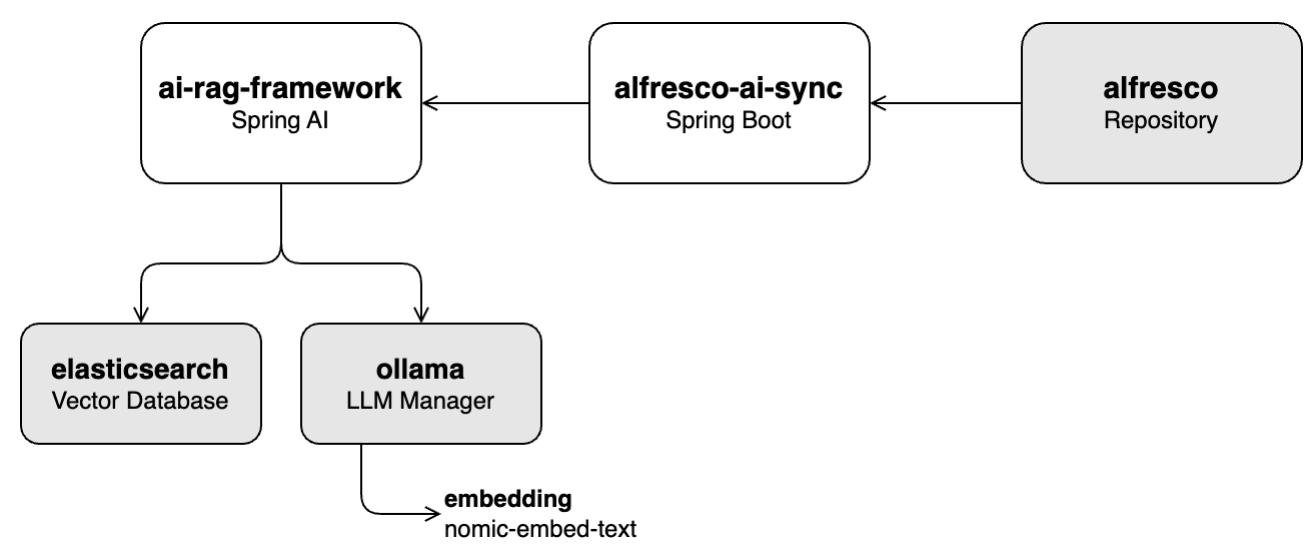
Dans cet atelier, vous apprendrez à remplir la base de données vectorielles (Elasticsearch) avec le contenu sélectionné de la base de connaissances stockée dans Alfresco. Cela implique d'extraire des vecteurs du contenu à l'aide du module Embedding nomic-embed-text via Ollama.
Commencez l’atelier en suivant l’atelier 1 : Pipeline d’ingestion.
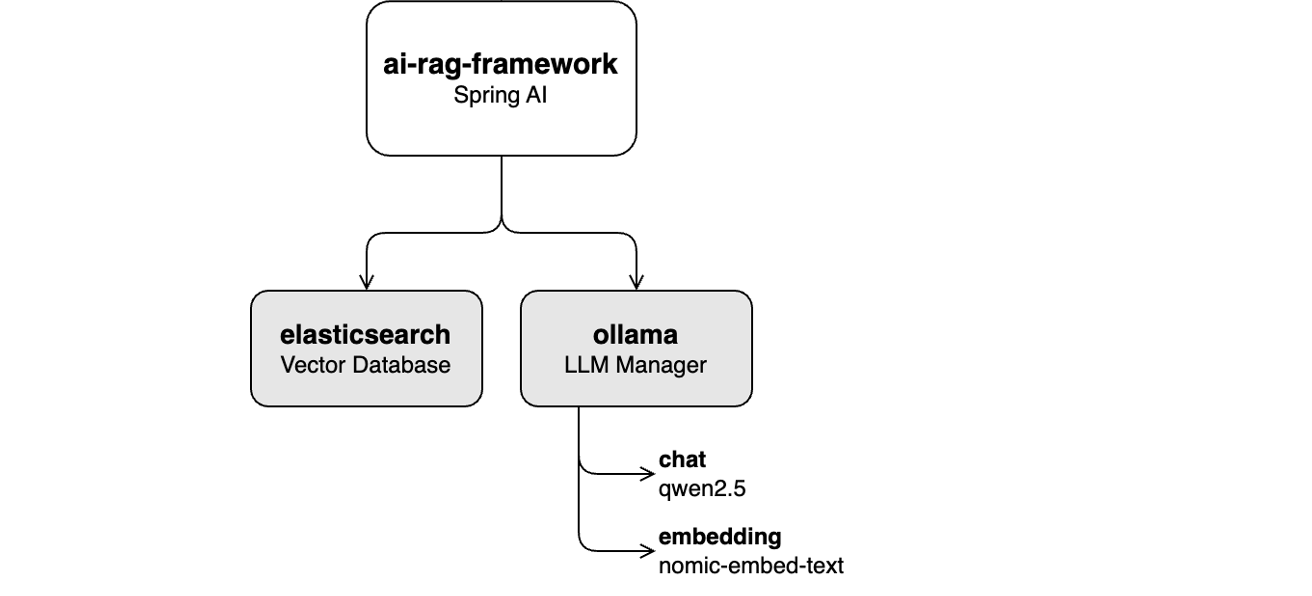
Ce laboratoire se concentre sur l'activation de la fonctionnalité de chat avec le LLM qwen2.5 via Ollama, à l'aide d'applications d'interface utilisateur Alfresco telles que Share et ADF. Le processus consiste à transformer l'invite de l'utilisateur en vecteurs à l'aide du module d'intégration nomic-embed-text via Ollama, puis à rechercher le contenu pertinent dans la base de données vectorielles (Elasticsearch). Le texte récupéré est utilisé pour fournir un contexte au LLM , ce qui permet de générer des réponses plus précises.
Démarrez cet atelier en suivant l'atelier 2 : Fonctionnalité de chat.
Dans cet atelier, vous intégrerez tous les composants (fonctionnalités d'ingestion et de chat) avec un référentiel Alfresco en direct. Le système mettra automatiquement à jour la base de données vectorielles chaque fois qu'il y aura des modifications dans le référentiel, éliminant ainsi le besoin d'une intervention manuelle.
Vous pouvez commencer cet atelier en suivant l'atelier 3 : Exécuter tous les composants ensemble.
Ce projet est sous licence Apache License 2.0. Voir le fichier LICENSE pour plus de détails.
Un merci spécial aux équipes Alfresco et Hyland pour leur soutien continu et leurs contributions aux initiatives open source dans les domaines de la gestion de contenu et de l'IA.


