L'équipe de recherche en IA d'Apple a publié une nouvelle génération de grande famille de modèles de langage multimodaux MM1.5, qui peut intégrer plusieurs types de données tels que du texte et des images, et a démontré de puissantes performances dans des tâches telles que la réponse visuelle aux questions, la génération d'images et la multi- capacité d’interprétation modale des données. MM1.5 surmonte les difficultés des modèles multimodaux précédents dans le traitement d'images riches en texte et de tâches visuelles fines Grâce à une approche innovante centrée sur les données, il utilise des données OCR haute résolution et des descriptions d'images synthétiques pour améliorer considérablement les performances du modèle. . Compréhension. L'éditeur de Downcodes vous donnera une compréhension approfondie des innovations de MM1.5 et de ses excellentes performances dans plusieurs tests de référence.
Récemment, l'équipe de recherche en IA d'Apple a lancé sa nouvelle génération de famille de modèles multimodaux de grands langages (MLLM) - MM1.5. Cette série de modèles peut combiner plusieurs types de données tels que du texte et des images, nous montrant ainsi la nouvelle capacité de l'IA à comprendre des tâches complexes. Des tâches telles que la réponse visuelle aux questions, la génération d'images et l'interprétation de données multimodales peuvent toutes être mieux résolues à l'aide de ces modèles.
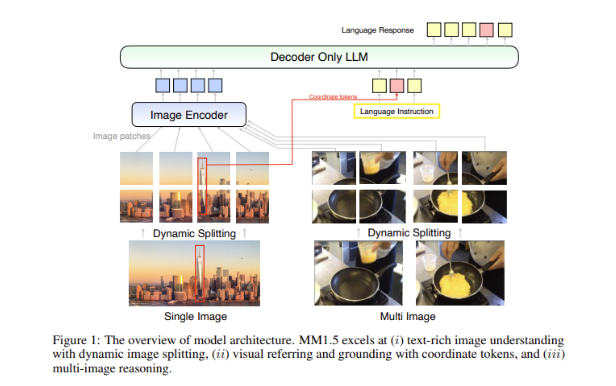
Un grand défi dans les modèles multimodaux est de savoir comment parvenir à une interaction efficace entre différents types de données. Les modèles précédents ont souvent eu du mal avec des images riches en texte ou des tâches de vision fines. Par conséquent, l’équipe de recherche d’Apple a introduit une méthode innovante centrée sur les données dans le modèle MM1.5, utilisant des données OCR haute résolution et des descriptions d’images synthétiques pour renforcer les capacités de compréhension du modèle.
Cette méthode permet non seulement à MM1.5 de surpasser les modèles précédents dans les tâches de compréhension visuelle et de positionnement, mais lance également deux versions spécialisées du modèle : MM1.5-Video et MM1.5-UI, qui sont utilisées respectivement pour la compréhension et le positionnement vidéo. . Analyse des interfaces mobiles.
La formation du modèle MM1.5 est divisée en trois étapes principales.
La première étape est une pré-formation à grande échelle, utilisant 2 milliards de paires de données image et texte, 600 millions de documents image-texte entrelacés et 2 000 milliards de jetons texte uniquement.
La deuxième étape consiste à améliorer encore les performances des tâches d'images enrichies en texte grâce à un pré-entraînement continu de 45 millions de données OCR de haute qualité et de 7 millions de descriptions synthétiques.
Enfin, lors de l'étape de réglage fin supervisée, le modèle est optimisé à l'aide de données d'image unique, multi-images et texte uniquement soigneusement sélectionnées pour l'améliorer en termes de référence visuelle détaillée et de raisonnement multi-images.
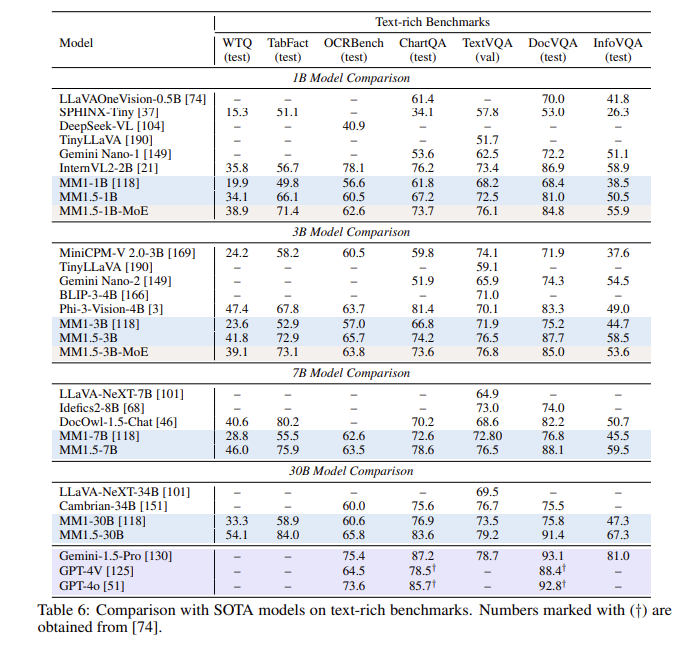
Après une série d'évaluations, le modèle MM1.5 a obtenu de bons résultats dans plusieurs tests de référence, notamment en ce qui concerne la compréhension d'images riches en texte, avec une amélioration de 1,4 point par rapport au modèle précédent. De plus, même MM1.5-Video, spécialement conçu pour la compréhension vidéo, a atteint le premier niveau dans les tâches connexes grâce à ses puissantes capacités multimodales.
La famille de modèles MM1.5 établit non seulement une nouvelle référence pour les grands modèles de langage multimodaux, mais démontre également son potentiel dans une variété d'applications, de la compréhension générale du texte image à l'analyse vidéo et de l'interface utilisateur, le tout avec des performances exceptionnelles.
Souligner:
**Variantes de modèle** : inclut des modèles denses et des modèles MoE avec des paramètres allant de 1 milliard à 30 milliards, garantissant l'évolutivité et un déploiement flexible.
? **Données de formation** : utilisant 2 milliards de paires image-texte, 600 millions de documents image-texte entrelacés et 2 000 milliards de jetons texte uniquement.
**Amélioration des performances** : lors d'un test de référence axé sur la compréhension des images riches en texte, une amélioration de 1,4 point a été obtenue par rapport au modèle précédent.
Dans l’ensemble, la famille de modèles MM1.5 d’Apple a fait des progrès significatifs dans le domaine des grands modèles de langage multimodaux, et ses méthodes innovantes et ses excellentes performances ouvrent une nouvelle direction pour le développement futur de l’IA. Nous attendons avec impatience que MM1.5 montre son potentiel dans davantage de scénarios d’application.