Récemment, une question de comparaison mathématique apparemment simple : « Lequel est le plus grand, 13,8 ou 13,11 ? » a déconcerté de nombreuses personnes, y compris certains modèles d'IA avancés. L'éditeur de Downcodes vous amènera à approfondir cet incident, à analyser les lacunes de l'IA dans la gestion des problèmes de bon sens et les orientations des améliorations futures. Cela révèle non seulement les limites de la technologie de l’IA, mais suscite également une réflexion sur le développement futur de l’IA.
Récemment, une simple question mathématique – laquelle est la plus grande, 13,8 ou 13,11 ? – a non seulement déconcerté certains humains, mais a également mis en difficulté de nombreux grands modèles de langage (LLM). Cette question a suscité de nombreux débats sur la capacité de l’IA à résoudre des problèmes de bon sens.
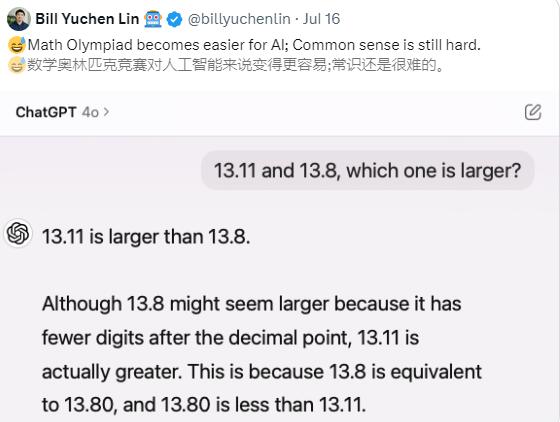
Dans une émission de variétés bien connue, cette question a déclenché de vives discussions parmi les internautes. Beaucoup de gens pensent que 13,11 % devrait être supérieur à 13,8 %, mais en fait, 13,8 % est supérieur.
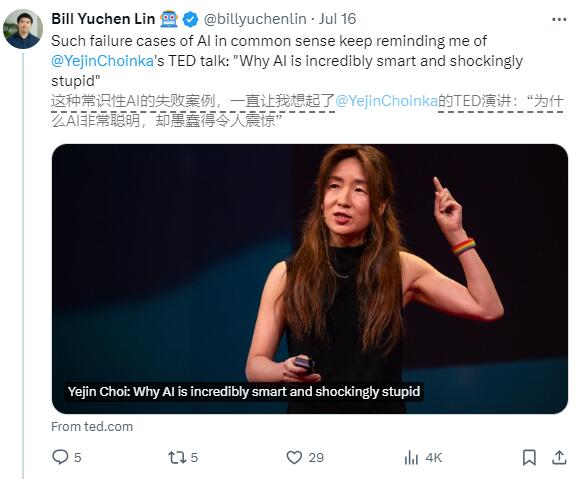
Le chercheur d'AI2, Lin Yuchen, a découvert que même les grands modèles de langage, tels que GPT-4o, commettent des erreurs sur ce simple problème de comparaison. GPT-4o a cru à tort que 13,11 était supérieur à 13,8 et a donné une explication erronée.
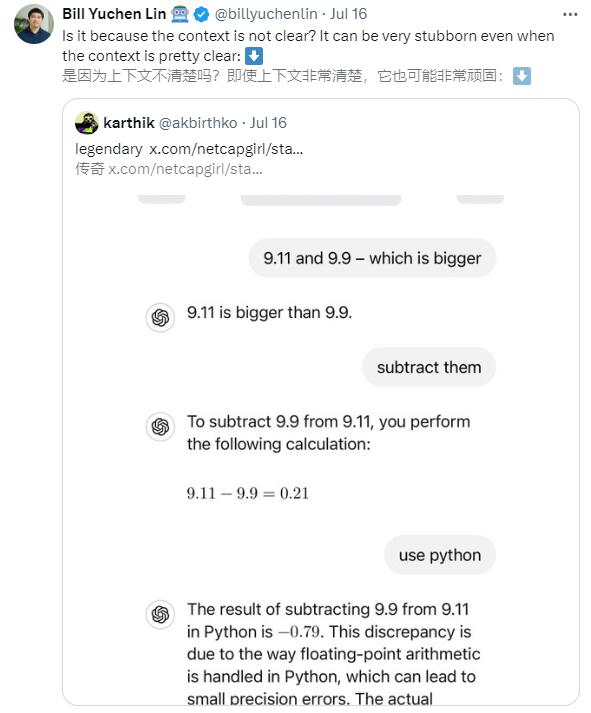
La découverte de Lin Yuchen a rapidement suscité de vives discussions au sein de la communauté de l'IA. De nombreux autres grands modèles de langage, tels que Gemini, Claude3.5Sonnet, etc., font également la même erreur sur ce simple problème de comparaison.
L’émergence de cette problématique révèle les difficultés que peut rencontrer l’IA face à des tâches qui paraissent simples mais qui impliquent en réalité des comparaisons numériques précises.
Bien que l’intelligence artificielle ait fait des progrès significatifs dans de nombreux domaines, tels que la compréhension du langage naturel, la reconnaissance d’images et la prise de décision complexe, elle peut encore commettre des erreurs lorsqu’il s’agit d’opérations mathématiques de base et de raisonnement logique, montrant ainsi les limites de la technologie actuelle.
Pourquoi l’IA commet-elle de telles erreurs ?
Biais dans les données d'entraînement : les données d'entraînement pour le modèle d'IA peuvent ne pas contenir suffisamment d'exemples pour traiter correctement ce type spécifique de problème de comparaison numérique. Si le modèle est exposé à des données pendant l'entraînement qui indiquent principalement que les nombres plus grands ont toujours plus de décimales, il peut interpréter de manière incorrecte plus de décimales comme des valeurs plus grandes.
Problèmes de précision en virgule flottante : En informatique, la représentation et le calcul de nombres à virgule flottante impliquent des problèmes de précision. Même de petites différences peuvent entraîner des résultats erronés lors de la comparaison, surtout si la précision n'est pas explicitement spécifiée.
Compréhension contextuelle insuffisante : même si la clarté contextuelle ne constitue pas un problème majeur dans ce cas, les modèles d'IA doivent souvent interpréter correctement les informations en fonction du contexte. Des malentendus peuvent survenir si la question est formulée d'une manière qui n'est pas suffisamment claire ou ne correspond pas aux modèles communs à l'IA dans les données d'entraînement.
Impact de la conception rapide : la manière dont vous posez des questions à une IA est essentielle pour obtenir la bonne réponse. Différentes méthodes de questionnement peuvent affecter la compréhension et l’exactitude des réponses de l’IA.
Comment s'améliorer ?
Données d'entraînement améliorées : en fournissant des données d'entraînement plus diverses et plus précises, les modèles d'IA peuvent être aidés à mieux comprendre les comparaisons numériques et d'autres concepts mathématiques de base.
Optimiser la conception des invites : une formulation de problème bien conçue peut augmenter les chances que l’IA donne la bonne réponse. Par exemple, l’utilisation de représentations numériques et de méthodes de questionnement plus explicites peut réduire l’ambiguïté.
Améliorer la précision du traitement numérique : développer et adopter des algorithmes et des techniques qui gèrent plus précisément les opérations en virgule flottante afin de réduire les erreurs de calcul.
Capacités de raisonnement logique et de bon sens améliorées : Grâce à une formation spécifiquement axée sur le raisonnement logique et de bon sens, les capacités de l’IA dans ces domaines sont améliorées, lui permettant de mieux comprendre et gérer les tâches liées au bon sens.
Dans l’ensemble, les défauts révélés par l’IA dans le traitement de simples problèmes de comparaison mathématique nous rappellent que la technologie de l’IA est encore en phase de développement et nécessite une amélioration continue. À l’avenir, en optimisant les données d’entraînement, en améliorant les algorithmes et en renforçant les capacités de raisonnement logique, l’IA progressera davantage dans la gestion des problèmes de bon sens.