Ces dernières années, le modèle Transformer et son mécanisme d'attention ont fait des progrès significatifs dans le domaine des grands modèles de langage (LLM), mais le problème de la vulnérabilité aux interférences d'informations non pertinentes a toujours existé. L'éditeur de Downcodes interprétera pour vous un dernier article proposant un nouveau modèle appelé Differential Transformer (DIFF Transformer), qui vise à résoudre le problème du bruit d'attention dans le modèle Transformer et à améliorer l'efficacité et la précision du modèle. Le modèle filtre efficacement les informations non pertinentes grâce à un mécanisme d'attention différentielle innovant, permettant au modèle de se concentrer davantage sur les informations clés, obtenant ainsi des améliorations significatives dans de multiples aspects, notamment la modélisation du langage, le traitement de textes longs, la récupération d'informations clés et la réduction de l'illusion du modèle, etc. .
Les grands modèles de langage (LLM) se sont développés rapidement récemment, dans lesquels le modèle Transformer joue un rôle important. Le cœur de Transformer est le mécanisme d’attention, qui agit comme un filtre d’informations et permet au modèle de se concentrer sur les parties les plus importantes de la phrase. Mais même un transformateur puissant sera gêné par des informations non pertinentes, tout comme vous essayez de trouver un livre dans la bibliothèque, mais vous êtes submergé par une pile de livres non pertinents et l'efficacité est naturellement faible.
Les informations non pertinentes générées par ce mécanisme d’attention sont appelées bruit d’attention dans le document. Imaginez que vous souhaitiez trouver une information clé dans un fichier, mais que l'attention du modèle Transformer soit dispersée vers divers endroits non pertinents, tout comme une personne myope qui ne peut pas voir les points clés.
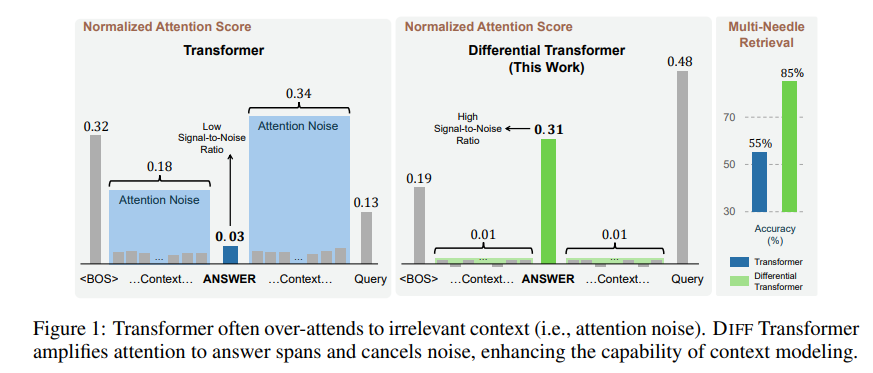
Pour résoudre ce problème, cet article propose un transformateur différentiel (transformateur DIFF). Le nom est très avancé, mais le principe est en réalité très simple. Tout comme les écouteurs antibruit, le bruit est éliminé grâce à la différence entre deux signaux.
Le cœur de Differential Transformer est le mécanisme d’attention différentielle. Il divise la requête et les vecteurs clés en deux groupes, calcule respectivement deux cartes d'attention, puis soustrait ces deux cartes pour obtenir le score d'attention final. Ce processus revient à photographier le même objet avec deux appareils photo, puis à superposer les deux photos, et les différences seront mises en évidence.
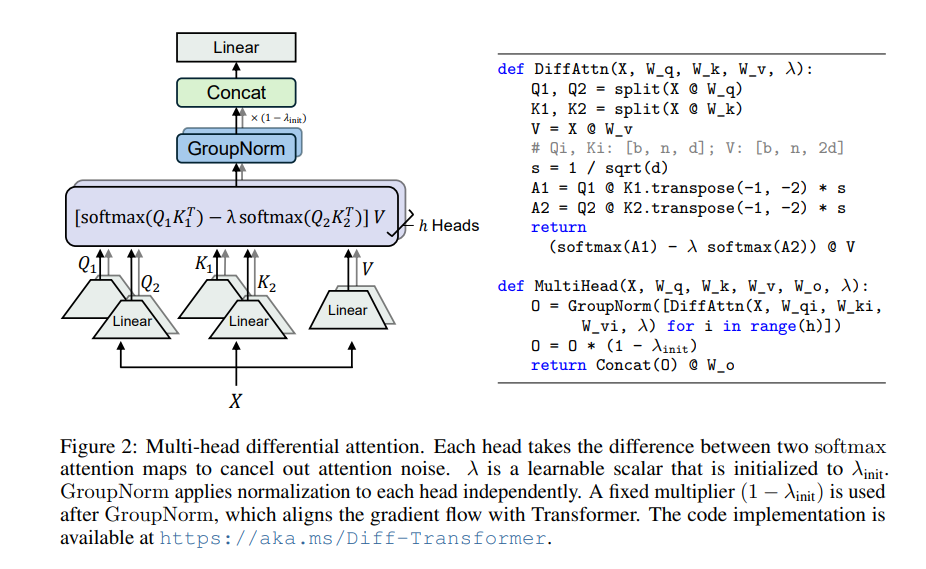
De cette façon, le transformateur différentiel peut éliminer efficacement le bruit d'attention et permettre au modèle de se concentrer davantage sur les informations clés. Tout comme lorsque vous mettez un casque antibruit, le bruit environnant disparaît et vous pouvez entendre plus clairement le son souhaité.
Une série d'expériences ont été menées dans l'article pour prouver la supériorité du transformateur différentiel. Premièrement, il fonctionne bien dans la modélisation du langage, ne nécessitant que 65 % de la taille du modèle ou des données de formation de Transformer pour obtenir des résultats similaires.
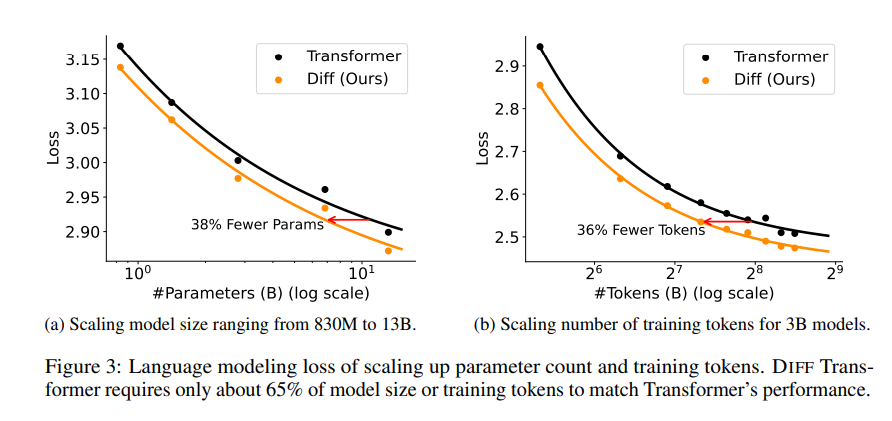
Deuxièmement, Differential Transformer est également meilleur dans la modélisation de textes longs et peut utiliser efficacement des informations contextuelles plus longues.
Plus important encore, Differential Transformer présente des avantages significatifs en matière de récupération d'informations clés, de réduction des illusions de modèle et d'apprentissage du contexte.
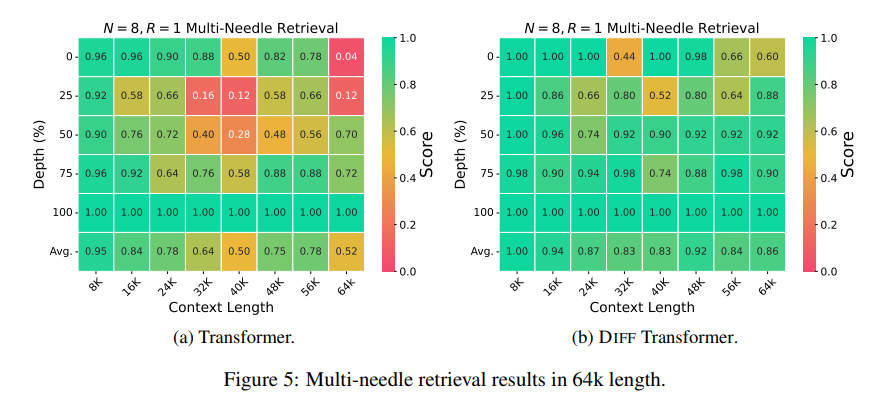
En termes de récupération d'informations clés, Differential Transformer est comme un moteur de recherche précis capable de trouver avec précision ce que vous voulez dans d'énormes quantités d'informations. Il peut maintenir une grande précision même dans des scénarios contenant des informations extrêmement complexes.
En termes de réduction des hallucinations du modèle, Differential Transformer peut efficacement éviter les « absurdités » du modèle et générer un résumé de texte et des résultats de questions et réponses plus précis et plus fiables.
En termes d'apprentissage contextuel, Differential Transformer ressemble plus à un maître de l'apprentissage, capable d'apprendre rapidement de nouvelles connaissances à partir d'un petit nombre d'échantillons, et l'effet d'apprentissage est plus stable, contrairement à Transformer, qui n'est pas facilement affecté par l'ordre des échantillons. .
De plus, le transformateur différentiel peut également réduire efficacement les valeurs aberrantes dans les valeurs d'activation du modèle, ce qui signifie qu'il est plus convivial pour modéliser la quantification et peut obtenir une quantification de bits inférieurs, améliorant ainsi l'efficacité du modèle.
Dans l'ensemble, Differential Transformer résout efficacement le problème de bruit d'attention du modèle Transformer grâce au mécanisme d'attention différentielle et réalise des améliorations significatives dans de multiples aspects. Il fournit de nouvelles idées pour le développement de grands modèles de langage et jouera un rôle important dans davantage de domaines à l'avenir.
Adresse papier : https://arxiv.org/pdf/2410.05258
Dans l'ensemble, Differential Transformer fournit une méthode efficace pour résoudre le problème de bruit d'attention du modèle Transformer. Ses excellentes performances dans plusieurs domaines indiquent sa position importante dans le développement de grands modèles de langage à l'avenir. L'éditeur de Downcodes recommande aux lecteurs de lire l'article complet pour acquérir une compréhension approfondie de ses détails techniques et de ses perspectives d'application. Nous attendons avec impatience que Differential Transformer apporte d’autres avancées dans le domaine de l’intelligence artificielle !