Avec le développement rapide de la technologie de l’IA, la demande de modèles de langage visuel augmente de jour en jour, mais ses besoins élevés en ressources informatiques limitent son application sur les appareils ordinaires. L'éditeur de Downcodes vous présentera aujourd'hui un modèle de langage visuel léger appelé SmolVLM, qui peut fonctionner efficacement sur des appareils aux ressources limitées, tels que les ordinateurs portables et les GPU grand public. L'émergence de SmolVLM a donné à davantage d'utilisateurs la possibilité de découvrir une technologie avancée d'IA, a abaissé le seuil d'utilisation et a également fourni aux développeurs des outils de recherche plus pratiques.
Ces dernières années, il y a eu une demande croissante pour l’application de modèles d’apprentissage automatique aux tâches de vision et de langage, mais la plupart des modèles nécessitent d’énormes ressources informatiques et ne peuvent pas fonctionner efficacement sur des appareils personnels. Les petits appareils, notamment les ordinateurs portables, les GPU grand public et les appareils mobiles, sont confrontés à d'énormes défis lors du traitement des tâches de langage visuel.
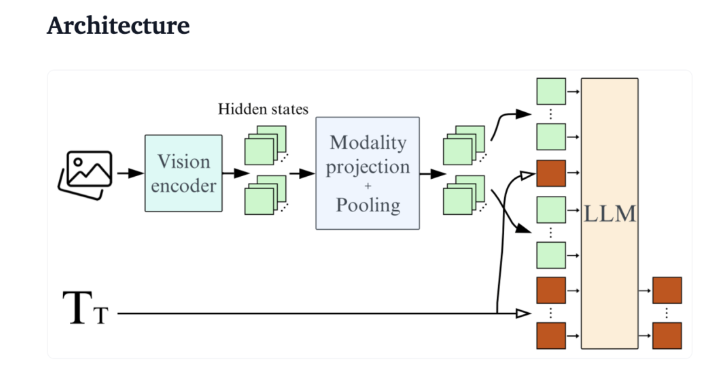
En prenant Qwen2-VL comme exemple, bien qu'il ait d'excellentes performances, il a des exigences matérielles élevées, ce qui limite sa facilité d'utilisation dans les applications en temps réel. Par conséquent, développer des modèles légers fonctionnant avec moins de ressources est devenu un besoin important.
Hugging Face a récemment publié SmolVLM, un modèle de langage visuel à paramètres 2B spécialement conçu pour le raisonnement côté appareil. SmolVLM surpasse les autres modèles similaires en termes d'utilisation de la mémoire GPU et de vitesse de génération de jetons. Sa principale caractéristique est la capacité de fonctionner efficacement sur des appareils plus petits, tels que des ordinateurs portables ou des GPU grand public, sans sacrifier les performances. SmolVLM trouve un équilibre idéal entre performances et efficacité, résolvant des problèmes difficiles à surmonter dans les modèles similaires précédents.
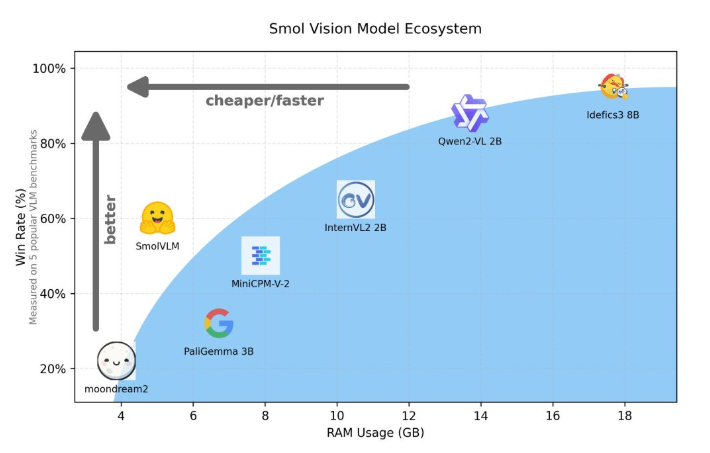
Par rapport à Qwen2-VL2B, SmolVLM génère des jetons 7,5 à 16 fois plus rapidement, grâce à son architecture optimisée, qui permet une inférence légère. Cette efficacité apporte non seulement des avantages pratiques aux utilisateurs finaux, mais améliore également considérablement l'expérience utilisateur.
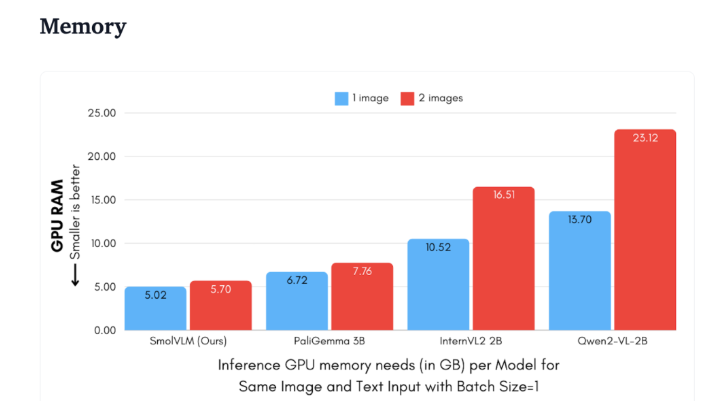
D'un point de vue technique, SmolVLM dispose d'une architecture optimisée qui prend en charge une inférence efficace côté appareil. Les utilisateurs peuvent même facilement effectuer des réglages précis sur Google Colab, abaissant considérablement le seuil d'expérimentation et de développement.
En raison de sa faible empreinte mémoire, SmolVLM est capable de fonctionner sans problème sur des appareils qui n'étaient auparavant pas en mesure d'héberger des modèles similaires. Lors du test d'une vidéo YouTube de 50 images, SmolVLM a obtenu de bons résultats, avec un score de 27,14 %, et a surpassé les deux modèles les plus gourmands en ressources en termes de consommation de ressources, démontrant sa forte adaptabilité et flexibilité.
SmolVLM constitue une étape importante dans le domaine des modèles de langage visuel. Son lancement permet d'exécuter des tâches de langage visuel complexes sur des appareils quotidiens, comblant ainsi une lacune importante dans les outils d'IA actuels.
SmolVLM excelle non seulement en termes de rapidité et d'efficacité, mais fournit également aux développeurs et aux chercheurs un outil puissant pour faciliter le traitement du langage visuel sans dépenses matérielles coûteuses. À mesure que la technologie de l’IA continue de gagner en popularité, des modèles tels que SmolVLM rendront plus accessibles les puissantes capacités d’apprentissage automatique.
démo :https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
Dans l’ensemble, SmolVLM a établi une nouvelle référence pour les modèles de langage visuel légers. Ses performances efficaces et son utilisation pratique favoriseront grandement la vulgarisation et le développement de la technologie de l’IA. Nous attendons avec impatience d’autres innovations similaires à l’avenir, permettant à la technologie de l’IA de bénéficier à un plus grand nombre de personnes.