Rapports de l'éditeur de downcodes : Ces dernières années, la technologie d'animation d'images audio s'est développée rapidement, mais les modèles existants présentent encore des goulots d'étranglement en termes d'efficacité et de durée. Pour résoudre ce problème, les chercheurs ont développé une nouvelle technologie appelée JoyVASA, qui améliore considérablement la qualité et l'efficacité de l'animation d'images audio grâce à une conception ingénieuse en deux étapes. JoyVASA est non seulement capable de générer des vidéos animées plus longues, mais prend également en charge l'animation faciale d'animaux et présente une bonne compatibilité multilingue, apportant de nouvelles possibilités dans le domaine de la production d'animation.
Récemment, des chercheurs ont proposé une nouvelle technologie appelée JoyVASA, qui vise à améliorer les effets d'animation d'images audio. Avec le développement continu des modèles d'apprentissage profond et de diffusion, l'animation de portraits audio a fait des progrès significatifs en termes de qualité vidéo et de précision de la synchronisation labiale. Cependant, la complexité des modèles existants augmente l'efficacité de la formation et de l'inférence, tout en limitant également la durée et la continuité inter-images des vidéos.
JoyVASA adopte une conception en deux étapes. La première étape introduit un cadre de représentation faciale découplée pour séparer les expressions faciales dynamiques des représentations faciales statiques en trois dimensions.
Cette séparation permet au système de combiner n'importe quel modèle facial 3D statique avec des séquences d'action dynamiques pour générer des vidéos animées plus longues. Dans la deuxième phase, l’équipe de recherche a formé un transformateur de diffusion capable de générer des séquences d’action directement à partir de signaux audio, un processus indépendant de l’identité du personnage. Enfin, le générateur basé sur la formation de la première étape prend en entrée la représentation faciale 3D et la séquence d'action générée pour restituer des effets d'animation de haute qualité.
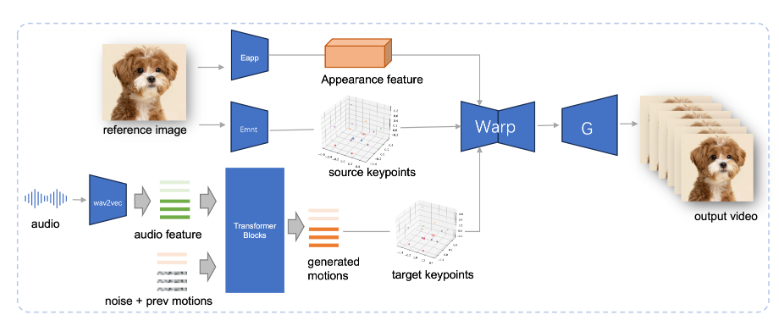
Notamment, JoyVASA ne se limite pas à l’animation de portraits humains, mais peut également animer de manière transparente des visages d’animaux. Ce modèle est formé sur un ensemble de données mixtes, combinant des données privées chinoises et des données publiques anglaises, montrant de bonnes capacités de support multilingue. Les résultats expérimentaux prouvent l'efficacité de cette méthode. Les recherches futures se concentreront sur l'amélioration des performances en temps réel et l'affinement du contrôle de l'expression afin d'étendre davantage l'application de ce cadre dans l'animation d'images.
L'émergence de JoyVASA marque une avancée importante dans la technologie d'animation audio, favorisant de nouvelles possibilités dans le domaine de l'animation.
Entrée du projet : https://jdh-algo.github.io/JoyVASA/
L'innovation de la technologie JoyVASA réside dans sa conception efficace en deux étapes et ses puissantes capacités de support multilingue, qui offrent une solution plus pratique et plus efficace pour la production d'animation. À l'avenir, avec l'amélioration continue de la technologie, JoyVASA devrait être largement utilisé dans davantage de domaines, nous apportant des œuvres d'animation plus réalistes et passionnantes. Dans l’attente de nouvelles percées technologiques et d’ouvrir un nouveau chapitre dans le développement de l’industrie de l’animation !