Apple a publié une mise à niveau majeure de son modèle d'intelligence artificielle multimodale MM1 - MM1.5. Cette mise à niveau n'est pas une simple itération de version, mais une amélioration globale des capacités du modèle, améliorant considérablement ses performances en matière de compréhension d'image, de reconnaissance de texte et d'exécution de commandes visuelles. L'éditeur de Downcodes expliquera en détail les améliorations de MM1.5 et son importance dans le domaine de l'intelligence artificielle multimodale.
Apple a récemment lancé une mise à jour majeure de son modèle d'intelligence artificielle multimodale MM1, en le mettant à niveau vers la version MM1.5. Cette mise à niveau n'est pas simplement un simple changement de numéro de version, mais une amélioration complète des capacités, permettant au modèle d'afficher des performances plus puissantes dans divers domaines.
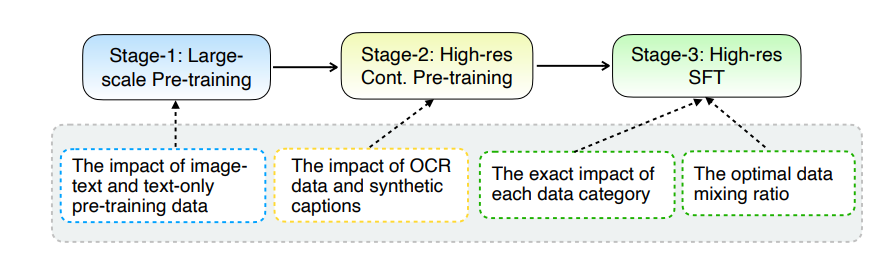
La principale mise à niveau de MM1.5 réside dans sa méthode innovante de traitement des données. Le modèle adopte une approche de formation centrée sur les données, et l'ensemble de données de formation est soigneusement sélectionné et optimisé. Plus précisément, MM1.5 utilise des données OCR haute définition et des descriptions d'images synthétiques, ainsi que des instructions visuelles optimisées pour affiner le mélange de données. L'introduction de ces données a considérablement amélioré les performances du modèle en matière de reconnaissance de texte, de compréhension d'images et d'exécution d'instructions visuelles.

En termes de taille de modèle, MM1.5 couvre plusieurs versions allant de 1 milliard à 30 milliards de paramètres, y compris les variantes intensives et mixtes d'experts (MoE). Il convient de noter que même des modèles à plus petite échelle de 1 milliard et 3 milliards de paramètres peuvent atteindre des niveaux de performances impressionnants avec des données et des stratégies de formation soigneusement conçues.
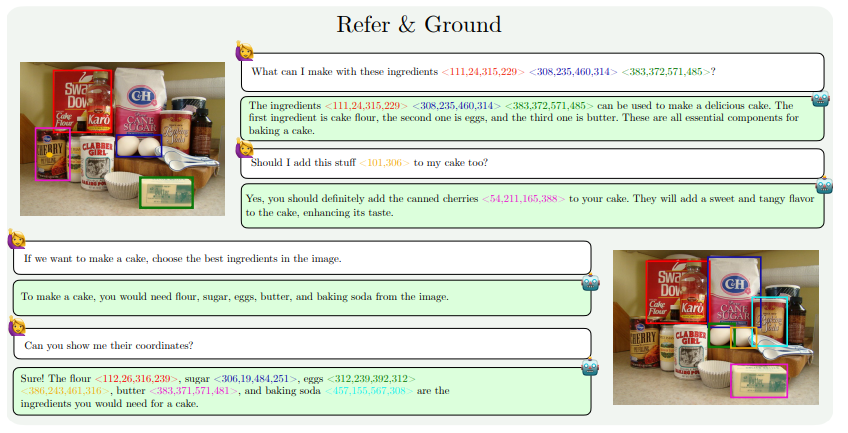
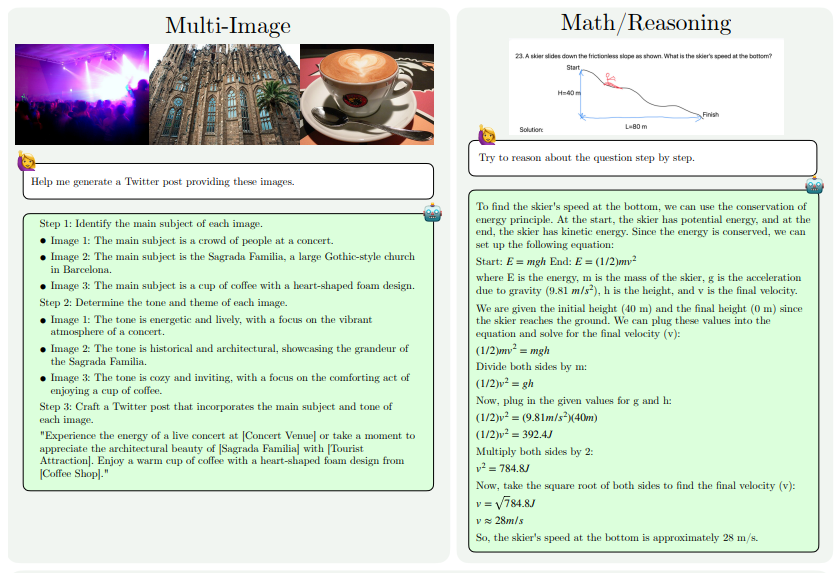
Les améliorations des capacités de MM1.5 se reflètent principalement dans les aspects suivants : compréhension des images à forte teneur en texte, référence visuelle et positionnement, raisonnement multi-images, compréhension vidéo et compréhension de l'interface utilisateur mobile. Ces capacités permettent d'appliquer MM1.5 à un plus large éventail de scénarios, tels que l'identification d'artistes et d'instruments à partir de photos de concert, la compréhension des données graphiques et la réponse à des questions connexes, la localisation d'objets spécifiques dans des scènes complexes, etc.
Pour évaluer les performances de MM1.5, les chercheurs l'ont comparé à d'autres modèles multimodaux avancés. Les résultats montrent que MM1.5-1B fonctionne bien dans un modèle avec une échelle de 1 milliard de paramètres, nettement mieux que les autres modèles du même niveau. MM1.5-3B surpasse MiniCPM-V2.0 et est à égalité avec InternVL2 et Phi-3-Vision. En outre, l’étude a également révélé que, qu’il s’agisse d’un modèle dense ou d’un modèle MoE, les performances s’amélioreront considérablement à mesure que l’échelle augmentera.
Le succès de MM1.5 reflète non seulement la force de recherche et développement d’Apple dans le domaine de l’intelligence artificielle, mais ouvre également la voie au développement futur de modèles multimodaux. En optimisant les méthodes de traitement des données et l'architecture des modèles, même les modèles à plus petite échelle peuvent atteindre de fortes performances, ce qui est d'une grande importance pour le déploiement de modèles d'IA hautes performances sur des appareils aux ressources limitées.
Adresse papier : https://arxiv.org/pdf/2409.20566
Dans l’ensemble, la sortie de MM1.5 marque une avancée significative dans la technologie de l’intelligence artificielle multimodale. Ses innovations en matière de traitement des données et d’architecture de modèles fournissent de nouvelles idées et orientations pour le développement des futurs modèles d’IA. Nous espérons qu’Apple continuera à apporter des résultats encore plus révolutionnaires dans le domaine de l’intelligence artificielle.