L'éditeur de Downcodes a appris que des équipes de recherche de l'Illinois Institute of Technology et d'autres universités ont publié conjointement Robin3D, un nouveau grand modèle de langage de scène 3D. Le modèle a été formé sur un ensemble de données massif contenant des millions d’instructions et a atteint des performances de pointe sur cinq benchmarks d’apprentissage multimodal 3D couramment utilisés. L'innovation de Robin3D réside dans son moteur de données RIG, qui peut générer des données d'instructions contradictoires et diversifiées, améliorant ainsi les capacités de discrimination, de compréhension et de généralisation du modèle, surmontant les capacités de généralisation insuffisantes et les problèmes de surajustement du modèle de langage 3D existant. Il intègre également des technologies telles que le projecteur d'augmentation des relations (RAP) et l'identification des fonctionnalités (IFB) pour améliorer la compréhension des scènes et des objets par le modèle.
Le modèle a été formé sur un ensemble de données à grande échelle contenant un million d'instructions à suivre et a atteint des performances de pointe sur cinq benchmarks d'apprentissage multimodal 3D couramment utilisés, marquant une étape importante dans la construction d'une 3D universelle. en direction d'agents intelligents.
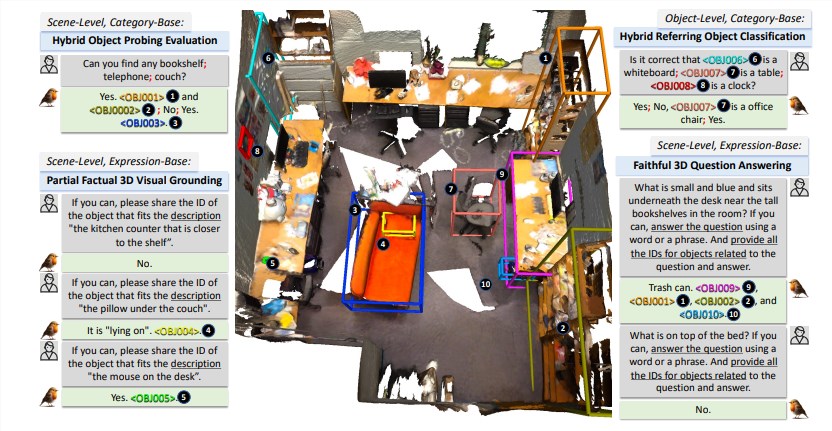
Le succès de Robin3D est dû à son moteur de données innovant RIG (Robust Instruction Generation). Le moteur RIG est conçu pour générer deux types de données de commandes clés : les données de conformité des commandes contradictoires et diverses données de conformité des commandes.
Les données de suivi contradictoires améliorent la compréhension discriminante du modèle en mélangeant des échantillons positifs et négatifs, tandis que diverses données de suivi contiennent divers styles d'instructions pour améliorer la capacité de généralisation du modèle.
Les chercheurs ont souligné que les grands modèles de langage 3D existants reposent principalement sur des paires de langages visuels 3D frontaux et des instructions basées sur des modèles pour la formation, ce qui conduit à des capacités de généralisation insuffisantes et à un risque de surapprentissage. Robin3D surmonte efficacement ces limitations en introduisant des données d'instructions contradictoires et diverses.
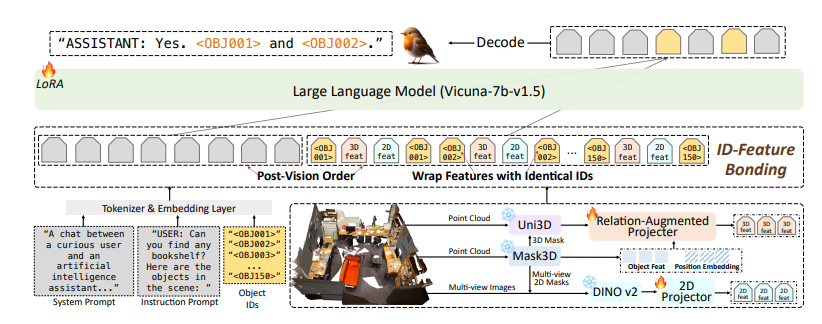
Le modèle Robin3D intègre également des capacités de référencement et de positionnement de liaison de caractéristiques d'identification (IFB) de projecteur augmenté de relation (RAP). Le module RAP améliore les fonctionnalités centrées sur les objets avec de riches informations contextuelles et de localisation au niveau de la scène, tandis que le module IFB renforce les connexions entre chaque ID en les liant à ses fonctionnalités correspondantes.
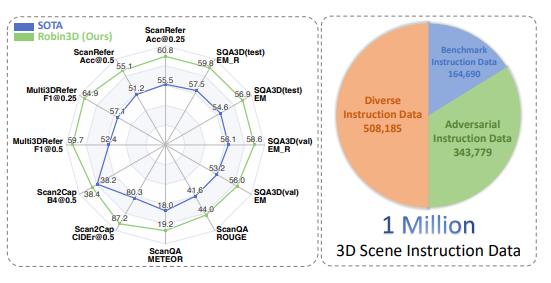
Les résultats expérimentaux montrent que Robin3D surpasse les meilleures méthodes précédentes sur cinq benchmarks, notamment ScanRefer, Multi3DRefer, Scan2Cap, ScanQA et SQA3D, sans qu'il soit nécessaire d'affiner des tâches spécifiques.
Surtout dans l'évaluation Multi3DRefer incluant le cas zéro cible, Robin3D a obtenu des améliorations significatives de 7,8 % et 7,3 % dans les indicateurs F1@0,25 et F1@0,5 respectivement.
La sortie de Robin3D marque un progrès significatif dans l'intelligence spatiale des grands modèles de langage 3D, jetant ainsi une base solide pour la création d'agents 3D plus polyvalents et plus puissants à l'avenir.
Adresse papier : https://arxiv.org/pdf/2410.00255
L'émergence de Robin3D a sans aucun doute apporté de nouvelles avancées dans les domaines de la vision 3D et de l'intelligence artificielle. Ses performances puissantes et ses vastes perspectives d'application méritent d'être attendues. Je crois qu'à l'avenir, Robin3D jouera un rôle dans davantage de domaines et favorisera le développement rapide de l'intelligence 3D. L'éditeur de Downcodes continuera à être attentif aux dernières évolutions dans ce domaine.