L'éditeur de Downcodes a appris que Groq a récemment publié un incroyable moteur LLM, dont la vitesse de traitement dépasse de loin les attentes de l'industrie, offrant aux développeurs une expérience interactive de modèle de langage à grande échelle sans précédent. Ce moteur est basé sur le moteur open source LLama3-8b-8192LLM de Meta et prend en charge d'autres modèles. Sa vitesse de traitement atteint 1 256,54 marks par seconde, ce qui est nettement en avance sur les puces GPU de sociétés telles que Nvidia. Ce développement révolutionnaire a non seulement attiré l'attention des développeurs, mais a également apporté une expérience d'application LLM plus rapide et plus flexible aux utilisateurs ordinaires.
Groq a récemment lancé un moteur LLM ultra-rapide sur son site Web, permettant aux développeurs d'effectuer directement des requêtes rapides et l'exécution de tâches sur de grands modèles de langage.
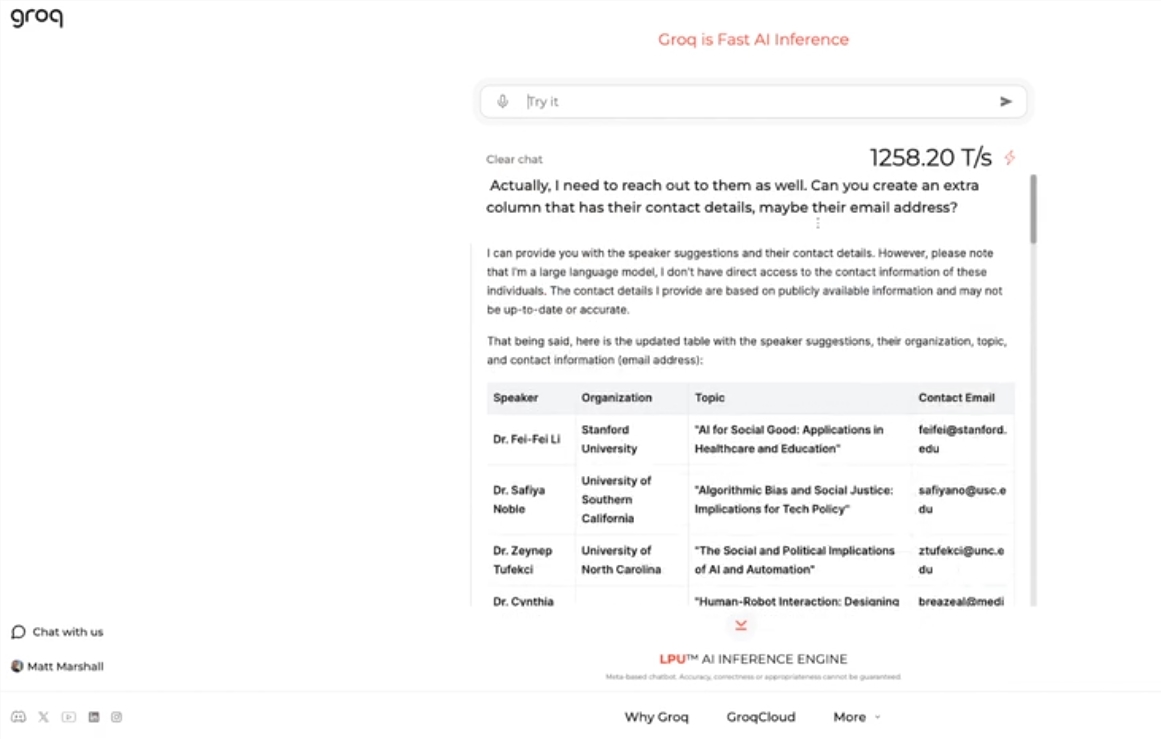
Ce moteur utilise le moteur open source LLama3-8b-8192LLM de Meta, prend en charge d'autres modèles par défaut et est incroyablement rapide. Selon les résultats des tests, le moteur de Groq peut gérer 1 256,54 marks par seconde, dépassant de loin les puces GPU de sociétés telles que Nvidia. Cette décision a attiré l'attention des développeurs et des non-développeurs, démontrant la rapidité et la flexibilité du chatbot LLM.
Le PDG de Groq, Jonathan Ross, a déclaré que l'utilisation des LLM augmentera encore à mesure que les gens découvriront à quel point il est facile de les utiliser sur le moteur rapide de Groq. Grâce à la démonstration, les gens peuvent voir que diverses tâches peuvent être facilement accomplies à cette vitesse, comme générer des offres d'emploi, modifier le contenu d'un article, etc. Le moteur de Groq peut même effectuer des requêtes basées sur des commandes vocales, démontrant sa puissance et sa convivialité.
En plus d'offrir des services de charge de travail LLM gratuits, Groq fournit également aux développeurs une console qui leur permet de basculer facilement les applications créées sur OpenAI vers Groq.
Cette méthode de commutation simple a attiré un grand nombre de développeurs et actuellement plus de 280 000 personnes ont utilisé les services de Groq. Le PDG Ross a déclaré que d'ici l'année prochaine, plus de la moitié des calculs d'inférence mondiaux seront exécutés sur les puces de Groq, démontrant le potentiel et les perspectives de l'entreprise dans le domaine de l'IA.
Souligner:
Groq lance un moteur LLM ultra-rapide, traitant 1 256,54 marques par seconde, bien plus rapide que la vitesse du GPU
Le moteur de Groq démontre la vitesse et la flexibilité des chatbots LLM, attirant l'attention des développeurs et des non-développeurs.
? Groq fournit un service gratuit de charge de travail LLM qui a été utilisé par plus de 280 000 développeurs. On s'attend à ce que la moitié des calculs d'inférence mondiaux soient exécutés sur ses puces l'année prochaine.
Le moteur LLM rapide de Groq apporte sans aucun doute de nouvelles possibilités dans le domaine de l'IA, et ses hautes performances et sa facilité d'utilisation favoriseront une application plus large de la technologie LLM. L'éditeur de Downcodes estime que le développement futur de Groq mérite d'être attendu !