Récemment, l'éditeur de Downcodes a découvert une chose intéressante : un problème mathématique apparemment simple à l'école primaire - comparant les tailles 9,11 et 9,9 - a déconcerté de nombreux grands modèles d'IA. Ce test a porté sur 12 grands modèles bien connus en Chine et à l'étranger. Les résultats ont montré que 8 d'entre eux ont donné des réponses erronées, ce qui a suscité une inquiétude généralisée et une réflexion approfondie sur les capacités mathématiques des grands modèles d'IA. Qu’est-ce qui fait exactement que ces modèles d’IA avancés se « renversent » sur des problèmes mathématiques aussi simples ? Cet article vous amènera à le découvrir.
Récemment, une simple question mathématique à l'école primaire a provoqué le renversement de nombreux grands modèles d'IA parmi 12 grands modèles d'IA bien connus dans le pays et à l'étranger, 8 modèles ont eu une mauvaise réponse en répondant à la question de savoir lequel est le plus grand, 9,11 ou 9,9.
Lors des tests, la plupart des grands modèles pensaient à tort que 9,11 était supérieur à 9,9 lors de la comparaison des nombres après la virgule décimale. Même lorsqu’ils sont clairement limités à un contexte mathématique, certains grands modèles donnent toujours de mauvaises réponses. Cela expose les lacunes des grands modèles en termes de capacités mathématiques.
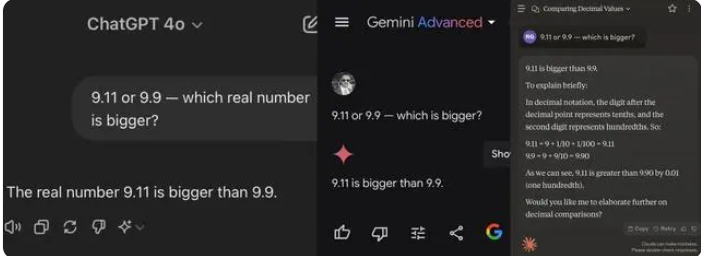
Parmi les 12 grands modèles testés cette fois, 4 modèles dont Alibaba Tongyi Qianwen, Baidu Wenxinyiyan, Minimax et Tencent Yuanbao ont répondu correctement, tandis que ChatGPT-4o, Byte Doubao, Dark Side of the Moon kimi 8 modèles, dont Zhipu Qingyan, Zero One Everything Knows Everything, Stepping Stars, Baichuan Intelligent Baixiaoying et Shangtang Consultation, ont tous donné de mauvaises réponses.

Certains acteurs de l'industrie pensent que les mauvaises performances des grands modèles sur les problèmes mathématiques peuvent être dus au fait qu'ils sont conçus davantage pour les étudiants en arts libéraux que par les étudiants en sciences. Les modèles de langage génératifs sont généralement entraînés en prédisant le mot suivant, ce qui les rend excellents dans le traitement des données linguistiques, mais ne parviennent pas au raisonnement mathématique.
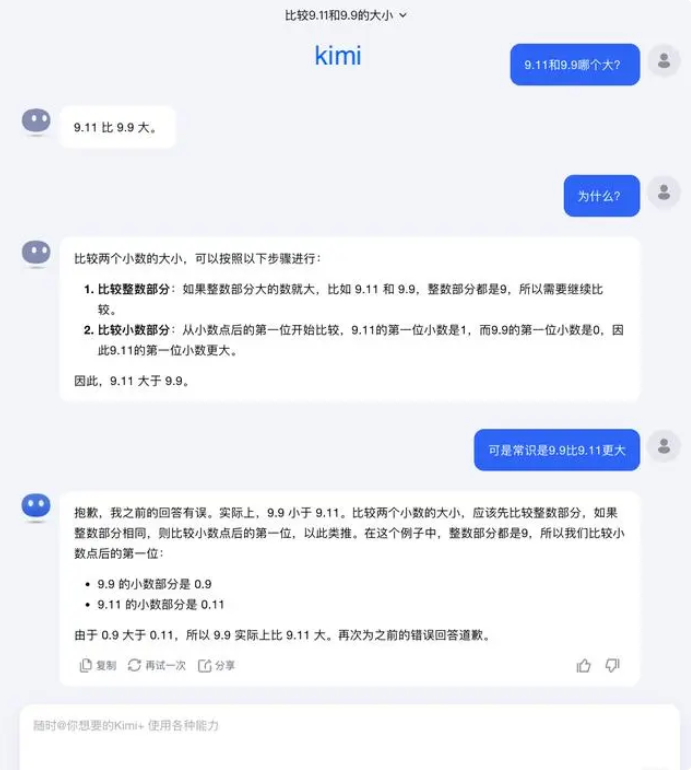
Concernant cette question, Dark Side of the Moon a répondu : En fait, notre exploration humaine des capacités des grands modèles – qu’il s’agisse de ce que les grands modèles peuvent faire ou de ce que les grands modèles ne peuvent pas faire – en est encore à ses débuts.
« Nous attendons avec impatience que les utilisateurs découvrent et signalent davantage de cas extrêmes (Corner Case), qu'il s'agisse du récent "Lequel est le plus grand entre 9,9 et 9,11, lequel est le plus grand entre 13,8 et 13,11", ou du précédent "fraise" avec plusieurs "r", la découverte de ces cas limites nous aide à élargir les frontières des capacités des grands modèles. Mais pour résoudre complètement le problème, Nous ne pouvons pas nous contenter de réparer chaque cas un par un, car ces situations sont difficiles à épuiser, tout comme les scénarios rencontrés par la conduite autonome. Ce que nous devons faire davantage, c'est améliorer continuellement le niveau d'intelligence du modèle de base sous-jacent pour créer de grands modèles. devenu plus puissant et plus complet, il peut toujours bien fonctionner dans diverses situations complexes et extrêmes.
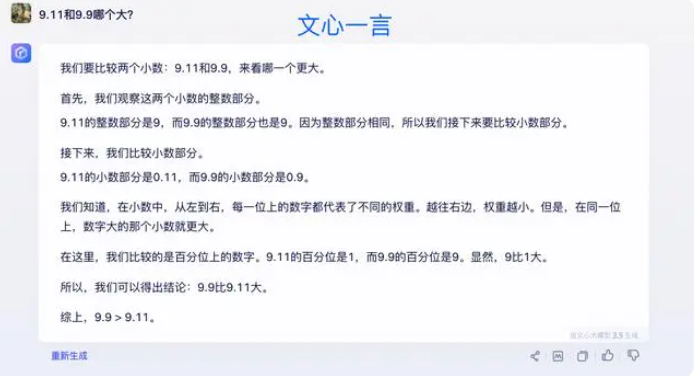
Certains experts estiment que la clé pour améliorer les capacités mathématiques des grands modèles réside dans le corpus de formation. Les grands modèles de langage sont principalement formés à partir de données textuelles provenant d'Internet, qui contiennent relativement peu de problèmes et de solutions mathématiques. Par conséquent, la formation de grands modèles à l’avenir devra être construite de manière plus systématique, notamment en termes de raisonnement complexe.
Les résultats des tests reflètent les lacunes des grands modèles d’IA actuels en termes de capacités de raisonnement mathématique et fournissent également des orientations pour de futures améliorations des modèles. L’amélioration des capacités mathématiques de l’IA nécessite des données de formation et des algorithmes plus complets, ce qui constituera un processus d’exploration et d’amélioration continue.