Dans le domaine de la génération et de la compréhension d’images d’IA, les modèles existants sont souvent confrontés au défi d’équilibrer les capacités de compréhension et de génération. Ils sont inefficaces et reposent sur un grand nombre de composants pré-entraînés. Le framework JanusFlow lancé par DeepSeek AI propose une nouvelle idée pour résoudre ce problème. L'éditeur de Downcodes vous donnera une compréhension approfondie de la manière dont JanusFlow parvient à unifier la compréhension et la génération d'images grâce à une conception architecturale innovante et obtient des résultats remarquables.
Malgré des progrès rapides dans le domaine de la génération et de la compréhension d’images basées sur l’IA, d’importants défis subsistent et entravent le développement d’une approche transparente et unifiée.
Actuellement, les modèles axés sur la compréhension des images ont tendance à ne pas générer des images de haute qualité, et vice versa. Cette architecture séparée des tâches augmente non seulement la complexité, mais limite également l'efficacité, ce qui rend difficile la gestion des tâches qui nécessitent à la fois une compréhension et une génération. De plus, de nombreux modèles existants s'appuient trop sur des modifications architecturales ou des composants pré-entraînés pour exécuter efficacement n'importe quelle fonction, ce qui entraîne des compromis en termes de performances et des défis d'intégration.
Pour résoudre ces problèmes, DeepSeek AI a lancé JanusFlow, un puissant framework d'IA conçu pour unifier la compréhension et la génération d'images. JanusFlow résout les inefficacités mentionnées précédemment en intégrant la compréhension et la génération d'images dans une architecture unifiée. Ce nouveau cadre présente une conception minimaliste qui combine des modèles de langage autorégressifs avec un flux rectifié, une approche de modélisation générative de pointe.
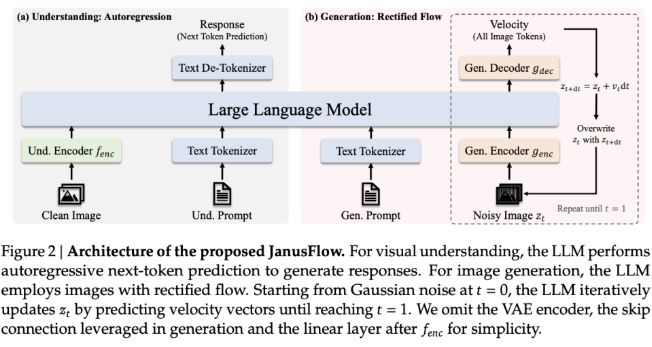
En éliminant le besoin de composants LLM et de génération séparés, JanusFlow permet une intégration fonctionnelle plus étroite tout en réduisant la complexité architecturale. Il introduit une structure double encodeur-décodeur, dissocie les tâches de compréhension et de génération et garantit la cohérence des performances dans un schéma de formation unifié en alignant les représentations.
En termes de détails techniques, JanusFlow intègre des flux correctifs et de grands modèles de langage de manière légère et efficace. L'architecture comprend des encodeurs visuels indépendants pour les tâches de compréhension et de génération. Pendant la formation, ces encodeurs sont alignés les uns avec les autres pour améliorer la cohérence sémantique, permettant au système de bien fonctionner dans les tâches de génération d'images et de compréhension visuelle.
Ce découplage des encodeurs évite les interférences entre les tâches, améliorant ainsi les capacités de chaque module. Le modèle utilise également un guidage sans classificateur (CFG) pour contrôler l'alignement entre les images générées et les conditions textuelles, améliorant ainsi la qualité de l'image. Comparé aux systèmes unifiés traditionnels qui utilisent des modèles de diffusion comme outils externes, JanusFlow offre un processus de génération plus simple et plus direct avec moins de limitations. L'efficacité de cette architecture est démontrée par sa capacité à égaler ou dépasser les performances de nombreux modèles spécifiques à des tâches sur plusieurs benchmarks.
L'importance de JanusFlow réside dans son efficacité et sa polyvalence, comblant une lacune critique dans le développement de modèles multimodaux. En éliminant le besoin de modules de génération et de compréhension indépendants, JanusFlow permet aux chercheurs et aux développeurs de tirer parti d'un cadre unique pour plusieurs tâches, réduisant ainsi considérablement la complexité et l'utilisation des ressources.
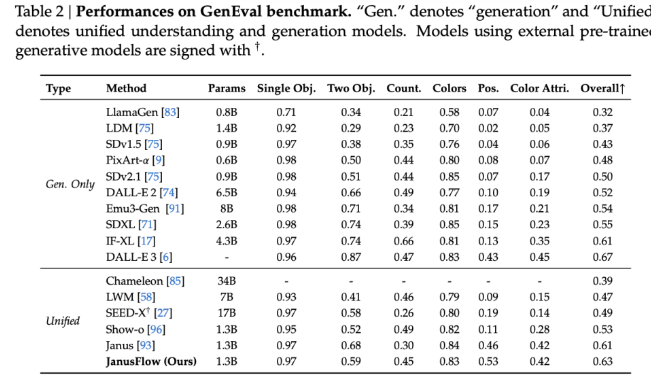
Les résultats du benchmark montrent que JanusFlow surpasse de nombreux modèles unifiés existants avec des scores de 74,9, 70,5 et 60,3 respectivement sur MMBench, SeedBench et GQA. En termes de génération d'images, JanusFlow a surpassé SDv1.5 et SDXL, avec un score de 9,51 pour MJHQ FID-30k et un score de 0,63 pour GenEval. Ces métriques démontrent son excellente capacité à générer des images de haute qualité et à gérer des tâches multimodales complexes avec seulement 1,3 milliard de paramètres.
En conclusion, JanusFlow a franchi une étape importante vers le développement d'un modèle d'IA unifié capable de comprendre et de générer simultanément des images. Son approche minimaliste, axée sur l'intégration de capacités autorégressives avec des flux correctifs, améliore non seulement les performances, mais simplifie également l'architecture du modèle, la rendant plus efficace et accessible.
En découplant l'encodeur visuel et en alignant les représentations pendant la formation, JanusFlow parvient à relier la compréhension et la génération d'images. Alors que la recherche sur l’IA continue de repousser les limites des capacités des modèles, JanusFlow représente une étape importante vers la création de systèmes d’IA multimodaux plus polyvalents et plus polyvalents.
Modèle : https://huggingface.co/deepseek-ai/JanusFlow-1.3B
Article : https://arxiv.org/abs/2411.07975
Dans l’ensemble, JanusFlow a montré un grand potentiel dans le domaine de l’IA multimodale grâce à son architecture efficace et ses excellentes performances, ouvrant la voie à une nouvelle direction pour le développement des futurs modèles d’IA. J'attends avec impatience que JanusFlow joue un rôle dans davantage de scénarios d'application !