Ces dernières années, le développement rapide de la technologie de l’intelligence artificielle repose largement sur la formation de données massives. Cependant, l'éditeur de Downcodes a constaté que les dernières recherches du MIT et d'autres institutions ont souligné que la difficulté d'obtenir des données augmente considérablement. Les données réseau qui étaient autrefois facilement accessibles sont désormais soumises à des restrictions de plus en plus strictes, ce qui pose d'énormes défis à la formation et au développement de l'IA. L’étude, qui a analysé plusieurs ensembles de données open source, révèle cette dure réalité.
Derrière le développement rapide de l’intelligence artificielle, un problème sérieux fait surface : la difficulté d’acquisition des données augmente. Les dernières recherches du MIT et d'autres institutions ont révélé que les données Web qui étaient autrefois facilement accessibles deviennent désormais de plus en plus difficiles d'accès, ce qui pose un défi majeur à la formation et à la recherche en IA.
Les chercheurs ont découvert que les sites Web explorés par plusieurs ensembles de données open source tels que C4, RefineWeb, Dolma, etc. resserrent rapidement leurs accords de licence. Cela affecte non seulement la formation de modèles commerciaux d’IA, mais entrave également la recherche menée par des organisations universitaires et à but non lucratif.

Cette recherche a été menée par quatre chefs d’équipe du MIT Media Lab, du Wellesley College, de la startup d’IA Raive et d’autres institutions. Ils notent que les restrictions en matière de données se multiplient et que les asymétries et incohérences en matière de licences deviennent de plus en plus apparentes.
L’équipe de recherche a utilisé le protocole d’exclusion des robots (REP) et les conditions d’utilisation (ToS) du site Web comme méthodes de recherche. Ils ont constaté que même les robots d’exploration des grandes sociétés d’IA comme OpenAI étaient confrontés à des restrictions de plus en plus strictes.
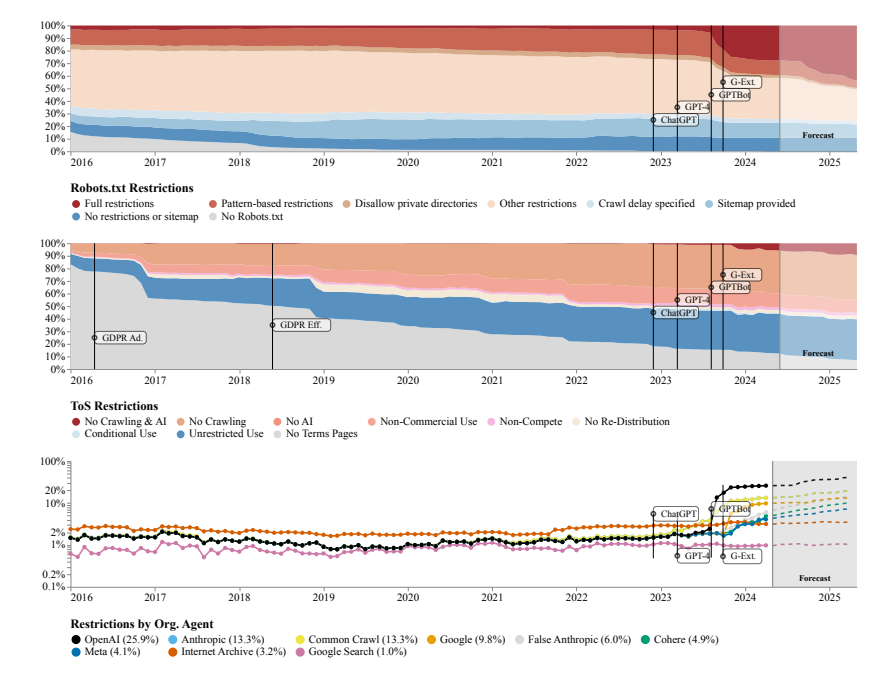
Le modèle SARIMA prédit qu'à l'avenir, que ce soit via robots.txt ou ToS, les restrictions sur les données des sites Web continueront d'augmenter. Cela suggère que l’accès aux données des réseaux ouverts deviendra plus difficile.
L'étude a également révélé que les données extraites d'Internet ne correspondent pas à l'objectif de formation du modèle d'IA, ce qui peut avoir un impact sur l'alignement du modèle, les pratiques de collecte de données et les droits d'auteur.
L'équipe de recherche appelle à la nécessité d'accords plus flexibles qui reflètent les souhaits des propriétaires de sites Web, séparent les cas d'utilisation autorisés et non autorisés et se synchronisent avec les conditions de service. Dans le même temps, ils souhaitent que les développeurs d’IA puissent utiliser les données du Web ouvert à des fins de formation, et espèrent que les futures lois soutiendront cela.
Adresse papier : https://www.dataprovenance.org/Consent_in_Crisis.pdf
Ces recherches ont tiré la sonnette d'alarme sur le problème de l'acquisition de données dans le domaine de l'intelligence artificielle et ont également soulevé de nouveaux défis pour la formation et le développement des futurs modèles d'IA. Comment équilibrer l’acquisition de données et les droits et intérêts des propriétaires de sites Web deviendra une question clé qui devra être sérieusement prise en compte et résolue dans le domaine de l’intelligence artificielle. L'éditeur de Downcodes recommande de prêter attention au document pour en savoir plus.