L'éditeur de Downcodes a appris qu'une étude révolutionnaire de l'Université de Yale a révélé le secret de la formation des modèles d'IA : la complexité des données n'est pas plus élevée, mieux c'est, mais il existe un état optimal de « bord du chaos ». L'équipe de recherche a intelligemment utilisé le modèle d'automate cellulaire pour mener des expériences, a exploré l'impact de données de complexité différente sur l'effet d'apprentissage du modèle d'IA et est parvenue à des conclusions accrocheuses.
Une équipe de recherche de l'Université de Yale a récemment publié un résultat de recherche révolutionnaire, révélant une découverte clé dans la formation des modèles d'IA : les données ayant le meilleur effet d'apprentissage de l'IA ne sont ni plus simples ni plus complexes, mais il existe un niveau de complexité optimal - un état connu sous le nom de bord du chaos.
L'équipe de recherche a mené des expériences en utilisant des automates cellulaires élémentaires (ECA), qui sont des systèmes simples dans lesquels l'état futur de chaque unité dépend uniquement d'elle-même et des états de deux unités adjacentes. Malgré la simplicité des règles, de tels systèmes peuvent produire des modèles variés allant du plus simple au plus complexe. Les chercheurs ont ensuite évalué les performances de ces modèles de langage sur des tâches de raisonnement et de prédiction de coups d’échecs.
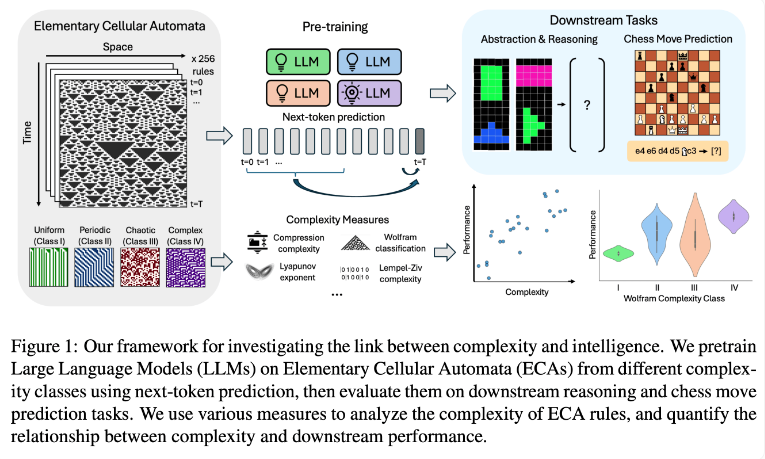
Les résultats de la recherche montrent que les modèles d'IA formés sur des règles ECA plus complexes fonctionnent mieux dans les tâches ultérieures. En particulier, les modèles formés sur des ECA de classe IV dans la classification Wolfram ont montré les meilleures performances. Les modèles générés par de telles règles ne sont ni complètement ordonnés ni complètement chaotiques, mais présentent plutôt une complexité structurée.
Les chercheurs ont découvert que lorsque les modèles étaient exposés à des modèles trop simples, ils n’apprenaient souvent que des solutions simples. En revanche, les modèles formés sur des modèles plus complexes développent des capacités de traitement plus sophistiquées, même lorsque des solutions simples sont disponibles. L'équipe de recherche suppose que la complexité de cette représentation apprise est un facteur clé dans la capacité du modèle à transférer des connaissances vers d'autres tâches.
Cette découverte peut expliquer pourquoi les grands modèles de langage tels que GPT-3 et GPT-4 sont si efficaces. Les chercheurs pensent que les données massives et diverses utilisées dans la formation de ces modèles pourraient avoir créé des effets similaires aux modèles complexes d’ECA dans leur étude.
Cette recherche fournit de nouvelles idées pour la formation de modèles d’IA et une nouvelle perspective pour comprendre les puissantes capacités des grands modèles de langage. À l’avenir, nous pourrons peut-être améliorer encore les performances et les capacités de généralisation des modèles d’IA en contrôlant plus précisément la complexité des données d’entraînement. L'éditeur de Downcodes estime que les résultats de cette recherche auront un impact profond sur le domaine de l'intelligence artificielle.