La formation à l'intelligence artificielle prend du temps et consomme de la puissance de calcul, ce qui a toujours été un goulot d'étranglement dans le domaine de l'IA. L'équipe DeepMind a récemment publié une étude révolutionnaire et proposé une nouvelle méthode de filtrage des données appelée JEST, qui résout efficacement ce problème. L'éditeur de Downcodes vous donnera une compréhension approfondie de la façon dont JEST peut améliorer considérablement l'efficacité de la formation en IA et expliquera les principes techniques qui la sous-tendent.
Dans le domaine de l’intelligence artificielle, la puissance de calcul et le temps ont toujours été des facteurs clés limitant le progrès technologique. Cependant, les derniers résultats de recherche de l’équipe DeepMind apportent une solution à ce problème.
Ils ont proposé une nouvelle méthode de filtrage des données appelée JEST, qui permet de réduire considérablement le temps de formation de l'IA et les besoins en puissance de calcul en sélectionnant intelligemment les meilleurs lots de données pour la formation. On dit qu'il peut réduire le temps de formation de l'IA de 13 fois et réduire les besoins en puissance de calcul de 90 %.
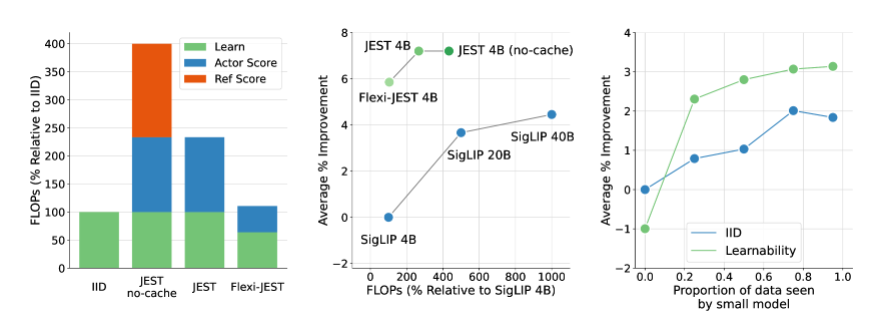
Le cœur de la méthode JEST réside dans la sélection conjointe des meilleurs lots de données plutôt que d’échantillons individuels, une stratégie qui s’est avérée particulièrement efficace pour accélérer l’apprentissage multimodal. Par rapport aux méthodes traditionnelles de filtrage de données de pré-entraînement à grande échelle, JEST réduit non seulement considérablement le nombre d'itérations et d'opérations en virgule flottante, mais surpasse également l'état de l'art précédent en n'utilisant que 10 % du budget FLOP.
Les recherches de l'équipe DeepMind ont révélé trois points clés : la sélection de bons lots de données est plus efficace que la sélection de points de données individuellement, les approximations de modèles en ligne peuvent être utilisées pour filtrer les données plus efficacement, et de petits ensembles de données de haute qualité peuvent être amorcés pour tirer parti des plus grands. . Ensemble de données non organisé. Ces résultats fournissent une base théorique pour la performance efficace de la méthode JEST.
Le principe de fonctionnement de JEST est d'évaluer la capacité d'apprentissage des points de données en s'appuyant sur des recherches antérieures sur la perte de RHO et en combinant la perte du modèle d'apprentissage et du modèle de référence pré-entraîné. Il sélectionne les points de données qui sont plus faciles pour le modèle pré-entraîné mais plus difficiles pour le modèle d'apprentissage actuel afin d'améliorer l'efficience et l'efficacité de la formation.
De plus, JEST adopte également une méthode itérative basée sur le blocage de l'échantillonnage de Gibbs pour créer progressivement des lots et sélectionner un nouveau sous-ensemble d'échantillons en fonction du score d'apprentissage conditionnel à chaque itération. Cette approche continue de s'améliorer à mesure que davantage de données sont filtrées, notamment en utilisant uniquement des modèles de référence pré-entraînés pour évaluer les données.
Cette recherche de DeepMind apporte non seulement des progrès révolutionnaires dans le domaine de la formation en IA, mais fournit également de nouvelles idées et méthodes pour le développement futur de la technologie de l'IA. Avec la poursuite de l’optimisation et de l’application de la méthode JEST, nous avons des raisons de croire que le développement de l’intelligence artificielle ouvrira la voie à des perspectives plus larges.
Article : https://arxiv.org/abs/2406.17711
Souligner:
**Révolution de l'efficacité de la formation** : la méthode JEST de DeepMind réduit le temps de formation de l'IA de 13 fois et réduit les besoins en puissance de calcul de 90 %.
**Criblage de lots de données** : JEST améliore considérablement l'efficacité de l'apprentissage multimodal en sélectionnant conjointement les meilleurs lots de données au lieu d'échantillons individuels.
?️ **Méthode de formation innovante** : JEST utilise l'approximation de modèles en ligne et des conseils sur les ensembles de données de haute qualité pour optimiser la distribution des données et les capacités de généralisation des modèles de pré-formation à grande échelle.
L'émergence de la méthode JEST a apporté un nouvel espoir à la formation en IA, et sa stratégie efficace de criblage des données devrait promouvoir l'application et le développement de la technologie de l'IA dans divers domaines. À l’avenir, nous sommes impatients de voir les performances de JEST dans des applications plus pratiques et de promouvoir davantage de percées dans le domaine de l’intelligence artificielle. L'éditeur de Downcodes continuera de prêter attention aux développements pertinents et de proposer des rapports plus intéressants aux lecteurs.