Ces dernières années, le coût de formation des modèles de langage à grande échelle est resté élevé, ce qui est devenu un facteur limitant important au développement de l’IA. Comment réduire les coûts de formation et améliorer l’efficacité est devenu la priorité de l’industrie. L'éditeur de Downcodes vous propose une interprétation du dernier article de chercheurs de l'Université Harvard et de l'Université Stanford. Cet article propose une règle de mise à l'échelle « soucieuse de la précision » qui réduit efficacement les coûts de formation en ajustant la précision de la formation du modèle, même dans certains cas. Dans ce cas, cela peut également améliorer les performances du modèle. Examinons de plus près cette recherche passionnante.
Dans le domaine de l’intelligence artificielle, une plus grande échelle semble être synonyme de plus grandes capacités. À la recherche de modèles linguistiques plus puissants, les grandes entreprises technologiques empilent frénétiquement les paramètres des modèles et les données de formation, pour finalement constater que les coûts augmentent également. N'existe-t-il pas un moyen rentable et efficace de former des modèles linguistiques ?
Des chercheurs des universités de Harvard et de Stanford ont récemment publié un article dans lequel ils ont découvert que la précision de la formation des modèles de langage est comme une clé cachée qui peut déverrouiller le « code de coût » de la formation des modèles de langage.
Qu'est-ce que la précision du modèle ? En termes simples, elle fait référence aux paramètres du modèle et au nombre de chiffres utilisés dans le processus de calcul. Les modèles traditionnels d'apprentissage en profondeur utilisent généralement des nombres à virgule flottante de 32 bits (FP32) pour la formation, mais ces dernières années, avec le développement du matériel, des types de nombres de moindre précision sont utilisés, tels que les nombres à virgule flottante de 16 bits (FP16) ou 8- entiers binaires (INT8) La formation est déjà possible.
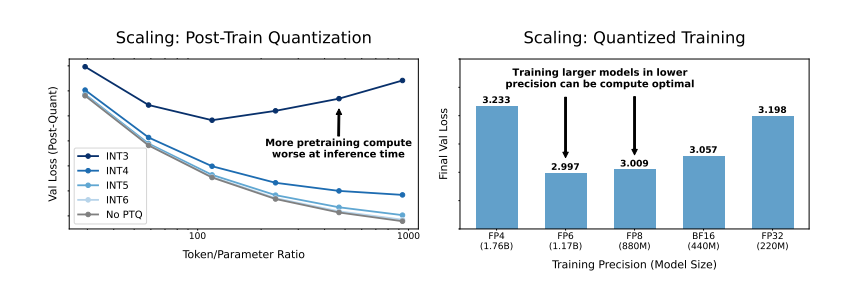
Alors, quel impact la réduction de la précision du modèle aura-t-elle sur les performances du modèle ? C’est exactement la question que cet article souhaite explorer ? Grâce à un grand nombre d'expériences, les chercheurs ont analysé les changements de coût et de performances de la formation et de l'inférence du modèle avec différentes précisions, et ont proposé un nouvel ensemble de règles de mise à l'échelle « tenant compte de la précision ».
Ils ont constaté qu'un entraînement avec une précision inférieure réduit efficacement le « nombre effectif de paramètres » du modèle, réduisant ainsi la quantité de calcul requise pour l'entraînement. Cela signifie qu'avec le même budget de calcul, nous pouvons former des modèles à plus grande échelle, ou qu'à la même échelle, en utilisant une précision inférieure, nous pouvons économiser beaucoup de ressources de calcul.
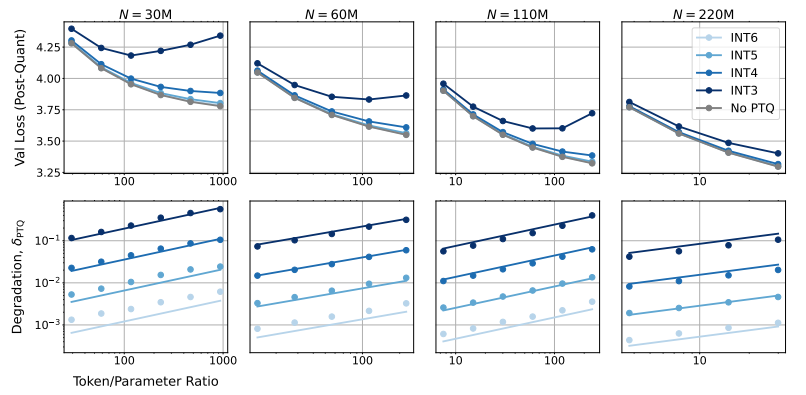
Plus surprenant encore, les chercheurs ont également découvert que dans certains cas, un entraînement avec une précision inférieure peut réellement améliorer les performances du modèle. Par exemple, pour ceux qui nécessitent une « quantification post-entraînement ». Si le modèle utilise une précision inférieure pendant la phase d'entraînement, le modèle sera plus robuste à la réduction de précision après quantification, montrant ainsi de meilleures performances lors de la phase d'inférence.
Alors, quelle précision devrions-nous choisir pour entraîner le modèle ? En analysant leurs règles de mise à l’échelle, les chercheurs sont arrivés à des conclusions intéressantes :
L’entraînement de précision traditionnel 16 bits n’est peut-être pas optimal. Leurs recherches suggèrent qu’une précision de 7 à 8 chiffres pourrait constituer une option plus rentable.
Il est également imprudent de poursuivre aveuglément un entraînement à très faible précision (comme à 4 chiffres). En effet, avec une précision extrêmement faible, le nombre de paramètres effectifs du modèle diminuera fortement. Afin de maintenir les performances, nous devons augmenter considérablement la taille du modèle, ce qui entraînera des coûts de calcul plus élevés.
La précision d'entraînement optimale peut varier pour les modèles de différentes tailles. Pour les modèles qui nécessitent beaucoup de « surentraînement », comme les séries Llama-3 et Gemma-2, un entraînement avec une plus grande précision peut être plus rentable.
Cette recherche offre une nouvelle perspective sur la compréhension et l’optimisation de la formation des modèles de langage. Cela nous indique que le choix de la précision n'est pas statique, mais doit être pondéré en fonction de la taille spécifique du modèle, du volume des données d'entraînement et des scénarios d'application.
Bien entendu, cette étude présente certaines limites. Par exemple, le modèle utilisé est à relativement petite échelle et les résultats expérimentaux peuvent ne pas être directement généralisables à des modèles à plus grande échelle. De plus, ils se sont uniquement concentrés sur la fonction de perte du modèle et n’ont pas évalué les performances du modèle sur les tâches en aval.
Néanmoins, cette recherche a encore des implications importantes. Il révèle la relation complexe entre la précision du modèle, ses performances et le coût de formation, et nous fournit des informations précieuses pour concevoir et former des modèles de langage plus puissants et plus économiques à l'avenir.
Article : https://arxiv.org/pdf/2411.04330
Dans l’ensemble, cette recherche fournit de nouvelles idées et méthodes pour réduire le coût de la formation de modèles linguistiques à grande échelle et fournit une valeur de référence importante pour le développement futur de l’IA. L'éditeur de Downcodes attend avec impatience de nouveaux progrès dans la recherche sur la précision des modèles et contribue à la création de modèles d'IA plus rentables.