build your local ragstack chatbot
1.0.0
Bienvenue dans cet atelier pour créer et déployer votre propre copilote d'entreprise à l'aide de la génération augmentée par récupération avec DataStax Enterprise v7, un inférenceur local et Mistral, un modèle grand langage local et ouvert.
Ce référentiel se concentre sur la sûreté et la sécurité en gardant vos données sensibles dans le pare-feu !
Pourquoi?
Il exploite DataStax RAGStack, qui est une pile organisée des meilleurs logiciels open source pour faciliter la mise en œuvre du modèle RAG dans les applications prêtes pour la production qui utilisent DataStax Enterprise, Astra Vector DB ou Apache Cassandra comme magasin de vecteurs.
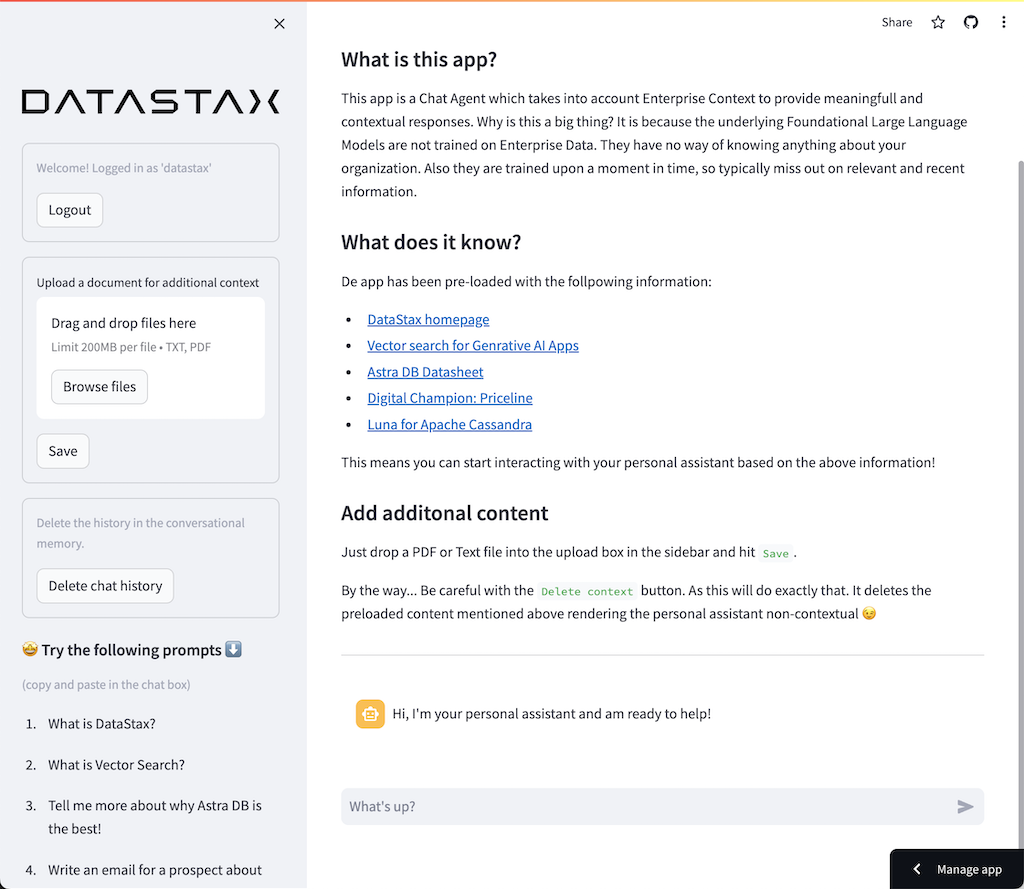
Ce que vous apprendrez :
? Comment tirer parti de DataStax RAGStack pour une utilisation prête pour la production des composants suivants :
? Comment utiliser Ollama comme moteur d'inférence local
? Comment utiliser Mistral comme grand modèle linguistique (LLM) local et ouvert pour les chatbots de style questions-réponses
? Comment utiliser Streamlit pour déployer facilement votre superbe application !
Les slides de la présentation sont disponibles ICI
Cet atelier suppose que vous avez accès à :
Dans les prochaines étapes, nous préparerons le référentiel, DataStax Enterprise, un bloc-notes Jupyter et le moteur d'inférence Ollama avec Ollama.
Tout d'abord, nous devrons cloner ce référentiel sur votre ordinateur portable de développement local.
Ouvrez le référentiel build-your-local-ragstack-chatbot
Cliquez sur Use this template -> Ceate new repository comme suit :
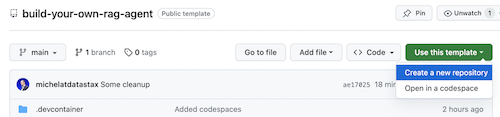
Sélectionnez maintenant votre compte github et nommez le nouveau référentiel. Idéalement, définissez également la description. Cliquez sur Create repository
Cool! Vous venez de créer une copie dans votre propre compte Gihub !
cd dans un répertoire sensible (comme /projects ou autre) ;git clone <url-to-your-repo>cd dans votre nouveau répertoire !Et vous êtes prêt à faire du rock and roll ! ?
Il est utile de créer un environnement virtuel . Utilisez ce qui suit pour le configurer :
python3 -m venv myenv
Activez-le ensuite comme suit :
source myenv/bin/activate # on Linux/Mac
myenvScriptsactivate.bat # on Windows
Vous pouvez maintenant commencer à installer les packages requis :
pip3 install -r requirements.txt
Exécutez DSE 7 de l’une de ces deux manières à partir d’une nouvelle fenêtre de terminal :
docker-compose up
Cela utilise le fichier docker-compose.yml à la racine de ce référentiel qui démarrera également facilement l'interpréteur Jupyter.
DataStax fonctionnera sur http://localhost:9042 et Jupyter sera accessible en accédant à http://localhost:8888
Il existe une multitude de moteurs d'inférence. Vous pouvez opter pour LM Studio qui possède une interface utilisateur agréable. Dans ce cahier, nous utiliserons Ollama.
ollama run mistral dans une nouvelle fenêtre de terminalEn cas d'échec, en raison des limitations de la RAM, vous pouvez choisir d'utiliser tinyllama comme modèle.
Pour lancer cet atelier, nous allons d’abord essayer les concepts du cahier fourni. Nous supposons que vous exécuterez à partir d'un conteneur Jupyter Docker. Si ce n'est pas le cas, veuillez modifier les noms d'hôte de host.docker.internal à localhost .
Ce cahier montre les étapes à suivre pour utiliser le DataStax Enterprise Vector Store comme moyen de rendre les interactions LLM significatives et sans hallucinations. L’approche adoptée ici est la génération augmentée par récupération.
Vous apprendrez :
Accédez à http://localhost:8888 et ouvrez le bloc-notes disponible à la racine appelé Build_Your_Own_RAG_Meetup.ipnb .
Dans cet atelier, nous utiliserons Streamlit, un framework incroyablement simple à utiliser pour créer des applications Web frontales.
Pour commencer, créons une application hello world comme suit :
import streamlit as st
# Draw a title and some markdown
st . markdown ( """# Your Enterprise Co-Pilot
Generative AI is considered to bring the next Industrial Revolution.
Why? Studies show a **37% efficiency boost** in day to day work activities!
### Security and safety
This Chatbot is safe to work with sensitive data. Why?
- First of all it makes use of [Ollama, a local inference engine](https://ollama.com);
- On top of the inference engine, we're running [Mistral, a local and open Large Language Model (LLM)](https://mistral.ai/);
- Also the LLM does not contain any sensitive or enterprise data, as there is no way to secure it in a LLM;
- Instead, your sensitive data is stored securely within the firewall inside [DataStax Enterprise v7 Vector Database](https://www.datastax.com/blog/get-started-with-the-datastax-enterprise-7-0-developer-vector-search-preview);
- And lastly, the chains are built on [RAGStack](https://www.datastax.com/products/ragstack), an enterprise version of Langchain and LLamaIndex, supported by [DataStax](https://www.datastax.com/).""" )
st . divider () La première étape consiste à importer le package streamlit. Ensuite, nous appelons st.markdown pour écrire un titre et enfin nous écrivons du contenu sur la page Web.
Pour démarrer cette application localement, vous devrez installer la dépendance streamlit comme suit (ce qui devrait déjà être fait dans le cadre des prérequis) :
pip install streamlitMaintenant, lancez l'application :
streamlit run app_1.pyCela démarrera le serveur d'applications et vous amènera à la page Web que vous venez de créer.
Simple, n'est-ce pas ? ?
Dans cette étape, nous allons commencer à préparer l'application pour permettre l'interaction du chatbot avec un utilisateur. Nous utiliserons les composants Streamlit suivants : 1. 2. st.chat_input pour qu'un utilisateur puisse autoriser la saisie d'une question 2. st.chat_message('human') pour dessiner la saisie de l'utilisateur 3. st.chat_message('assistant') pour dessiner la réponse du chatbot
Cela donne le code suivant :
# Draw the chat input box
if question := st . chat_input ( "What's up?" ):
# Draw the user's question
with st . chat_message ( 'human' ):
st . markdown ( question )
# Generate the answer
answer = f"""You asked: { question } """
# Draw the bot's answer
with st . chat_message ( 'assistant' ):
st . markdown ( answer ) Essayez-le en utilisant app_2.py et lancez-le comme suit.
Si votre application précédente est toujours en cours d’exécution, supprimez-la simplement en appuyant au préalable sur ctrl-c .
streamlit run app_2.pyTapez maintenant une question, puis tapez-en une autre. Vous verrez que seule la dernière question est conservée.
Pourquoi???
En effet, Streamlit redessinera tout l'écran encore et encore en fonction de la dernière entrée. Comme nous ne mémorisons pas les questions, seule la dernière est affichée.
Au cours de cette étape, nous veillerons à garder une trace des questions et des réponses afin qu'à chaque redessinage, l'historique soit affiché.
Pour ce faire, nous allons suivre les étapes suivantes :
st.session_state appelé messagesst.session_state appelé messagesfor message in st.session_state.messages Cette approche fonctionne car le session_state est avec état lors des exécutions Streamlit.
Consultez le code complet dans app_3.py.
Comme vous le verrez, nous utilisons un dictionnaire pour stocker à la fois le role (qui peut être l'humain ou l'IA) et la question ou answer . Garder une trace du rôle est important car cela dessinera la bonne image dans le navigateur.
Exécutez-le avec :
streamlit run app_3.pyAjoutez maintenant plusieurs questions et vous verrez qu'elles sont redessinées à l'écran à chaque réexécution de Streamlit. ?
Ici, nous ferons un lien vers le travail que nous avons effectué à l'aide du Jupyter Notebook et intégrerons la question avec un appel au modèle de chat Mistral.
N'oubliez pas que Streamlit réexécute le code à chaque fois qu'un utilisateur interagit ? Pour cette raison, nous utiliserons la mise en cache des données et des ressources dans Streamlit afin qu'une connexion ne soit établie qu'une seule fois. Nous utiliserons @st.cache_data() et @st.cache_resource() pour définir la mise en cache. cache_data est généralement utilisé pour les structures de données. cache_resource est principalement utilisé pour des ressources telles que les bases de données.
Cela donne le code suivant pour configurer le modèle d'invite et de discussion :
# Cache prompt for future runs
@ st . cache_data ()
def load_prompt ():
template = """You're a helpful AI assistent tasked to answer the user's questions.
You're friendly and you answer extensively with multiple sentences. You prefer to use bulletpoints to summarize.
QUESTION:
{question}
YOUR ANSWER:"""
return ChatPromptTemplate . from_messages ([( "system" , template )])
prompt = load_prompt ()
# Cache Mistral Chat Model for future runs
@ st . cache_resource ()
def load_chat_model ():
# parameters for ollama see: https://api.python.langchain.com/en/latest/chat_models/langchain_community.chat_models.ollama.ChatOllama.html
# num_ctx is the context window size
return ChatOllama (
model = "mistral:latest" ,
num_ctx = 18192 ,
base_url = st . secrets [ 'OLLAMA_ENDPOINT' ]
)
chat_model = load_chat_model ()Au lieu de la réponse statique que nous avons utilisée dans les exemples précédents, nous allons maintenant passer à l'appel de Chain :
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'question' : lambda x : x [ 'question' ]
})
chain = inputs | prompt | chat_model
response = chain . invoke ({ 'question' : question })
answer = response . contentConsultez le code complet dans app_4.py.
Avant de continuer, nous devons fournir le OLLAMA_ENDPOINT dans ./streamlit/secrets.toml . Il y a un exemple fourni dans secrets.toml.example :
# Ollama/Mistral Endpoint
OLLAMA_ENDPOINT = " http://localhost:11434 "Pour démarrer cette application localement, vous devrez installer RAGStack qui contient une version stable de LangChain et toutes les dépendances (ce qui devrait déjà être fait dans le cadre des prérequis) :
pip install ragstackMaintenant, lancez l'application :
streamlit run app_4.pyVous pouvez maintenant démarrer votre interaction questions-réponses avec le Chatbot. Bien entendu, comme il n’y a pas d’intégration avec le DataStax Enterprise Vector Store, il n’y aura pas de réponses contextualisées. Comme il n'y a pas encore de streaming intégré, veuillez donner à l'agent un peu de temps pour trouver la réponse complète immédiatement.
Commençons par la question :
What does Daniel Radcliffe get when he turns 18?
Comme vous le verrez, vous recevrez une réponse très générique sans les informations disponibles dans les données CNN.
Maintenant, les choses deviennent vraiment intéressantes ! Dans cette étape, nous intégrerons le DataStax Enterprise Vector Store afin de fournir un contexte en temps réel pour le modèle de discussion. Étapes prises pour mettre en œuvre la génération augmentée par récupération :
Nous réutiliserons les données CNN que nous avons insérées grâce au notebook.
Pour ce faire, nous devons d'abord établir une connexion au DataStax Enterprise Vector Store :
# Cache the DataStax Enterprise Vector Store for future runs
@ st . cache_resource ( show_spinner = 'Connecting to Datastax Enterprise v7 with Vector Support' )
def load_vector_store ():
# Connect to DSE
cluster = Cluster (
[ st . secrets [ 'DSE_ENDPOINT' ]]
)
session = cluster . connect ()
# Connect to the Vector Store
vector_store = Cassandra (
session = session ,
embedding = HuggingFaceEmbeddings (),
keyspace = st . secrets [ 'DSE_KEYSPACE' ],
table_name = st . secrets [ 'DSE_TABLE' ]
)
return vector_store
vector_store = load_vector_store ()
# Cache the Retriever for future runs
@ st . cache_resource ( show_spinner = 'Getting retriever' )
def load_retriever ():
# Get the retriever for the Chat Model
retriever = vector_store . as_retriever (
search_kwargs = { "k" : 5 }
)
return retriever
retriever = load_retriever ()La seule autre chose que nous devons faire est de modifier la chaîne pour inclure un appel au Vector Store :
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'context' : lambda x : retriever . get_relevant_documents ( x [ 'question' ]),
'question' : lambda x : x [ 'question' ]
})Consultez le code complet dans app_5.py.
Avant de continuer, nous devons fournir les DSE_ENDPOINT , DSE_KEYSPACE et DSE_TABLE dans ./streamlit/secrets.toml . Il y a un exemple fourni dans secrets.toml.example :
# DataStax Enterprise Endpoint
DSE_ENDPOINT = " localhost "
DSE_KEYSPACE = " default_keyspace "
DSE_TABLE = " dse_vector_table "Et lancez l'application :
streamlit run app_5.pyPosons à nouveau la question :
What does Daniel Radcliffe get when he turns 18?
Comme vous le verrez, vous recevrez désormais une réponse très contextuelle car le Vector Store fournit des données CNN pertinentes au modèle de chat.
Ce serait vraiment cool de voir la réponse apparaître à l'écran au fur et à mesure qu'elle est générée ! Eh bien, c'est facile.
Tout d’abord, nous allons créer un gestionnaire de rappel de streaming qui est appelé à chaque nouvelle génération de jeton comme suit :
# Streaming call back handler for responses
class StreamHandler ( BaseCallbackHandler ):
def __init__ ( self , container , initial_text = "" ):
self . container = container
self . text = initial_text
def on_llm_new_token ( self , token : str , ** kwargs ):
self . text += token
self . container . markdown ( self . text + "▌" )Ensuite, nous expliquons le modèle de chat pour utiliser le StreamHandler :
response = chain . invoke ({ 'question' : question }, config = { 'callbacks' : [ StreamHandler ( response_placeholder )]}) Le response_placeholer dans le code ci-dessus définit l'endroit où les jetons doivent être écrits. Nous pouvons créer cet espace en appelant st.empty() comme suit :
# UI placeholder to start filling with agent response
with st . chat_message ( 'assistant' ):
response_placeholder = st . empty ()Consultez le code complet dans app_6.py.
Et lancez l'application :
streamlit run app_6.pyVous verrez maintenant que la réponse sera écrite en temps réel dans la fenêtre du navigateur.
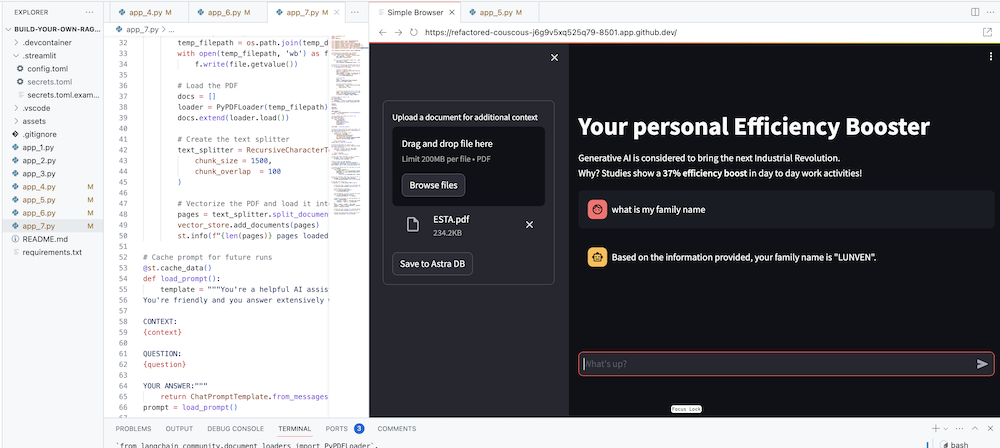
Le but ultime est bien sûr d'ajouter le contexte de votre propre entreprise à l'agent. Pour ce faire, nous ajouterons une boîte de téléchargement qui vous permettra de télécharger des fichiers PDF qui seront ensuite utilisés pour fournir une réponse significative et contextuelle !
Nous avons d’abord besoin d’un formulaire de téléchargement simple à créer avec Streamlit :
# Include the upload form for new data to be Vectorized
with st . sidebar :
with st . form ( 'upload' ):
uploaded_file = st . file_uploader ( 'Upload a document for additional context' , type = [ 'pdf' ])
submitted = st . form_submit_button ( 'Save to DataStax Enterprise' )
if submitted :
vectorize_text ( uploaded_file )Nous avons maintenant besoin d'une fonction pour charger le PDF et l'ingérer dans DataStax Enterprise tout en vectorisant le contenu.
# Function for Vectorizing uploaded data into DataStax Enterprise
def vectorize_text ( uploaded_file , vector_store ):
if uploaded_file is not None :
# Write to temporary file
temp_dir = tempfile . TemporaryDirectory ()
file = uploaded_file
temp_filepath = os . path . join ( temp_dir . name , file . name )
with open ( temp_filepath , 'wb' ) as f :
f . write ( file . getvalue ())
# Load the PDF
docs = []
loader = PyPDFLoader ( temp_filepath )
docs . extend ( loader . load ())
# Create the text splitter
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1500 ,
chunk_overlap = 100
)
# Vectorize the PDF and load it into the DataStax Enterprise Vector Store
pages = text_splitter . split_documents ( docs )
vector_store . add_documents ( pages )
st . info ( f" { len ( pages ) } pages loaded." )Consultez le code complet dans app_7.py.
Pour démarrer cette application localement, vous devrez installer la dépendance PyPDF comme suit (ce qui devrait déjà être fait dans le cadre des prérequis) :
pip install pypdfEt lancez l'application :
streamlit run app_7.pyTéléchargez maintenant un document PDF (plus on est de fous, plus on est de fous) qui vous concerne et commencez à poser des questions à ce sujet. Vous verrez que les réponses seront pertinentes, significatives et contextuelles ! ? Voyez la magie opérer !