Dans le cercle de l'IA, Yann Lecun, lauréat du prix Turing, est une exception typique.
Alors que de nombreux experts techniques croient fermement que, selon le parcours technique actuel, la réalisation de l'AGI n'est qu'une question de temps, Yann Lecun a soulevé des objections à plusieurs reprises.
Au cours de débats houleux avec ses pairs, il a déclaré à plusieurs reprises que la voie technologique actuelle ne peut pas nous conduire à l'AGI, et que même le niveau actuel de l'IA n'est pas aussi bon qu'un chat.
Lauréat du prix Turing, scientifique en chef du Meta en IA, professeur à l'Université de New York, etc. Ces titres éblouissants et cette riche expérience pratique de première ligne font qu'il est impossible pour chacun d'entre nous d'ignorer les idées de cet expert en IA.

Alors, que pense Yann LeCun du futur de l’IA ? Dans un récent discours public, il a une fois de plus développé son point de vue : l’IA ne pourra jamais atteindre un niveau d’intelligence proche de celui de l’humain en s’appuyant uniquement sur l’entraînement textuel.
Certains points de vue sont les suivants :
1. À l'avenir, les gens porteront généralement des lunettes intelligentes ou d'autres types d'appareils intelligents. Ces appareils seront dotés de systèmes d'assistance intégrés pour former des équipes virtuelles personnelles intelligentes afin d'améliorer la créativité et l'efficacité personnelles.
2. Le but des systèmes intelligents n’est pas de remplacer les humains, mais de renforcer l’intelligence humaine afin que les gens puissent travailler plus efficacement.
3. Même un chat de compagnie a un modèle dans son cerveau qui est plus complexe que ce qu'un système d'IA peut construire.
4. FAIR ne se concentre fondamentalement plus sur les modèles de langage, mais s'oriente vers l'objectif à long terme des systèmes d'IA de nouvelle génération.
5. Les systèmes d’IA ne peuvent pas atteindre une intelligence proche du niveau humain en s’entraînant uniquement sur des données textuelles.
6. Yann Lecun a suggéré d'abandonner les modèles génératifs, les modèles probabilistes, l'apprentissage contrastif et l'apprentissage par renforcement, et d'adopter à la place l'architecture JEPA et les modèles basés sur l'énergie, estimant que ces méthodes sont plus susceptibles de favoriser le développement de l'IA.
7. Même si les machines finiront par dépasser l’intelligence humaine, elles seront contrôlées parce qu’elles sont motivées par un objectif.
Fait intéressant, il y a eu un épisode avant le début du discours.
Lorsque l'animateur a présenté LeCun, il l'a appelé le scientifique en chef de l'IA du Facebook AI Research Institute (FAIR) .
À cet égard, LeCun a précisé avant le discours que le « F » de FAIR ne représente plus Facebook, mais signifie « Fondamental ».
Le texte original du discours ci-dessous a été compilé par APPSO et a été édité. Enfin, le lien vidéo original est joint : https://www.youtube.com/watch?v=4DsCtgtQlZU
L’IA ne comprend pas le monde aussi bien que votre chat
D'accord, je vais donc parler de l'IA au niveau humain et de la façon dont nous allons y arriver et pourquoi nous n'y arriverons pas.
Premièrement, nous avons vraiment besoin d’une IA à l’échelle humaine.
Parce qu’à l’avenir, la plupart d’entre nous porteront des lunettes intelligentes ou d’autres types d’appareils. Nous allons parler à ces appareils, et ces systèmes vont héberger des assistants, peut-être plus d'un, peut-être toute une suite d'assistants.
Cela se traduira par le fait que chacun de nous disposera essentiellement d’une équipe virtuelle intelligente travaillant pour nous.
Ainsi, tout le monde deviendra un « patron », mais ces « employés » ne sont pas de vrais humains. Nous devons construire des systèmes comme celui-ci, essentiellement pour augmenter l’intelligence humaine et rendre les gens plus créatifs et efficaces.

Mais pour cela, nous avons besoin de machines capables de comprendre le monde, de se souvenir des choses, d’avoir de l’intuition et du bon sens, de raisonner et de planifier au même niveau que les humains.
Bien que vous ayez peut-être entendu certains partisans dire que les systèmes d’IA actuels ne disposent pas de ces capacités. Nous devons donc prendre le temps d’apprendre à modéliser le monde, à avoir des modèles mentaux du fonctionnement du monde.
Pratiquement tous les animaux possèdent un tel modèle. Votre chat doit avoir un modèle plus complexe que n’importe quel système d’IA peut construire ou concevoir.

Nous avons besoin d'un système doté d'une mémoire persistante que les modèles de langage actuels (LLM) n'ont pas, d'un système capable de planifier des séquences complexes d'actions que les systèmes actuels ne peuvent pas effectuer, et d'un système contrôlable et sûr.
Par conséquent, je proposerai une architecture appelée IA axée sur les objectifs. J'ai écrit un article de vision à ce sujet il y a environ deux ans et je l'ai publié. De nombreuses personnes chez FAIR travaillent dur pour faire de ce plan une réalité.
FAIR a travaillé sur davantage de projets d'application dans le passé, mais Meta a créé il y a un an et demi une division de produits appelée Generative AI (Gen AI) pour se concentrer sur les produits d'IA.
Ils font de la recherche appliquée et du développement, c'est pourquoi FAIR a maintenant été réorienté vers l'objectif à long terme des systèmes d'IA de nouvelle génération. En principe, nous ne nous concentrons plus sur les modèles de langage.
Le succès de l’IA, y compris les grands modèles linguistiques (LLM) , et en particulier le succès de nombreux autres systèmes au cours des 5 ou 6 dernières années, repose sur une gamme de techniques, y compris, bien sûr, l’apprentissage auto-supervisé.

Le cœur de l’apprentissage auto-supervisé est de former un système non pas pour une tâche spécifique, mais d’essayer de représenter correctement les données d’entrée. Une façon d’y parvenir consiste à procéder à une récupération après dommage et à une reconstruction.
Vous pouvez donc prendre un morceau de texte et le corrompre en supprimant certains mots ou en en modifiant d'autres. Ce procédé peut être utilisé pour du texte, des séquences d'ADN, des protéines ou tout autre chose, et même dans une certaine mesure des images. Vous entraînez ensuite un réseau neuronal massif pour reconstruire l’entrée complète, la version non corrompue.
Il s'agit d'un modèle génératif car il tente de reconstruire le signal original.
Donc, la case rouge est comme une fonction de coût, n’est-ce pas ? Il calcule la distance entre l'entrée Y et la sortie y reconstruite, et c'est le paramètre à minimiser lors du processus d'apprentissage. Au cours de ce processus, le système apprend une représentation interne de l'entrée, qui peut être utilisée pour diverses tâches ultérieures.
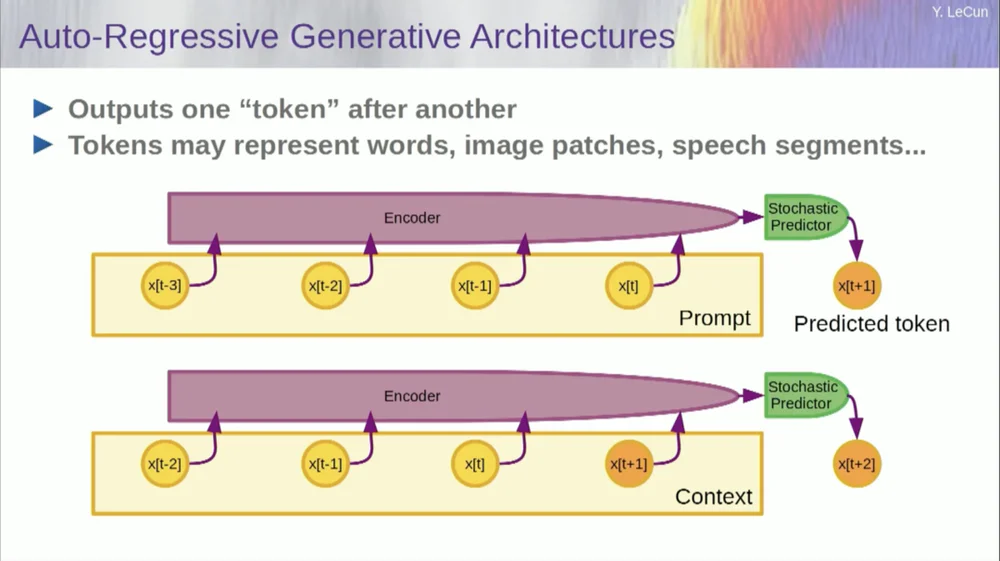
Bien sûr, cela peut être utilisé pour prédire des mots dans un texte, ce que fait la prédiction autorégressive .
Les modèles de langage en sont un cas particulier, où l'architecture est conçue de telle manière que lors de la prédiction d'un élément, d'un jeton ou d'un mot, elle ne peut regarder que les autres jetons à sa gauche.
Il ne peut pas regarder vers l’avenir. Si vous entraînez correctement un système, lui montrez du texte et lui demandez de prédire le mot suivant ou le prochain jeton dans le texte, vous pouvez alors utiliser le système pour prédire le mot suivant. Ensuite, vous ajoutez le mot suivant à l'entrée, prédisez le deuxième mot, et ajoutez-le à l'entrée, prédisez le troisième mot.
Il s'agit d' une prédiction autorégressive .
C'est ce que font les LLM, ce n'est pas un concept nouveau, cela existe depuis l'époque de Shannon , remontant aux années 50, c'est-à-dire il y a longtemps, mais le changement est que nous avons maintenant ces architectures massives de réseaux neuronaux, vous pouvez former sur de grandes quantités de données et des fonctionnalités sembleront en émerger.
Mais ce type de prédiction autorégressive présente des limites majeures, et il n’y a pas ici de véritable raisonnement au sens habituel du terme.
Une autre limitation est que cela ne fonctionne que pour les données sous forme d'objets discrets, de symboles, de jetons, de mots, etc., essentiellement des éléments qui peuvent être discrétisés.
Il nous manque encore quelque chose d'important lorsqu'il s'agit d'atteindre une intelligence au niveau humain.
Je ne parle pas nécessairement ici d’intelligence humaine, mais même votre chat ou votre chien peut accomplir des exploits incroyables qui sont hors de portée des systèmes d’IA actuels.

N’importe quel enfant de 10 ans peut apprendre à débarrasser la table et à remplir le lave-vaisselle en une seule fois, n’est-ce pas ? Pas besoin de s’entraîner ou quoi que ce soit du genre, n’est-ce pas ?
Il faut environ 20 heures de pratique à un jeune de 17 ans pour apprendre à conduire.
Nous n’avons toujours pas de voitures autonomes de niveau 5, et nous n’avons certainement pas de robots domestiques capables de débarrasser les tables et de remplir les lave-vaisselle.
L’IA n’atteindra jamais une intelligence proche du niveau humain en s’entraînant uniquement sur du texte
Il nous manque donc vraiment quelque chose d'important qui, autrement, nous permettrait de faire ces choses avec les systèmes d'IA.
Nous rencontrons sans cesse quelque chose appelé le paradoxe de Moravec , à savoir que des choses qui nous semblent insignifiantes et qui ne sont même pas considérées comme intelligentes sont en réalité très difficiles à réaliser avec des machines, et des choses comme la manipulation. La pensée abstraite complexe de haut niveau, comme le langage, semble être très simple pour les machines, et il en va de même pour des choses comme jouer aux échecs et au Go.
Peut-être que l'une des raisons est la suivante.
Un modèle de langage étendu (LLM) est généralement formé sur 20 000 milliards de jetons.
Un jeton représente en moyenne les trois quarts d’un mot. Par conséquent, il y a 1,5×10^13 mots au total. Chaque jeton fait environ 3 Go, cela nécessite généralement 6 × 1013 octets.
Il faudrait environ quelques centaines de milliers d’années à chacun d’entre nous pour lire ceci, n’est-ce pas ? Il s’agit essentiellement de tous les textes publics sur Internet combinés.

Mais pensez à un enfant de quatre ans qui est resté éveillé pendant 16 000 heures au total. Nous avons 2 millions de fibres nerveuses optiques qui pénètrent dans notre cerveau. Chaque fibre nerveuse transmet des données à raison d'environ 1 Mo par seconde, peut-être un demi-octet par seconde. Certaines estimations indiquent que cela pourrait représenter 3 milliards par seconde.
Ce n’est pas grave, c’est quand même un ordre de grandeur.
Cette quantité de données est d'environ 10 puissance 14 octets, ce qui est presque du même ordre de grandeur que LLM. Ainsi, en quatre ans, un enfant de quatre ans a vu autant de données visuelles que les plus grands modèles de langage formés sur du texte accessible au public sur l'ensemble d'Internet.
En utilisant les données comme point de départ, cela nous apprend plusieurs choses.
Premièrement, cela nous indique que nous n’atteindrons jamais une intelligence proche du niveau humain simplement en nous entraînant sur du texte. Cela n’arrivera tout simplement pas.
Deuxièmement, les informations visuelles sont très redondantes. Chaque fibre du nerf optique transmet 1 milliard d'informations par seconde, ce qui est déjà compressé à 100 pour 1 par rapport aux photorécepteurs de votre rétine.
Il y a environ 60 à 100 millions de photorécepteurs dans notre rétine. Ces photorécepteurs sont comprimés en 1 million de fibres nerveuses par les neurones situés à l'avant de la rétine. Il y a donc déjà une compression de 100 pour 1. Puis, au moment où elle atteint le cerveau, l’information est développée environ 50 fois.
Ce que je mesure, ce sont des informations compressées, mais elles restent très redondantes. Et la redondance est en réalité ce qu’exige l’apprentissage auto-supervisé. L'apprentissage auto-supervisé n'apprendra que des choses utiles à partir de données redondantes. Si les données sont fortement compressées, ce qui signifie qu'elles deviennent du bruit aléatoire, vous ne pouvez rien apprendre.
Il faut de la redondance pour apprendre quoi que ce soit. Vous devez apprendre la structure sous-jacente des données. Par conséquent, nous devons entraîner le système à apprendre le bon sens et la physique en regardant des vidéos ou en vivant dans le monde réel.
L’ordre de mes mots peut être un peu déroutant. Je veux principalement vous dire ce qu’est cette architecture d’intelligence artificielle axée sur les objectifs. C'est très différent des LLM ou des neurones feedforward dans la mesure où le processus d'inférence ne passe pas seulement par une série de couches d'un réseau neuronal, mais exécute en fait un algorithme d'optimisation.
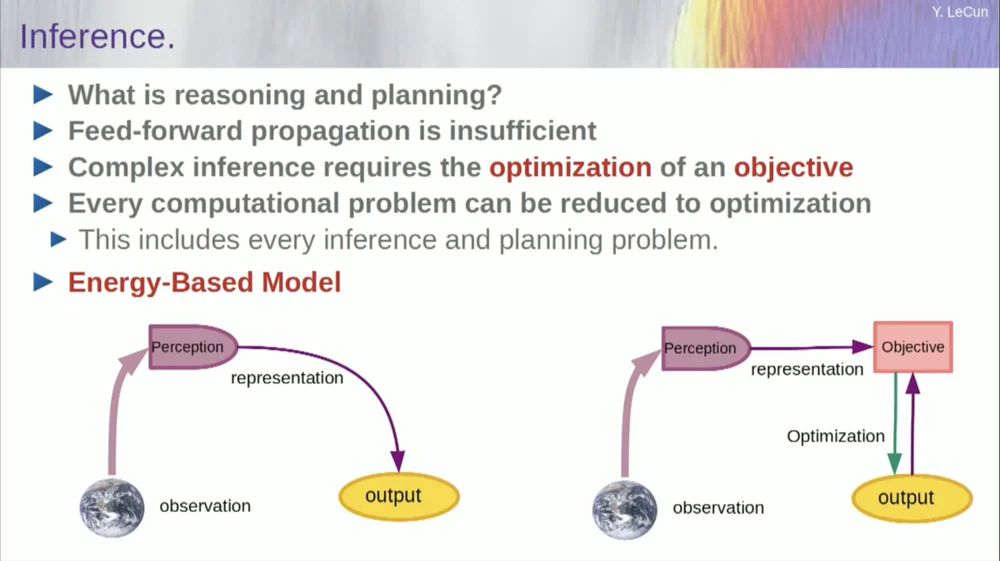
Conceptuellement, cela ressemble à ceci.
Un processus de rétroaction est un processus dans lequel les observations passent par un système de perception. Par exemple, si vous disposez d’une série de couches de réseau neuronal et produisez une sortie, alors pour une seule entrée, vous ne pouvez avoir qu’une seule sortie, mais dans de nombreux cas, pour une perception, il peut y avoir plusieurs interprétations de sortie possibles. Vous avez besoin d'un processus de mappage qui ne se contente pas de calculer les fonctionnalités, mais qui fournit plusieurs sorties pour une seule entrée. La seule façon d’y parvenir est d’utiliser des fonctions implicites.
Fondamentalement, la case rouge sur le côté droit de ce cadre d'objectifs représente une fonction qui mesure essentiellement la compatibilité entre une entrée et sa sortie proposée, puis calcule la sortie en trouvant la valeur de sortie la plus compatible avec l'entrée. Vous pouvez imaginer que cet objectif est une sorte de fonction énergétique et que vous minimisez cette énergie avec la production comme variable.
Vous pouvez avoir plusieurs solutions et vous pouvez avoir un moyen de gérer ces multiples solutions. Cela est vrai du système de perception humain. Si vous avez plusieurs interprétations d’une perception particulière, votre cerveau passera automatiquement d’une interprétation à l’autre. Il existe donc des preuves que ce genre de chose se produit.
Mais revenons à l'architecture. Profitez donc de ce principe de raisonnement par optimisation. Voici les hypothèses, si vous voulez, sur le fonctionnement de l’esprit humain. Vous faites des observations dans le monde. Le système de perception vous donne une idée de l'état actuel du monde. Mais bien sûr, cela ne vous donne qu’une idée de l’état du monde que vous pouvez percevoir actuellement.
Vous avez peut-être quelques idées sur l’état du reste du monde. Ceci peut être combiné avec le contenu de la mémoire et intégré dans un modèle du monde.
Qu'est-ce qu'un modèle ? Un modèle mondial est un modèle mental de la façon dont vous vous comportez dans le monde. Vous pouvez donc imaginer une séquence d'actions que vous pourriez entreprendre, et votre modèle mondial vous permettra de prédire l'impact de ces séquences d'actions sur le monde.
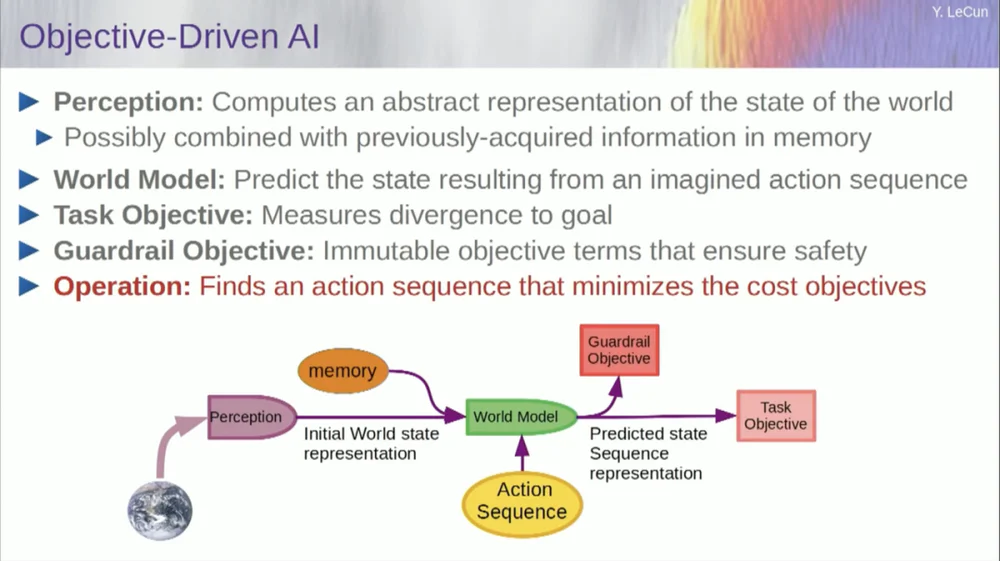
Ainsi, la case verte représente le modèle du monde dans lequel vous introduisez une séquence hypothétique d’actions qui prédit quel sera l’état final du monde, ou la trajectoire entière que vous prédisez qui se produira dans le monde.
Vous combinez cela avec un ensemble de fonctions objectives. L'un des objectifs est de mesurer dans quelle mesure l'objectif est atteint, si la tâche est terminée, et peut-être un ensemble d'autres objectifs qui servent de marges de sécurité, mesurant essentiellement dans quelle mesure la trajectoire suivie ou l'action entreprise ne présente aucun danger pour le robot. ou des personnes autour de la machine, etc. attendent.
Alors maintenant, le processus de raisonnement (je n'ai pas encore parlé d'apprentissage) n'est qu'un raisonnement et consiste à trouver des séquences d'actions qui minimisent ces objectifs, à trouver des séquences d'actions qui minimisent ces objectifs. C'est le processus de raisonnement.
Il ne s’agit donc pas simplement d’un processus de rétroaction. Vous pouvez le faire en recherchant des options discrètes, mais ce n'est pas efficace. Une meilleure approche consiste à garantir que toutes ces cases sont différenciables, vous pouvez rétropropager le dégradé à travers elles, puis mettre à jour la séquence d'actions via la descente de gradient.

Cette idée n’est en réalité pas nouvelle et existe depuis plus de 60 ans, peut-être même plus. Tout d’abord, permettez-moi de parler des avantages de l’utilisation d’un modèle mondial pour ce type de raisonnement. L'avantage est que vous pouvez effectuer de nouvelles tâches sans aucun apprentissage requis.
Nous faisons cela de temps en temps. Lorsque nous sommes confrontés à une nouvelle situation, nous y réfléchissons, imaginons les conséquences de nos actions, puis prenons une séquence d'actions qui permettront d'atteindre notre objectif (quel qu'il soit) . Nous n'avons pas besoin d'apprendre pour accomplir cette tâche. , nous pouvons planifier. Il s’agit donc essentiellement de planification.
Vous pouvez résumer la plupart des formes de raisonnement à l’optimisation. Par conséquent, le processus d’inférence par optimisation est intrinsèquement plus puissant que le simple fait de parcourir plusieurs couches d’un réseau neuronal. Comme je l'ai dit, cette idée de raisonnement par optimisation existe depuis plus de 60 ans.
Dans le domaine de la théorie du contrôle optimal, on parle alors de contrôle prédictif par modèle.
Vous disposez d'un modèle d'un système que vous souhaitez contrôler, comme une fusée, un avion ou un robot. Vous pouvez imaginer utiliser votre modèle mondial pour calculer les effets d’une série de commandes de contrôle.
Ensuite, vous optimisez cette séquence pour que le mouvement atteigne les résultats souhaités. Toute planification de mouvement en robotique classique se fait de cette façon, et ce n'est pas nouveau. La nouveauté ici est que nous apprendrons un modèle du monde et que le système de perception en extraira une représentation abstraite appropriée.
Maintenant, avant de donner un exemple de fonctionnement de ce système, vous pouvez créer un système d'IA global avec tous ces composants : un modèle mondial, une fonction de coût qui peut être configurée pour la tâche à accomplir, un module d'optimisation (c'est-à-dire, véritablement optimiser, trouver le module donné qui détermine la séquence d'actions optimale pour le modèle du monde) , la mémoire à court terme, le système de perception, etc.
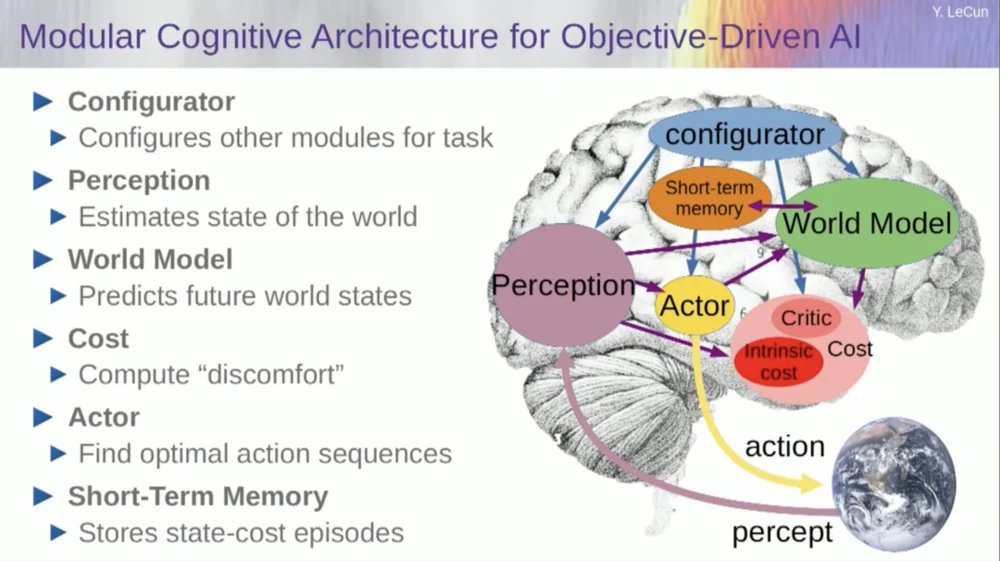
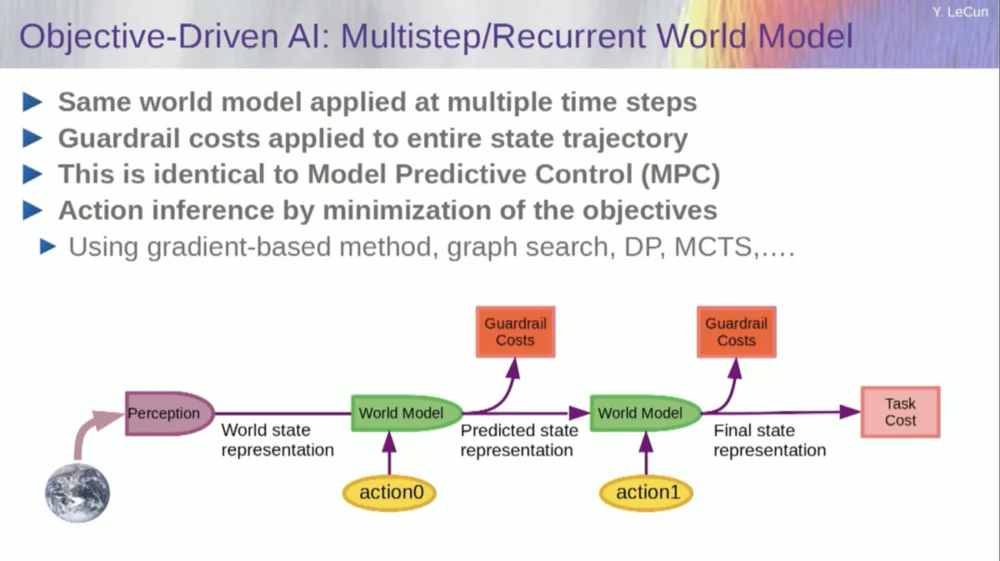
Alors, comment ça marche ? Si votre action n'est pas une action unique, mais une séquence d'actions et que votre modèle du monde est en fait un système qui vous indique, étant donné l'état du monde au temps T et les actions possibles, prédisez l'état du monde au temps T+1 .
Vous souhaitez prédire quel effet aura une séquence de deux actions dans cette situation. Vous pouvez exécuter votre modèle mondial plusieurs fois pour y parvenir.
Obtenez la représentation initiale de l'état du monde, saisissez l'hypothèse de zéro pour l'action, utilisez le modèle pour prédire l'état suivant, puis effectuez la première action, calculez l'état suivant, calculez le coût, puis utilisez les méthodes de rétropropagation et d'optimisation basées sur le gradient pour découvrez ce qui minimisera le coût de deux actions. Il s’agit d’un contrôle prédictif de modèle.
Or, le monde n’est pas complètement déterministe, vous devez donc utiliser des variables latentes pour correspondre à votre modèle du monde. Les variables latentes sont essentiellement des variables qui peuvent être commutées au sein d'un ensemble de données ou tirées d'une distribution, et elles représentent la commutation d'un modèle du monde entre plusieurs prédictions compatibles avec les observations.
Ce qui est encore plus intéressant, c’est que les systèmes intelligents sont actuellement incapables de faire quelque chose que les humains et même les animaux peuvent faire, à savoir la planification hiérarchique.
Par exemple, si vous planifiez un voyage de New York à Paris, vous pourriez utiliser votre compréhension du monde, de votre corps et peut-être votre idée de toute la configuration pour vous rendre d'ici à Paris pour planifier l'intégralité de votre voyage avec votre contrôle musculaire de bas niveau.
Droite? Si vous additionnez le nombre de pas de contrôle musculaire toutes les dix millisecondes de tout ce que vous devez faire avant d'aller à Paris, c'est un chiffre énorme. Donc, ce que vous faites, c'est planifier de manière hiérarchique, où vous commencez à un niveau très élevé et dites, d'accord, pour arriver à Paris, je dois d'abord aller à l'aéroport, monter dans un avion.
Comment puis-je me rendre à l'aéroport ? Disons que je suis à New York et que je dois descendre chercher un taxi. Comment puis-je descendre ? Je dois me lever de ma chaise, ouvrir la porte, marcher jusqu'à l'ascenseur, appuyer sur le bouton, etc. Comment se lever d'une chaise ?
À un moment donné, vous devrez exprimer les choses sous forme d'actions de contrôle musculaire de bas niveau, mais nous ne planifions pas le tout de manière bas niveau, nous faisons une planification hiérarchique.

Comment y parvenir à l’aide de systèmes d’IA n’est toujours pas résolu et nous n’en avons aucune idée.
Cela semble être une condition importante pour un comportement intelligent.
Alors, comment pouvons-nous apprendre des modèles du monde capables de planification hiérarchique, capables de fonctionner à différents niveaux d’abstraction ? Personne n’a rien montré de comparable. Il s’agit d’un défi majeur. L'image montre l'exemple que je viens de mentionner.
Alors, comment pouvons-nous former ce modèle mondial maintenant ? Parce que c'est effectivement un gros problème.
J'essaie de comprendre à quel âge les bébés apprennent les concepts de base sur le monde. Comment apprennent-ils la physique intuitive, l’intuition physique et tout ça ? Cela se produit bien avant qu’ils ne commencent à apprendre des choses comme la langue et l’interaction.
Ainsi, des fonctionnalités telles que le suivi du visage apparaissent très tôt. Le mouvement biologique, la distinction entre les objets animés et inanimés, apparaît également très tôt. Il en va de même pour la constance des objets, qui fait référence au fait qu'un objet persiste lorsqu'il est masqué par un autre objet.
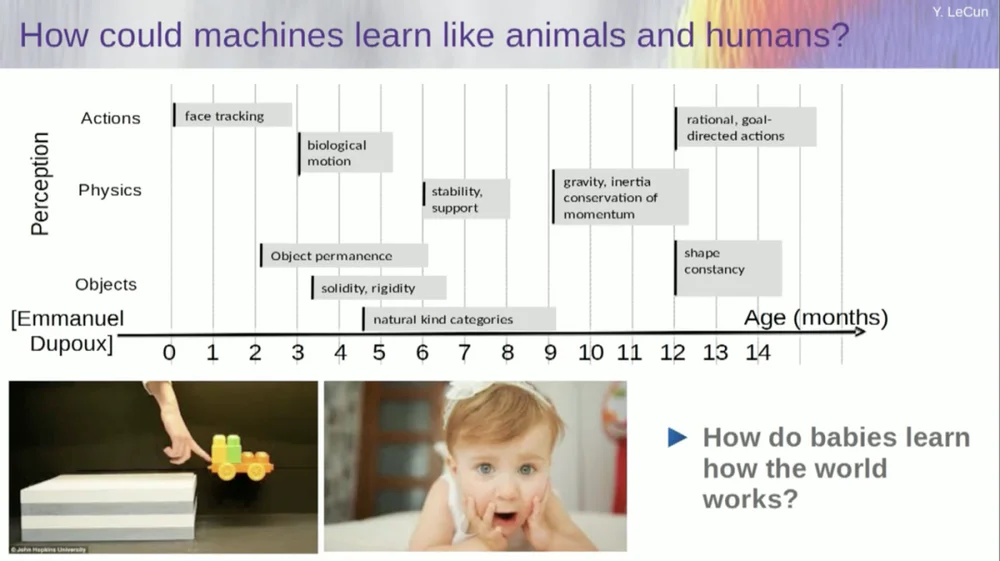
Et les bébés apprennent naturellement, vous n’avez pas besoin de leur donner des noms pour les choses. Ils sauront que les chaises, les tables et les chats sont différents. Quant aux concepts tels que la stabilité et le support, comme la gravité, l’inertie, la conservation et l’élan, ils n’apparaissent en réalité qu’à l’âge de neuf mois environ.
Cela prend beaucoup de temps. Ainsi, si vous montrez à un bébé de six mois le scénario de gauche, où le chariot est sur une plate-forme, et que vous le poussez hors de la plate-forme, il semble flotter dans les airs. Un bébé de six mois le remarquera, tandis qu'un bébé de dix mois aura l'impression que cela ne devrait pas se produire et que l'objet devrait tomber.
Quand quelque chose d’inattendu se produit, cela signifie que votre « modèle du monde » est erroné. Alors faites attention car cela pourrait vous tuer.
Le type d’apprentissage qui doit avoir lieu ici est donc très similaire à celui dont nous avons discuté plus tôt.
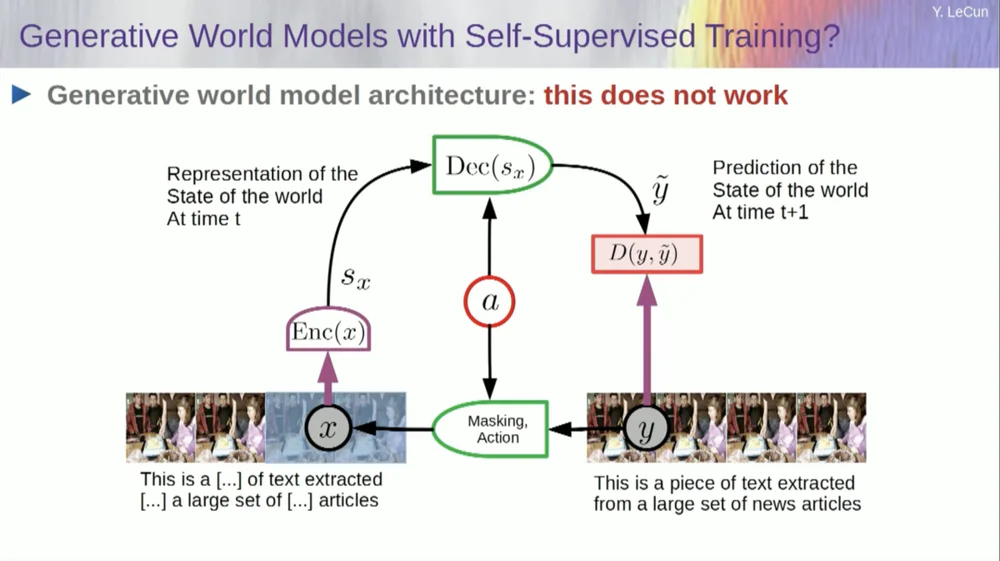
Prenez l'entrée, corrompez-la d'une manière ou d'une autre et entraînez un vaste réseau neuronal pour prédire les pièces manquantes. Si vous entraînez un système à prédire ce qui va se passer dans une vidéo, tout comme nous entraînons des réseaux neuronaux à prédire ce qui va se passer dans un texte, ces systèmes seront peut-être capables d'apprendre le bon sens.
Malheureusement, cela fait dix ans que nous essayons cela et cela a été un échec total. Nous ne nous sommes jamais approchés d'un système capable d'acquérir des connaissances générales en essayant simplement de prédire les pixels d'une vidéo.
Vous pouvez entraîner un système pour prédire les vidéos qui semblent bonnes. Il existe de nombreux exemples de systèmes de génération vidéo, mais en interne, ils ne constituent pas de bons modèles du monde physique. Nous ne pouvons pas faire ça avec eux.
D'accord, donc l'idée selon laquelle nous allons utiliser des modèles génératifs pour prédire ce qui va arriver aux individus, et que le système comprendra comme par magie la structure du monde, est un échec complet.
Au cours de la dernière décennie, nous avons essayé de nombreuses approches.
Cela échoue parce qu’il existe de nombreux futurs possibles. Dans un espace discret comme le texte, où vous pouvez prédire quel mot suivra une chaîne de mots, vous pouvez générer une distribution de probabilité sur les mots possibles dans un dictionnaire. Mais lorsqu’il s’agit d’images vidéo, nous ne disposons pas d’un bon moyen de représenter la distribution de probabilité des images vidéo. En fait, cette tâche est totalement impossible.

J'ai pris une vidéo de cette pièce, non ? J'ai pris la caméra et filmé cette partie, puis j'ai arrêté la vidéo. J'ai demandé au système ce qui se passerait ensuite. Cela pourrait prédire les pièces restantes. Il y aura un mur, il y aura des gens assis dessus, et la densité sera probablement similaire à celle de gauche, mais il est absolument impossible de prédire avec précision au niveau des pixels tous les détails de ce à quoi chacun d'entre vous ressemblera. , la texture du monde et la taille exacte de la pièce.
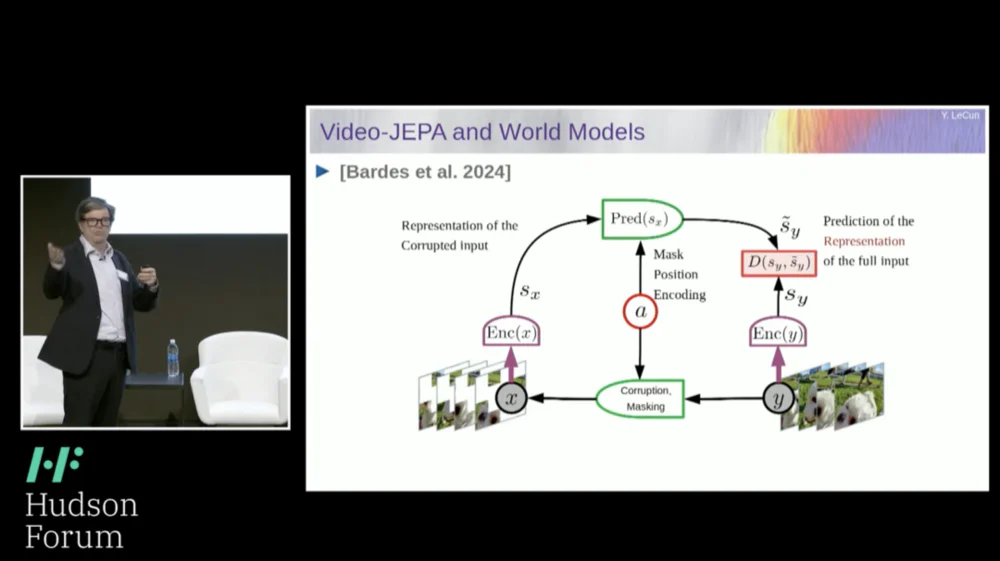
La solution que je propose est donc la Joint Embedding Prediction Architecture (JEPA) .
L’idée est d’abandonner la prédiction des pixels et d’apprendre à la place une représentation abstraite du fonctionnement du monde, puis de faire des prédictions au sein de cet espace de représentation. C’est l’architecture, l’architecture de prédiction intégrée conjointe. Ces deux intégrations prennent respectivement X (la version corrompue) et Y, sont traitées par l'encodeur, puis le système est entraîné à prédire la représentation de Y sur la base de la représentation de X.
Maintenant, le problème est que si vous entraînez un tel système en utilisant simplement la descente de gradient et la rétropropagation pour minimiser l'erreur de prédiction, il s'effondrera. Il pourrait apprendre une représentation constante, de sorte que les prédictions deviendraient très simples, mais peu informatives.
Donc, ce que je veux que vous reteniez, c'est la différence entre les auto-encodeurs, les architectures génératives, les auto-encodeurs masqués, etc., qui tentent de reconstruire des prédictions, et les architectures d'intégration conjointe qui font des prédictions dans l'espace de représentation.
Je pense que l'avenir réside dans ces architectures d'intégration conjointes, et nous disposons de nombreuses preuves empiriques selon lesquelles la meilleure façon d'apprendre de bonnes représentations d'images est d'utiliser des architectures d'édition conjointes.
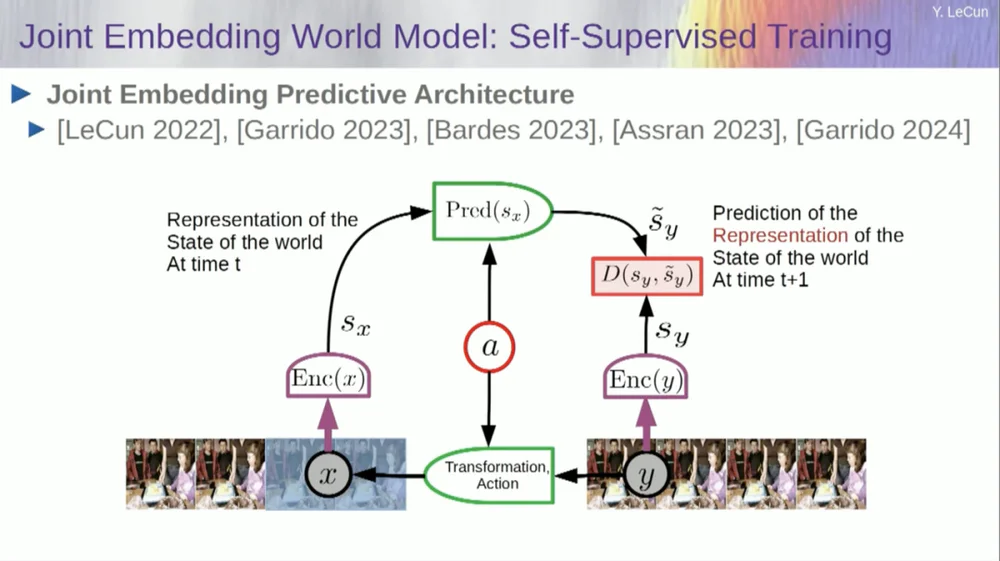
Toutes les tentatives d'apprentissage des représentations d'images par reconstruction ont été médiocres et ne fonctionnent pas bien, et bien que de nombreux grands projets prétendent fonctionner, ce n'est pas le cas, et les meilleures performances sont obtenues avec l'architecture de droite.
Maintenant, si vous y réfléchissez, c'est vraiment à cela que sert notre intelligence : trouver une bonne représentation d'un phénomène afin de pouvoir faire des prédictions, c'est vraiment le but de la science.
réel. Pensez-y, si vous voulez prédire la trajectoire d'une planète, une planète est un objet très complexe, elle est énorme, elle a toutes sortes de caractéristiques comme la météo, la température et la densité.
Bien qu'il s'agisse d'un objet complexe, pour prédire la trajectoire d'une planète, il suffit de connaître 6 nombres : 3 coordonnées de position et 3 vecteurs vitesses, ça y est, vous n'avez rien d'autre à faire. Il s’agit d’un exemple très important qui montre vraiment que l’essence du pouvoir prédictif réside dans la recherche d’une bonne représentation des choses que nous observons.

Alors, comment former un tel système ?
Vous voulez donc empêcher le système de planter. Une façon d'y parvenir consiste à utiliser une sorte de fonction de coût qui mesure le contenu informationnel de la représentation produite par l'encodeur et tente de maximiser le contenu informationnel et de minimiser les informations négatives. Votre système de formation doit simultanément extraire autant d'informations que possible de l'entrée tout en minimisant l'erreur de prédiction dans cet espace de représentation.
Le système trouvera un compromis entre extraire autant d’informations que possible et ne pas extraire d’informations imprévisibles. Vous obtiendrez un bon espace de représentation dans lequel des prédictions pourront être faites.
Maintenant, comment mesurez-vous l’information ? C'est là que les choses deviennent un peu bizarres. Je vais sauter ça.
Les machines dépasseront l’intelligence humaine et seront sûres et contrôlables
Il existe en fait un moyen de comprendre cela mathématiquement grâce à la formation, aux modèles basés sur l'énergie et aux fonctions énergétiques, mais je n'ai pas le temps d'entrer dans les détails.
En gros, je vous dis ici plusieurs choses différentes : abandonnez les modèles génératifs au profit de ces architectures JEPA, abandonnez les modèles probabilistes au profit de ces modèles basés sur l'énergie, abandonnez les méthodes d'apprentissage contrastées et l'apprentissage par renforcement. Je dis cela depuis 10 ans.
Et ce sont les quatre piliers les plus populaires du machine learning aujourd’hui. Je ne suis donc probablement pas très populaire en ce moment.
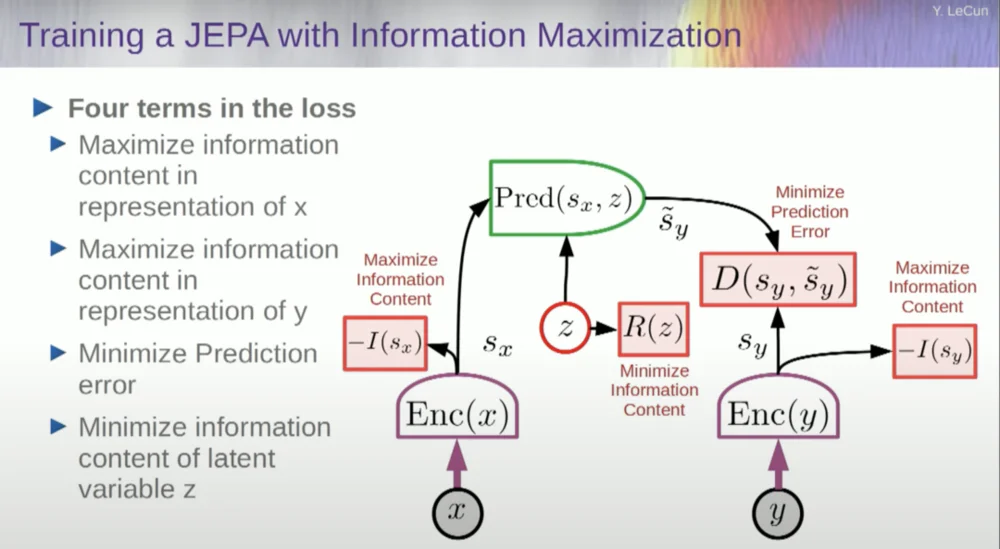
Une approche consiste à estimer le contenu de l’information, en mesurant le contenu de l’information provenant du codeur.
Il existe actuellement six manières différentes d’y parvenir. En fait, il existe ici une méthode appelée MCR, proposée par mes collègues de NYU, qui consiste à empêcher le système de planter et de produire des constantes.
Prenez les variables de l'encodeur et assurez-vous que ces variables ont un écart type non nul. Vous pouvez mettre cela dans une fonction de coût et vous assurer que les poids sont recherchés et que les variables ne s'effondrent pas et ne deviennent pas des constantes. C'est relativement simple.
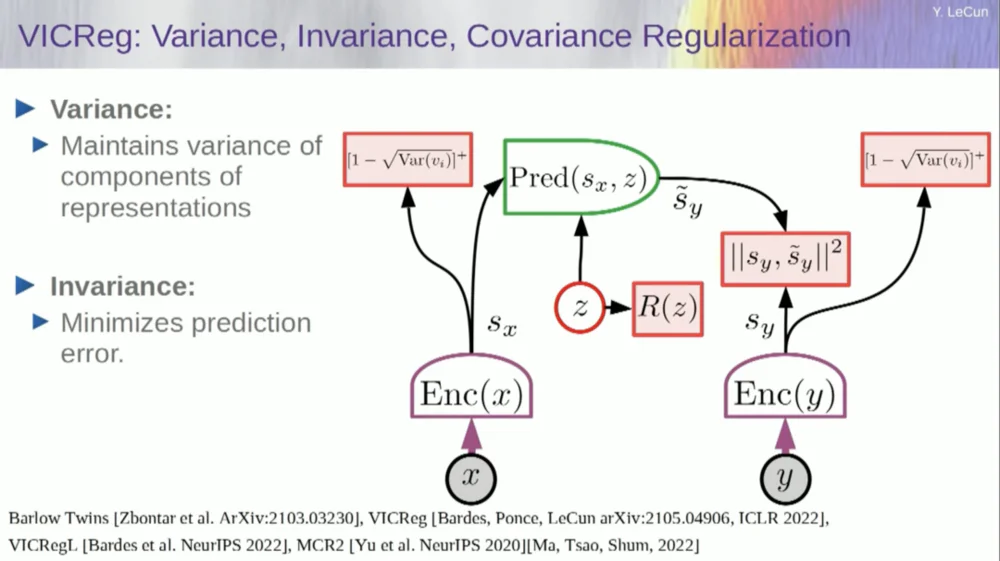
Le problème maintenant est que le système peut « tricher » et rendre toutes les variables égales ou fortement corrélées. Par conséquent, vous devez ajouter un autre terme, le terme hors diagonale requis pour minimiser la matrice de covariance de ces variables, afin de garantir qu'elles sont liées.
Bien entendu, cela ne suffit pas, puisque les variables peuvent toujours être dépendantes, mais non liées. Par conséquent, nous adoptons une autre méthode pour étendre les dimensions de SX à un espace de dimension supérieure VX et appliquons une régularisation de variance-covariance dans cet espace pour garantir que les exigences sont remplies.
Il y a une autre astuce ici, car ce que je maximise est la limite supérieure du contenu de l'information. Je veux que le contenu réel de l'information suive ma maximisation de la limite supérieure. Ce dont j'ai besoin, c'est d'une limite inférieure pour qu'elle repousse la limite inférieure et que l'information augmente. Malheureusement, nous ne disposons pas d’informations sur les limites inférieures, ou du moins nous ne savons pas comment les calculer.
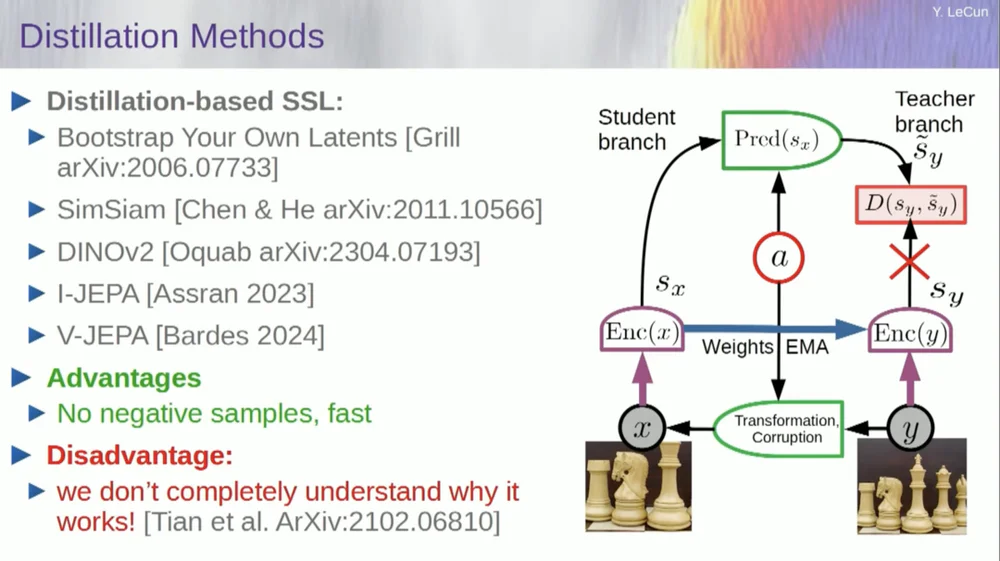
Il existe un deuxième ensemble de méthodes appelées « méthode de style de distillation ».
Cette méthode fonctionne de manière mystérieuse. Si vous voulez savoir exactement qui fait quoi, vous devriez demander au gars assis ici au Grill.
Il a un essai personnel à ce sujet qui le définit très bien. Son idée principale est de mettre à jour une seule partie du modèle sans rétropropager les gradients dans l'autre partie et de partager les poids de manière intéressante. Il existe également de nombreux articles sur cet aspect.
Cette approche fonctionne bien si vous souhaitez entraîner un système entièrement auto-supervisé pour générer de bonnes représentations d'images. La destruction des images se fait par masquage, et certains travaux récents que nous avons réalisés sur les vidéos nous permettent de former un système pour extraire de bonnes représentations vidéo à utiliser dans des tâches en aval telles que des vidéos de reconnaissance d'actions, etc. Vous pouvez voir que le masquage d’une grande partie d’une vidéo et la réalisation de prédictions via ce processus utilisent cette astuce de distillation dans l’espace de représentation pour éviter l’effondrement. Cela fonctionne très bien.
Donc, si nous réussissons ce projet et obtenons des systèmes capables de raisonner, de planifier et de comprendre le monde physique, voilà à quoi ressembleront toutes nos interactions dans le futur.
Il faudra des années, voire une décennie, pour que tout fonctionne correctement. Mark Zuckerberg ne cesse de me demander combien de temps cela prendra. Si nous y parvenons, nous aurons des systèmes qui assureront la médiation de toutes nos interactions avec le monde numérique. Ils répondront à toutes nos questions.
Ils resteront avec nous pendant longtemps et constitueront essentiellement un référentiel de toutes les connaissances humaines. Cela ressemble à une question d’infrastructure, comme Internet. Il s’agit moins d’un produit que d’une infrastructure.
Ces plateformes d'IA doivent être open source. IBM et Meta participent à un groupe appelé Artificial Intelligence Alliance qui promeut les plateformes d'intelligence artificielle open source. Nous avons besoin que ces plateformes soient open source car nous avons besoin de diversité dans ces systèmes d'IA.

Nous avons besoin qu'ils comprennent toutes les langues, toutes les cultures, tous les systèmes de valeurs du monde, et vous n'obtiendrez pas cela avec un seul système produit par une entreprise de la côte ouest ou de la côte est des États-Unis. États. Cela doit être une contribution du monde entier.
Bien entendu, la formation de modèles financiers coûte très cher et seules quelques entreprises sont en mesure de le faire. Si des entreprises comme Meta peuvent fournir le modèle sous-jacent en open source, alors le monde pourra l’affiner pour ses propres besoins. C'est la philosophie adoptée par Meta et IBM.

L’IA open source n’est donc pas seulement une bonne idée, elle est nécessaire à la diversité culturelle et peut-être même à la préservation de la démocratie.
La formation et la mise au point se feront via le crowdsourcing ou par un écosystème de startups et d'autres entreprises.
L’un des facteurs qui stimulent la croissance de l’écosystème des startups de l’IA est la disponibilité de ces modèles d’IA open source. Combien de temps faudra-t-il pour atteindre l’intelligence artificielle générale ? Je ne sais pas, cela pourrait prendre des années, voire des décennies.

De nombreux changements ont eu lieu en cours de route et de nombreux problèmes restent encore à résoudre. Cela sera certainement plus difficile que nous le pensons. Cela ne se produit pas en un jour, mais constitue une évolution progressive et progressive.
Ce n’est donc pas qu’un jour nous découvrirons le secret de l’intelligence artificielle générale, allumerons la machine et aurons instantanément une super intelligence, et nous serons tous anéantis par la super intelligence, non, ce n’est pas le cas.
Les machines dépasseront l’intelligence humaine, mais elles seront sous contrôle car elles sont axées sur des objectifs. Nous leur fixons des objectifs et ils les atteignent. Comme beaucoup d’entre nous, nous sommes ici des leaders de l’industrie ou du monde universitaire.
Nous travaillons avec des gens plus intelligents que nous, et moi aussi. Ce n’est pas parce qu’il y a beaucoup de gens plus intelligents que moi qu’ils veulent dominer ou prendre le pouvoir, c’est juste la vérité. Bien sûr, il y a des risques derrière cela, mais je laisserai cela pour une discussion plus tard, merci beaucoup.