L’intelligence artificielle a fait des progrès significatifs dans la reconnaissance d’images ces dernières années, mais la compréhension vidéo reste un défi de taille. La dynamique et la complexité des données vidéo posent des difficultés sans précédent à l’IA. Cependant, l'encodeur vidéo VideoPrism développé par l'équipe de recherche de Google devrait changer cette situation. L'éditeur de Downcodes vous donnera une compréhension approfondie des fonctions puissantes de VideoPrism, des méthodes de formation et de son impact profond sur le futur domaine de la compréhension vidéo de l'IA.
Dans le monde de l’IA, il est beaucoup plus difficile pour les machines de comprendre des vidéos que des images. La vidéo est dynamique, avec du son, du mouvement et un tas de scènes complexes. Dans le passé, avec l’IA, regarder des vidéos revenait à lire un livre tombé du ciel, et on était souvent confus.
Mais l’émergence de VideoPrism pourrait tout changer. Il s'agit d'un encodeur vidéo développé par l'équipe de recherche de Google. Il peut atteindre le niveau de pointe avec un modèle unique pour une variété de tâches de compréhension vidéo. Qu'il s'agisse de classer des vidéos, de les positionner, de générer des sous-titres ou même de répondre à des questions sur les vidéos, VideoPrism peut le gérer facilement.

Comment entraîner VideoPrism ?
Le processus de formation de VideoPrism revient à apprendre à un enfant à observer le monde. Tout d’abord, il faut lui montrer une variété de vidéos, allant de la vie quotidienne aux observations scientifiques. Ensuite, vous l'entraînez également avec des paires vidéo-sous-titres de « haute qualité » et du texte parallèle bruyant (tel qu'un texte de reconnaissance vocale automatique).
Méthode de pré-formation
Données : VideoPrism utilise 36 millions de paires vidéo-sous-titres de haute qualité et 58,2 millions de clips vidéo avec du texte parallèle bruité.
Architecture du modèle : basée sur le transformateur visuel standard (ViT), utilisant une conception factorisée dans l'espace et le temps.
Algorithme de formation : comprend deux étapes : formation par comparaison vidéo-texte et modélisation vidéo masquée.
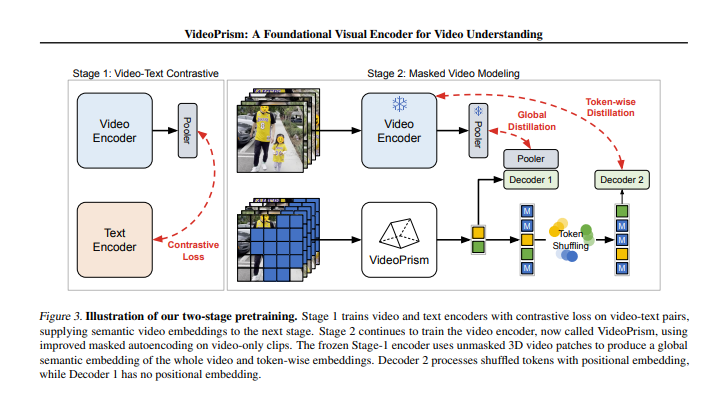
Au cours du processus de formation, VideoPrism passera par deux étapes. Dans un premier temps, il apprend le lien entre la vidéo et le texte grâce à un apprentissage contrastif et une distillation global-local. Dans un deuxième temps, il améliore encore la compréhension du contenu vidéo grâce à une modélisation vidéo masquée.
Les chercheurs ont testé VideoPrism sur plusieurs tâches de compréhension vidéo et les résultats ont été impressionnants. VideoPrism atteint des performances de pointe sur 30 des 33 benchmarks. Qu'il s'agisse de répondre à des questions vidéo en ligne ou à des tâches de vision par ordinateur dans le domaine scientifique, VideoPrism a démontré de solides capacités.
La naissance de VideoPrism a apporté de nouvelles possibilités dans le domaine de la compréhension vidéo de l'IA. Non seulement cela peut aider l’IA à mieux comprendre le contenu vidéo, mais cela peut également jouer un rôle important dans l’éducation, le divertissement, la sécurité et d’autres domaines.
Mais VideoPrism est également confronté à certains défis, tels que la manière de gérer de longues vidéos et d'éviter d'introduire des préjugés pendant le processus de formation. Ce sont des questions qui doivent être abordées dans les recherches futures.
Adresse papier : https://arxiv.org/pdf/2402.13217
Dans l’ensemble, l’émergence de VideoPrism marque un progrès majeur dans le domaine de la compréhension de la vidéo IA. Ses performances puissantes et ses vastes perspectives d’application sont passionnantes. À l'avenir, avec le développement continu de la technologie, je pense que VideoPrism montrera sa valeur dans davantage de domaines et apportera plus de commodité à la vie des gens.